 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do People Quantify Naturally: Evidence from Mandarin Picture Description
Feb 10, 2026Quantification is a fundamental component of everyday language use, yet little is known about how speakers decide whether and how to quantify in naturalistic production. We investigate quantification in Mandarin Chinese using a picture-based elicited description task in which speakers freely described scenes containing multiple objects, without explicit instructions to count or quantify. Across both spoken and written modalities, we examine three aspects of quantification: whether speakers choose to quantify at all, how precise their quantification is, and which quantificational strategies they adopt. Results show that object numerosity, animacy, and production modality systematically shape quantificational behaviour. In particular, increasing numerosity reduces both the likelihood and the precision of quantification, while animate referents and modality selectively modulate strategy choice. This study demonstrates how quantification can be examined under unconstrained production conditions and provides a naturalistic dataset for further analyses of quantity expression in language production.
Discovering Hidden Visual Concepts Beyond Linguistic Input in Infant Learning
Jan 09, 2025Infants develop complex visual understanding rapidly, even preceding of the acquisition of linguistic inputs. As computer vision seeks to replicate the human vision system, understanding infant visual development may offer valuable insights. In this paper, we present an interdisciplinary study exploring this question: can a computational model that imitates the infant learning process develop broader visual concepts that extend beyond the vocabulary it has heard, similar to how infants naturally learn? To investigate this, we analyze a recently published model in Science by Vong et al.,which is trained on longitudinal, egocentric images of a single child paired with transcribed parental speech. We introduce a training-free framework that can discover visual concept neurons hidden in the model's internal representations. Our findings show that these neurons can classify objects outside its original vocabulary. Furthermore, we compare the visual representations in infant-like models with those in moder computer vision models, such as CLIP or ImageNet pre-trained model, highlighting key similarities and differences. Ultimately, our work bridges cognitive science and computer vision by analyzing the internal representations of a computational model trained on an infant's visual and linguistic inputs.
Action Recognition based on Cross-Situational Action-object Statistics
Aug 15, 2022

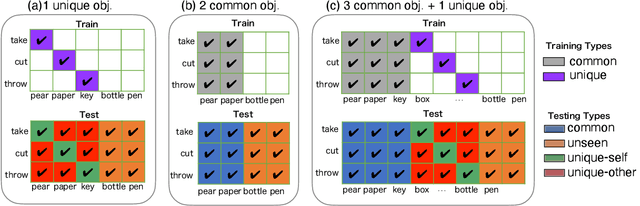
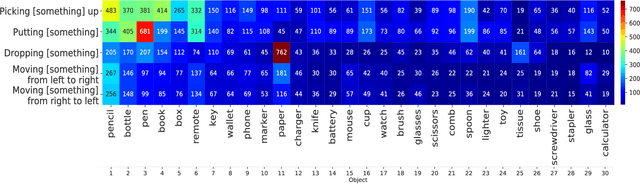
Machine learning models of visual action recognition are typically trained and tested on data from specific situations where actions are associated with certain objects. It is an open question how action-object associations in the training set influence a model's ability to generalize beyond trained situations. We set out to identify properties of training data that lead to action recognition models with greater generalization ability. To do this, we take inspiration from a cognitive mechanism called cross-situational learning, which states that human learners extract the meaning of concepts by observing instances of the same concept across different situations. We perform controlled experiments with various types of action-object associations, and identify key properties of action-object co-occurrence in training data that lead to better classifiers. Given that these properties are missing in the datasets that are typically used to train action classifiers in the computer vision literature, our work provides useful insights on how we should best construct datasets for efficiently training for better generalization.