 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximize the Exploration of Congeneric Semantics for Weakly Supervised Semantic Segmentation
Paper and Code
Oct 08, 2021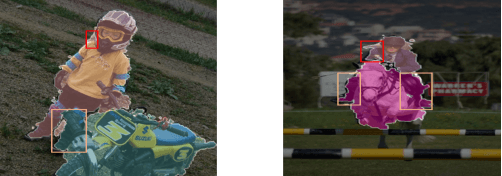

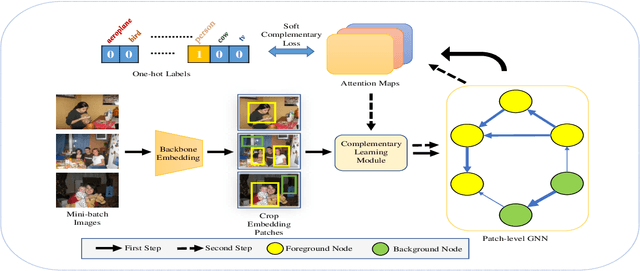
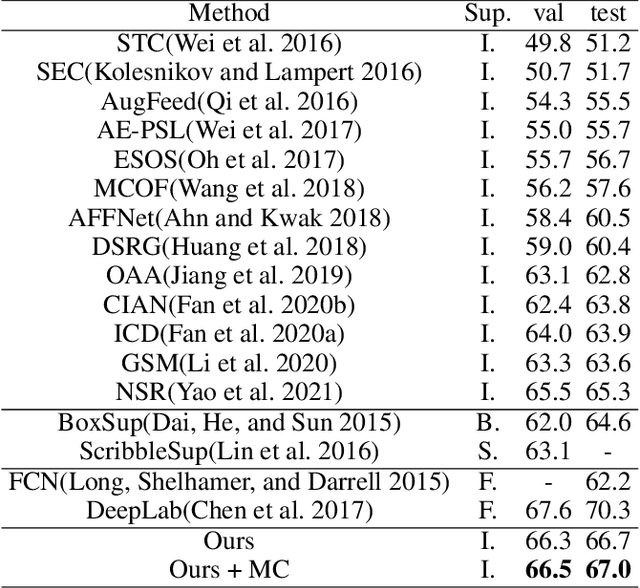
With the increase in the number of image data and the lack of corresponding labels, weakly supervised learning has drawn a lot of attention recently in computer vision tasks, especially in the fine-grained semantic segmentation problem. To alleviate human efforts from expensive pixel-by-pixel annotations, our method focuses on weakly supervised semantic segmentation (WSSS) with image-level tags, which are much easier to obtain. As a huge gap exists between pixel-level segmentation and image-level labels, how to reflect the image-level semantic information on each pixel is an important question. To explore the congeneric semantic regions from the same class to the maximum, we construct the patch-level graph neural network (P-GNN) based on the self-detected patches from different images that contain the same class labels. Patches can frame the objects as much as possible and include as little background as possible. The graph network that is established with patches as the nodes can maximize the mutual learning of similar objects. We regard the embedding vectors of patches as nodes, and use transformer-based complementary learning module to construct weighted edges according to the embedding similarity between different nodes. Moreover, to better supplement semantic information, we propose soft-complementary loss functions matched with the whole network structure. We conduct experiments on the popular PASCAL VOC 2012 benchmarks, and our model yields state-of-the-art performance.