 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Content-aware Indexing for Long Document Retrieval
Paper and Code
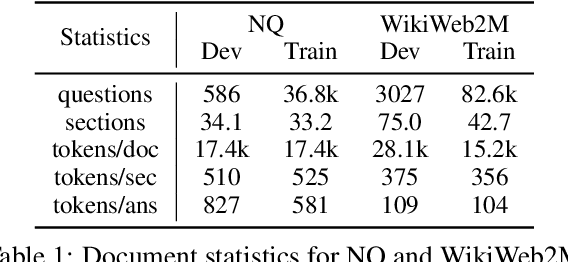
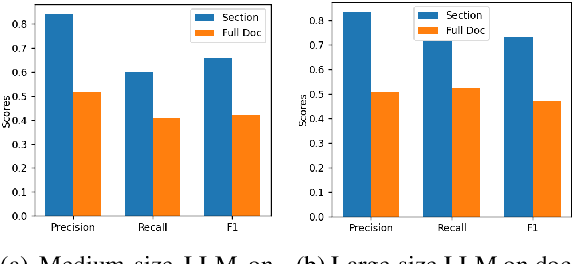
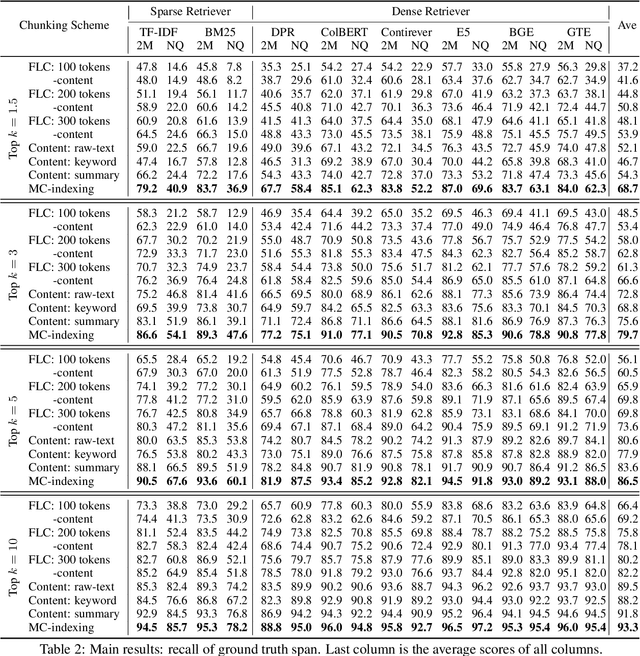
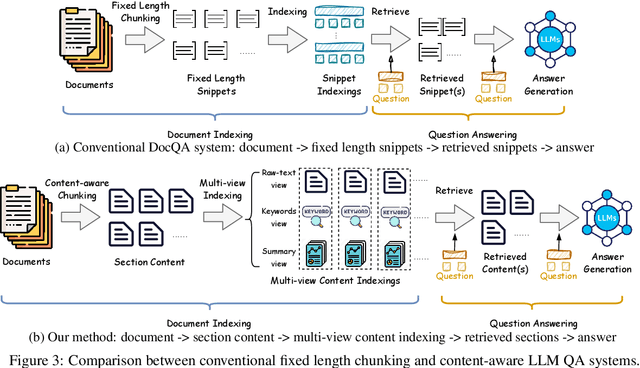
Long document question answering (DocQA) aims to answer questions from long documents over 10k words. They usually contain content structures such as sections, sub-sections, and paragraph demarcations. However, the indexing methods of long documents remain under-explored, while existing systems generally employ fixed-length chunking. As they do not consider content structures, the resultant chunks can exclude vital information or include irrelevant content. Motivated by this, we propose the Multi-view Content-aware indexing (MC-indexing) for more effective long DocQA via (i) segment structured document into content chunks, and (ii) represent each content chunk in raw-text, keywords, and summary views. We highlight that MC-indexing requires neither training nor fine-tuning. Having plug-and-play capability, it can be seamlessly integrated with any retrievers to boost their performance. Besides, we propose a long DocQA dataset that includes not only question-answer pair, but also document structure and answer scope. When compared to state-of-art chunking schemes, MC-indexing has significantly increased the recall by 42.8%, 30.0%, 23.9%, and 16.3% via top k= 1.5, 3, 5, and 10 respectively. These improved scores are the average of 8 widely used retrievers (2 sparse and 6 dense) via extensive experiments.