 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Hard Negatives Hurt: Bridging the Generative-Discriminative Gap in Hard Negative Synthesis for Retrieval
May 31, 2026Hard negative mining has become the dominant strategy for training retrievers, yet it faces intrinsic limitations: negatives are bounded by corpus availability, selected by retriever score rather than diagnostic value, and increasingly contaminated by false positives as the retriever improves. LLM-based synthesis offers a principled alternative, where negatives that are unconstrained, targeted, and free from false positive risk. But we show that naively incorporating generated negatives into contrastive learning often degrades retrieval performance. We identify and formalize the root cause as a generative-discriminative gap: LLM generation optimizes for fluent, plausible text, while contrastive learning demands strategic violations of relevance at the decision boundary. Our analysis reveals two compounding failure modes: discriminative-agnostic generation, where the LLM lacks an explicit model of query information needs and defaults to generic or topic-drifted text that provides no contrastive signal; and source-dependent shortcuts, where distributional artifacts enable the model to distinguish negatives by origin rather than relevance, causing gradient drift that actively corrupts optimization. To close this gap, we propose CausalNeg consisting of two main modules: (1) CoT-guided counterfactual perturbation for data construction: decomposes why a document satisfies a query into explicit information requirements, then surgically violates individual requirements to construct negatives with controlled, interpretable hardness. (2) Query-view entropy maximization during training: disperses generated negatives across the similarity spectrum, minimizing the mutual information between source identity and similarity scores to suppress shortcut exploitation. We make our code publicly available at https://github.com/mzhangzhicheng/CausalNeg.
Learning More from Less: Exploiting Counterfactuals for Data-Efficient Chart Understanding
May 11, 2026Vision-Language Models (VLMs) have demonstrated remarkable progress in chart understanding, largely driven by supervised fine-tuning (SFT) on increasingly large synthetic datasets. However, scaling SFT data alone is inefficient and overlooks a key property of charts: charts are programmatically generated visual artifacts, where small, code-controlled visual changes can induce drastic shifts in semantics and correct answers. Learning this counterfactual sensitivity requires VLMs to discriminate fine-grained visual differences, yet standard SFT treats training instances independently and provides limited supervision to enforce this behavior. To address this, we introduce ChartCF, a data-efficient training framework designed to enhance counterfactual sensitivity. ChartCF consists of: (1) a counterfactual data synthesis pipeline via code modification, (2) a chart similarity-based data selection strategy that filters overly difficult samples for improved training efficiency, and (3) multimodal preference optimization across both textual and visual modalities. Experiments on five benchmarks show that ChartCF achieves superior or comparable performance to strong chart-specific VLMs while using significantly less training data.
SRR-Judge: Step-Level Rating and Refinement for Enhancing Search-Integrated Reasoning in Search Agents
Feb 08, 2026Recent deep search agents built on large reasoning models (LRMs) excel at complex question answering by iteratively planning, acting, and gathering evidence, a capability known as search-integrated reasoning. However, mainstream approaches often train this ability using only outcome-based supervision, neglecting the quality of intermediate thoughts and actions. We introduce SRR-Judge, a framework for reliable step-level assessment of reasoning and search actions. Integrated into a modified ReAct-style rate-and-refine workflow, SRR-Judge provides fine-grained guidance for search-integrated reasoning and enables efficient post-training annotation. Using SRR-annotated data, we apply an iterative rejection sampling fine-tuning procedure to enhance the deep search capability of the base agent. Empirically, SRR-Judge delivers more reliable step-level evaluations than much larger models such as DeepSeek-V3.1, with its ratings showing strong correlation with final answer correctness. Moreover, aligning the policy with SRR-Judge annotated trajectories leads to substantial performance gains, yielding over a 10 percent average absolute pass@1 improvement across challenging deep search benchmarks.
