 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShall We Trust All Relational Tuples by Open Information Extraction? A Study on Speculation Detection
May 07, 2023


Open Information Extraction (OIE) aims to extract factual relational tuples from open-domain sentences. Downstream tasks use the extracted OIE tuples as facts, without examining the certainty of these facts. However, uncertainty/speculation is a common linguistic phenomenon. Existing studies on speculation detection are defined at sentence level, but even if a sentence is determined to be speculative, not all tuples extracted from it may be speculative. In this paper, we propose to study speculations in OIE and aim to determine whether an extracted tuple is speculative. We formally define the research problem of tuple-level speculation detection and conduct a detailed data analysis on the LSOIE dataset which contains labels for speculative tuples. Lastly, we propose a baseline model OIE-Spec for this new research task.
Open Information Extraction via Chunks
May 05, 2023Open Information Extraction (OIE) aims to extract relational tuples from open-domain sentences. Existing OIE systems split a sentence into tokens and recognize token spans as tuple relations and arguments. We instead propose Sentence as Chunk sequence (SaC) and recognize chunk spans as tuple relations and arguments. We argue that SaC has better quantitative and qualitative properties for OIE than sentence as token sequence, and evaluate four choices of chunks (i.e., CoNLL chunks, simple phrases, NP chunks, and spans from SpanOIE) against gold OIE tuples. Accordingly, we propose a simple BERT-based model for sentence chunking, and propose Chunk-OIE for tuple extraction on top of SaC. Chunk-OIE achieves state-of-the-art results on multiple OIE datasets, showing that SaC benefits OIE task.
Syntactic Multi-view Learning for Open Information Extraction
Dec 05, 2022
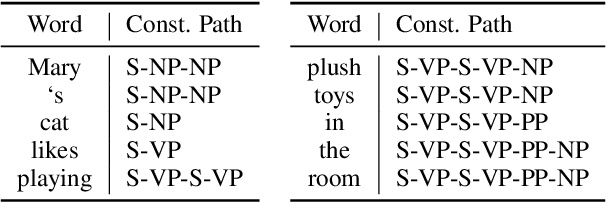

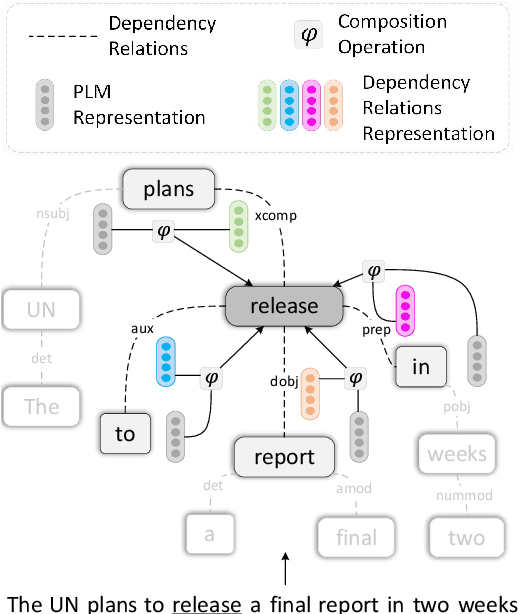
Open Information Extraction (OpenIE) aims to extract relational tuples from open-domain sentences. Traditional rule-based or statistical models have been developed based on syntactic structures of sentences, identified by syntactic parsers. However, previous neural OpenIE models under-explore the useful syntactic information. In this paper, we model both constituency and dependency trees into word-level graphs, and enable neural OpenIE to learn from the syntactic structures. To better fuse heterogeneous information from both graphs, we adopt multi-view learning to capture multiple relationships from them. Finally, the finetuned constituency and dependency representations are aggregated with sentential semantic representations for tuple generation. Experiments show that both constituency and dependency information, and the multi-view learning are effective.
* To appear in EMNLP 2022
Pure Transformer with Integrated Experts for Scene Text Recognition
Nov 09, 2022Scene text recognition (STR) involves the task of reading text in cropped images of natural scenes. Conventional models in STR employ convolutional neural network (CNN) followed by recurrent neural network in an encoder-decoder framework. In recent times, the transformer architecture is being widely adopted in STR as it shows strong capability in capturing long-term dependency which appears to be prominent in scene text images. Many researchers utilized transformer as part of a hybrid CNN-transformer encoder, often followed by a transformer decoder. However, such methods only make use of the long-term dependency mid-way through the encoding process. Although the vision transformer (ViT) is able to capture such dependency at an early stage, its utilization remains largely unexploited in STR. This work proposes the use of a transformer-only model as a simple baseline which outperforms hybrid CNN-transformer models. Furthermore, two key areas for improvement were identified. Firstly, the first decoded character has the lowest prediction accuracy. Secondly, images of different original aspect ratios react differently to the patch resolutions while ViT only employ one fixed patch resolution. To explore these areas, Pure Transformer with Integrated Experts (PTIE) is proposed. PTIE is a transformer model that can process multiple patch resolutions and decode in both the original and reverse character orders. It is examined on 7 commonly used benchmarks and compared with over 20 state-of-the-art methods. The experimental results show that the proposed method outperforms them and obtains state-of-the-art results in most benchmarks.
Portmanteauing Features for Scene Text Recognition
Nov 09, 2022



