 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocOIE: A Document-level Context-Aware Dataset for OpenIE
Paper and Code

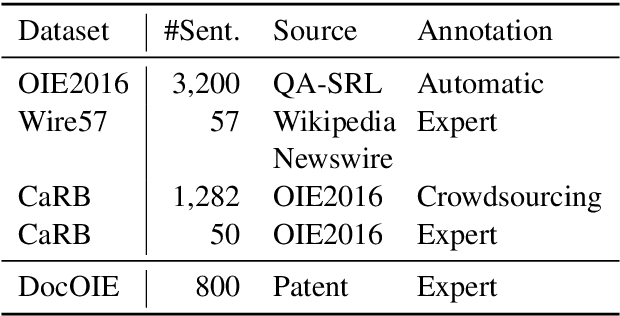


Open Information Extraction (OpenIE) aims to extract structured relational tuples (subject, relation, object) from sentences and plays critical roles for many downstream NLP applications. Existing solutions perform extraction at sentence level, without referring to any additional contextual information. In reality, however, a sentence typically exists as part of a document rather than standalone; we often need to access relevant contextual information around the sentence before we can accurately interpret it. As there is no document-level context-aware OpenIE dataset available, we manually annotate 800 sentences from 80 documents in two domains (Healthcare and Transportation) to form a DocOIE dataset for evaluation. In addition, we propose DocIE, a novel document-level context-aware OpenIE model. Our experimental results based on DocIE demonstrate that incorporating document-level context is helpful in improving OpenIE performance. Both DocOIE dataset and DocIE model are released for public.