To Search or Not to Search: Aligning the Decision Boundary of Deep Search Agents via Causal Intervention
Feb 03, 2026Deep search agents, which autonomously iterate through multi-turn web-based reasoning, represent a promising paradigm for complex information-seeking tasks. However, current agents suffer from critical inefficiency: they conduct excessive searches as they cannot accurately judge when to stop searching and start answering. This stems from outcome-centric training that prioritize final results over the search process itself. We identify the root cause as misaligned decision boundaries, the threshold determining when accumulated information suffices to answer. This causes over-search (redundant searching despite sufficient knowledge) and under-search (premature termination yielding incorrect answers). To address these errors, we propose a comprehensive framework comprising two key components. First, we introduce causal intervention-based diagnosis that identifies boundary errors by comparing factual and counterfactual trajectories at each decision point. Second, we develop Decision Boundary Alignment for Deep Search agents (DAS), which constructs preference datasets from causal feedback and aligns policies via preference optimization. Experiments on public datasets demonstrate that decision boundary errors are pervasive across state-of-the-art agents. Our DAS method effectively calibrates these boundaries, mitigating both over-search and under-search to achieve substantial gains in accuracy and efficiency. Our code and data are publicly available at: https://github.com/Applied-Machine-Learning-Lab/WWW2026_DAS.
Exploring Recommender System Evaluation: A Multi-Modal User Agent Framework for A/B Testing
Jan 08, 2026In recommender systems, online A/B testing is a crucial method for evaluating the performance of different models. However, conducting online A/B testing often presents significant challenges, including substantial economic costs, user experience degradation, and considerable time requirements. With the Large Language Models' powerful capacity, LLM-based agent shows great potential to replace traditional online A/B testing. Nonetheless, current agents fail to simulate the perception process and interaction patterns, due to the lack of real environments and visual perception capability. To address these challenges, we introduce a multi-modal user agent for A/B testing (A/B Agent). Specifically, we construct a recommendation sandbox environment for A/B testing, enabling multimodal and multi-page interactions that align with real user behavior on online platforms. The designed agent leverages multimodal information perception, fine-grained user preferences, and integrates profiles, action memory retrieval, and a fatigue system to simulate complex human decision-making. We validated the potential of the agent as an alternative to traditional A/B testing from three perspectives: model, data, and features. Furthermore, we found that the data generated by A/B Agent can effectively enhance the capabilities of recommendation models. Our code is publicly available at https://github.com/Applied-Machine-Learning-Lab/ABAgent.
Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research
Oct 24, 2025Deep Research systems have revolutionized how LLMs solve complex questions through iterative reasoning and evidence gathering. However, current systems remain fundamentally constrained to textual web data, overlooking the vast knowledge embedded in multimodal documents Processing such documents demands sophisticated parsing to preserve visual semantics (figures, tables, charts, and equations), intelligent chunking to maintain structural coherence, and adaptive retrieval across modalities, which are capabilities absent in existing systems. In response, we present Doc-Researcher, a unified system that bridges this gap through three integrated components: (i) deep multimodal parsing that preserves layout structure and visual semantics while creating multi-granular representations from chunk to document level, (ii) systematic retrieval architecture supporting text-only, vision-only, and hybrid paradigms with dynamic granularity selection, and (iii) iterative multi-agent workflows that decompose complex queries, progressively accumulate evidence, and synthesize comprehensive answers across documents and modalities. To enable rigorous evaluation, we introduce M4DocBench, the first benchmark for Multi-modal, Multi-hop, Multi-document, and Multi-turn deep research. Featuring 158 expert-annotated questions with complete evidence chains across 304 documents, M4DocBench tests capabilities that existing benchmarks cannot assess. Experiments demonstrate that Doc-Researcher achieves 50.6% accuracy, 3.4xbetter than state-of-the-art baselines, validating that effective document research requires not just better retrieval, but fundamentally deep parsing that preserve multimodal integrity and support iterative research. Our work establishes a new paradigm for conducting deep research on multimodal document collections.
Humanity's Last Code Exam: Can Advanced LLMs Conquer Human's Hardest Code Competition?