Scene text images have different shapes and are subjected to various distortions, e.g. perspective distortions. To handle these challenges, the state-of-the-art methods rely on a rectification network, which is connected to the text recognition network. They form a linear pipeline which uses text rectification on all input images, even for images that can be recognized without it. Undoubtedly, the rectification network improves the overall text recognition performance. However, in some cases, the rectification network generates unnecessary distortions on images, resulting in incorrect predictions in images that would have otherwise been correct without it. In order to alleviate the unnecessary distortions, the portmanteauing of features is proposed. The portmanteau feature, inspired by the portmanteau word, is a feature containing information from both the original text image and the rectified image. To generate the portmanteau feature, a non-linear input pipeline with a block matrix initialization is presented. In this work, the transformer is chosen as the recognition network due to its utilization of attention and inherent parallelism, which can effectively handle the portmanteau feature. The proposed method is examined on 6 benchmarks and compared with 13 state-of-the-art methods. The experimental results show that the proposed method outperforms the state-of-the-art methods on various of the benchmarks.
DocOIE: A Document-level Context-Aware Dataset for OpenIE
May 11, 2021
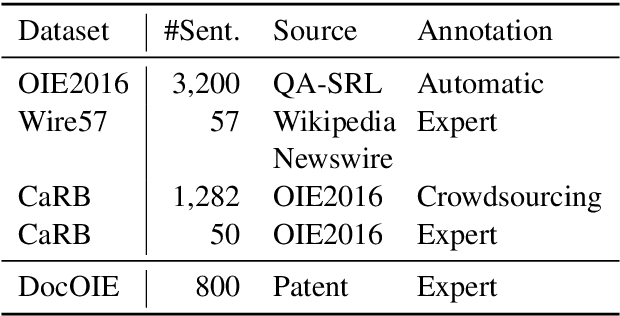


Open Information Extraction (OpenIE) aims to extract structured relational tuples (subject, relation, object) from sentences and plays critical roles for many downstream NLP applications. Existing solutions perform extraction at sentence level, without referring to any additional contextual information. In reality, however, a sentence typically exists as part of a document rather than standalone; we often need to access relevant contextual information around the sentence before we can accurately interpret it. As there is no document-level context-aware OpenIE dataset available, we manually annotate 800 sentences from 80 documents in two domains (Healthcare and Transportation) to form a DocOIE dataset for evaluation. In addition, we propose DocIE, a novel document-level context-aware OpenIE model. Our experimental results based on DocIE demonstrate that incorporating document-level context is helpful in improving OpenIE performance. Both DocOIE dataset and DocIE model are released for public.