 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombined CNN Transformer Encoder for Enhanced Fine-grained Human Action Recognition
Paper and Code
Aug 03, 2022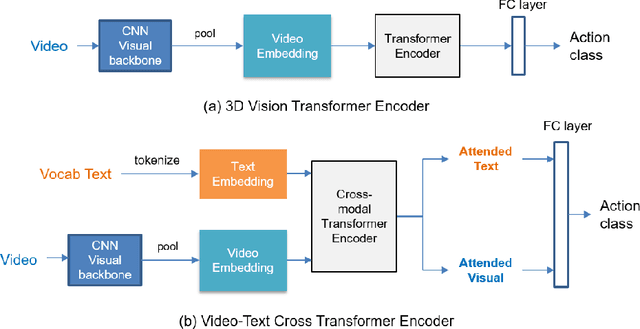

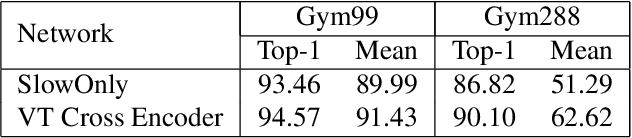
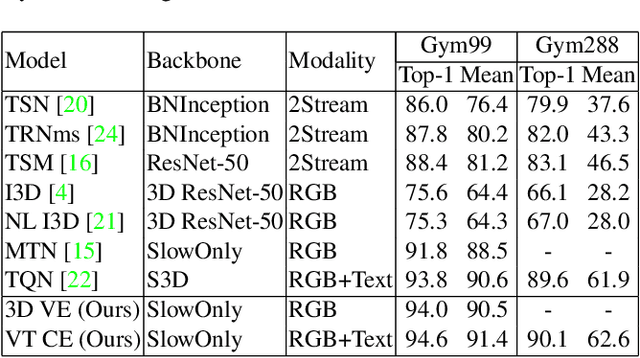
Fine-grained action recognition is a challenging task in computer vision. As fine-grained datasets have small inter-class variations in spatial and temporal space, fine-grained action recognition model requires good temporal reasoning and discrimination of attribute action semantics. Leveraging on CNN's ability in capturing high level spatial-temporal feature representations and Transformer's modeling efficiency in capturing latent semantics and global dependencies, we investigate two frameworks that combine CNN vision backbone and Transformer Encoder to enhance fine-grained action recognition: 1) a vision-based encoder to learn latent temporal semantics, and 2) a multi-modal video-text cross encoder to exploit additional text input and learn cross association between visual and text semantics. Our experimental results show that both our Transformer encoder frameworks effectively learn latent temporal semantics and cross-modality association, with improved recognition performance over CNN vision model. We achieve new state-of-the-art performance on the FineGym benchmark dataset for both proposed architectures.