Jun 15, 2025Code generation is a core capability of large language models (LLMs), yet mainstream benchmarks (e.g., APPs and LiveCodeBench) contain questions with medium-level difficulty and pose no challenge to advanced LLMs. To better reflected the advanced reasoning and code generation ability, We introduce Humanity's Last Code Exam (HLCE), comprising 235 most challenging problems from the International Collegiate Programming Contest (ICPC World Finals) and the International Olympiad in Informatics (IOI) spanning 2010 - 2024. As part of HLCE, we design a harmonized online-offline sandbox that guarantees fully reproducible evaluation. Through our comprehensive evaluation, we observe that even the strongest reasoning LLMs: o4-mini(high) and Gemini-2.5 Pro, achieve pass@1 rates of only 15.9% and 11.4%, respectively. Meanwhile, we propose a novel "self-recognition" task to measure LLMs' awareness of their own capabilities. Results indicate that LLMs' self-recognition abilities are not proportionally correlated with their code generation performance. Finally, our empirical validation of test-time scaling laws reveals that current advanced LLMs have substantial room for improvement on complex programming tasks. We expect HLCE to become a milestone challenge for code generation and to catalyze advances in high-performance reasoning and human-AI collaborative programming. Our code and dataset are also public available(https://github.com/Humanity-s-Last-Code-Exam/HLCE).
Benchmarking Retrieval-Augmented Multimomal Generation for Document Question Answering
May 22, 2025
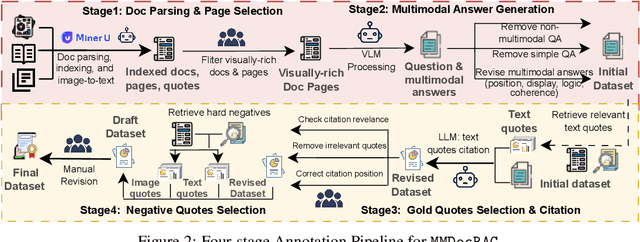
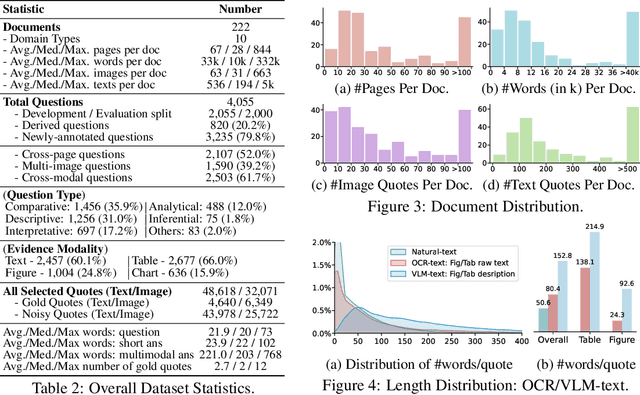
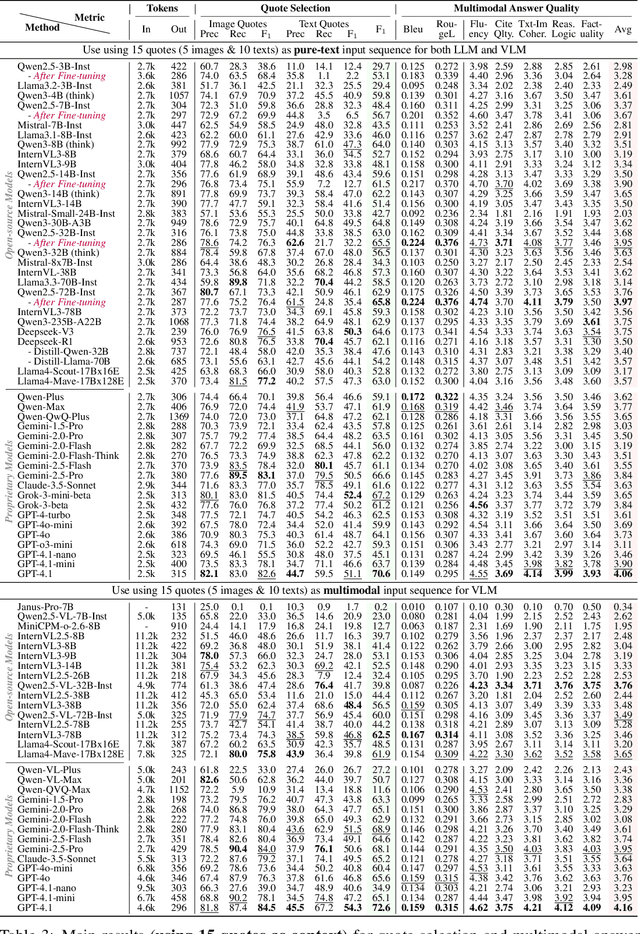
Document Visual Question Answering (DocVQA) faces dual challenges in processing lengthy multimodal documents (text, images, tables) and performing cross-modal reasoning. Current document retrieval-augmented generation (DocRAG) methods remain limited by their text-centric approaches, frequently missing critical visual information. The field also lacks robust benchmarks for assessing multimodal evidence selection and integration. We introduce MMDocRAG, a comprehensive benchmark featuring 4,055 expert-annotated QA pairs with multi-page, cross-modal evidence chains. Our framework introduces innovative metrics for evaluating multimodal quote selection and enables answers that interleave text with relevant visual elements. Through large-scale experiments with 60 VLM/LLM models and 14 retrieval systems, we identify persistent challenges in multimodal evidence retrieval, selection, and integration.Key findings reveal advanced proprietary LVMs show superior performance than open-sourced alternatives. Also, they show moderate advantages using multimodal inputs over text-only inputs, while open-source alternatives show significant performance degradation. Notably, fine-tuned LLMs achieve substantial improvements when using detailed image descriptions. MMDocRAG establishes a rigorous testing ground and provides actionable insights for developing more robust multimodal DocVQA systems. Our benchmark and code are available at https://mmdocrag.github.io/MMDocRAG/.
Process vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning
May 20, 2025Retrieval-augmented generation (RAG) enhances the text generation capabilities of large language models (LLMs) by integrating external knowledge and up-to-date information. However, traditional RAG systems are limited by static workflows and lack the adaptability required for multistep reasoning and complex task management. To address these limitations, agentic RAG systems (e.g., DeepResearch) have been proposed, enabling dynamic retrieval strategies, iterative context refinement, and adaptive workflows for handling complex search queries beyond the capabilities of conventional RAG. Recent advances, such as Search-R1, have demonstrated promising gains using outcome-based reinforcement learning, where the correctness of the final answer serves as the reward signal. Nevertheless, such outcome-supervised agentic RAG methods face challenges including low exploration efficiency, gradient conflict, and sparse reward signals. To overcome these challenges, we propose to utilize fine-grained, process-level rewards to improve training stability, reduce computational costs, and enhance efficiency. Specifically, we introduce a novel method ReasonRAG that automatically constructs RAG-ProGuide, a high-quality dataset providing process-level rewards for (i) query generation, (ii) evidence extraction, and (iii) answer generation, thereby enhancing model inherent capabilities via process-supervised reinforcement learning. With the process-level policy optimization, the proposed framework empowers LLMs to autonomously invoke search, generate queries, extract relevant evidence, and produce final answers. Compared to existing approaches such as Search-R1 and traditional RAG systems, ReasonRAG, leveraging RAG-ProGuide, achieves superior performance on five benchmark datasets using only 5k training instances, significantly fewer than the 90k training instances required by Search-R1.
Adaptive Tool Use in Large Language Models with Meta-Cognition Trigger
Feb 18, 2025



Large language models (LLMs) have shown remarkable emergent capabilities, transforming the execution of functional tasks by leveraging external tools for complex problems that require specialized processing or real-time data. While existing research expands LLMs access to diverse tools (e.g., program interpreters, search engines, weather/map apps), the necessity of using these tools is often overlooked, leading to indiscriminate tool invocation. This naive approach raises two key issues:(1) increased delays due to unnecessary tool calls, and (2) potential errors resulting from faulty interactions with external tools. In this paper, we introduce meta-cognition as a proxy for LLMs self-assessment of their capabilities, representing the model's awareness of its own limitations. Based on this, we propose MeCo, an adaptive decision-making strategy for external tool use. MeCo quantifies metacognitive scores by capturing high-level cognitive signals in the representation space, guiding when to invoke tools. Notably, MeCo is fine-tuning-free and incurs minimal cost. Our experiments show that MeCo accurately detects LLMs' internal cognitive signals and significantly improves tool-use decision-making across multiple base models and benchmarks.