 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecouple Event Field via Probabilistic Bias for Event Extraction
May 19, 2023
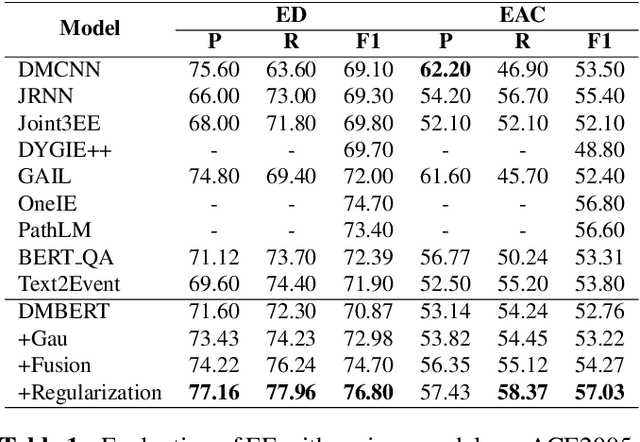
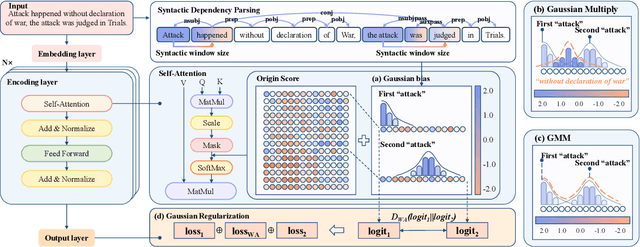
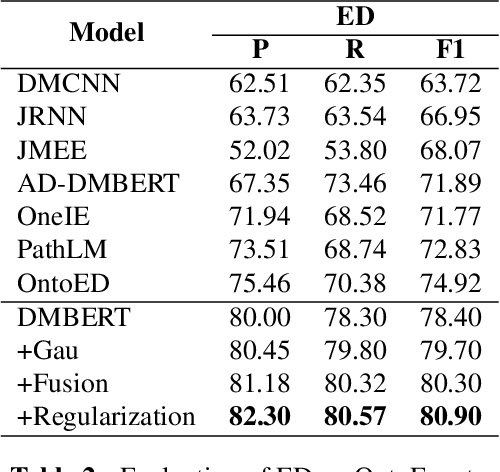
Event Extraction (EE), aiming to identify and classify event triggers and arguments from event mentions, has benefited from pre-trained language models (PLMs). However, existing PLM-based methods ignore the information of trigger/argument fields, which is crucial for understanding event schemas. To this end, we propose a Probabilistic reCoupling model enhanced Event extraction framework (ProCE). Specifically, we first model the syntactic-related event fields as probabilistic biases, to clarify the event fields from ambiguous entanglement. Furthermore, considering multiple occurrences of the same triggers/arguments in EE, we explore probabilistic interaction strategies among multiple fields of the same triggers/arguments, to recouple the corresponding clarified distributions and capture more latent information fields. Experiments on EE datasets demonstrate the effectiveness and generalization of our proposed approach.
Edge-free but Structure-aware: Prototype-Guided Knowledge Distillation from GNNs to MLPs
Mar 27, 2023Distilling high-accuracy Graph Neural Networks~(GNNs) to low-latency multilayer perceptrons~(MLPs) on graph tasks has become a hot research topic. However, MLPs rely exclusively on the node features and fail to capture the graph structural information. Previous methods address this issue by processing graph edges into extra inputs for MLPs, but such graph structures may be unavailable for various scenarios. To this end, we propose a Prototype-Guided Knowledge Distillation~(PGKD) method, which does not require graph edges~(edge-free) yet learns structure-aware MLPs. Specifically, we analyze the graph structural information in GNN teachers, and distill such information from GNNs to MLPs via prototypes in an edge-free setting. Experimental results on popular graph benchmarks demonstrate the effectiveness and robustness of the proposed PGKD.
SynGen: A Syntactic Plug-and-play Module for Generative Aspect-based Sentiment Analysis
Feb 25, 2023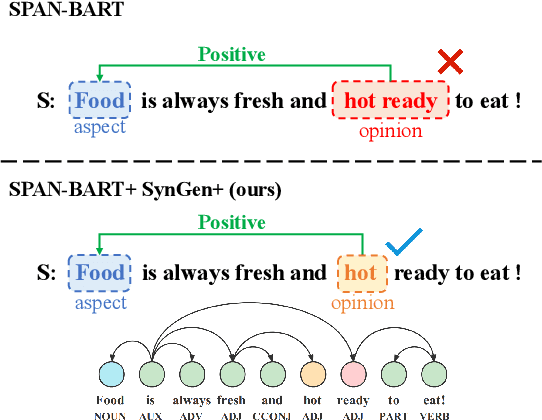
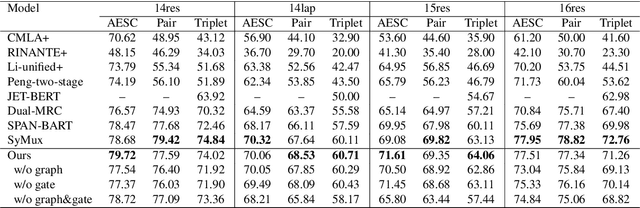
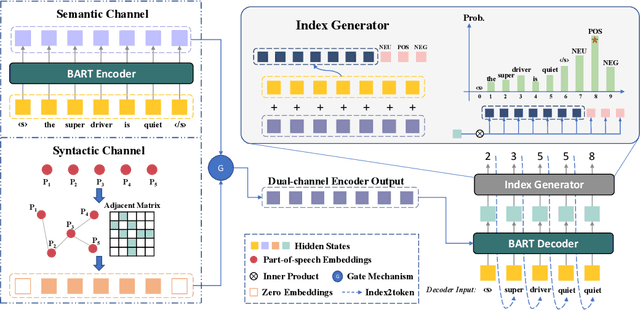
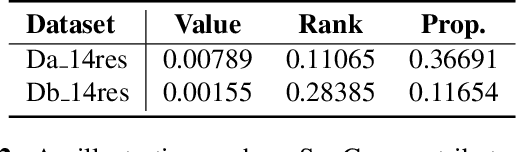
Aspect-based Sentiment Analysis (ABSA) is a sentiment analysis task at fine-grained level. Recently, generative frameworks have attracted increasing attention in ABSA due to their ability to unify subtasks and their continuity to upstream pre-training tasks. However, these generative models suffer from the neighboring dependency problem that induces neighboring words to get higher attention. In this paper, we propose SynGen, a plug-and-play syntactic information aware module. As a plug-in module, our SynGen can be easily applied to any generative framework backbones. The key insight of our module is to add syntactic inductive bias to attention assignment and thus direct attention to the correct target words. To the best of our knowledge, we are the first one to introduce syntactic information to generative ABSA frameworks. Our module design is based on two main principles: (1) maintaining the structural integrity of backbone PLMs and (2) disentangling the added syntactic information and original semantic information. Empirical results on four popular ABSA datasets demonstrate that SynGen enhanced model achieves a comparable performance to the state-of-the-art model with relaxed labeling specification and less training consumption.
* 4 pages, 2 figure, 2 tables
Modeling Fine-grained Information via Knowledge-aware Hierarchical Graph for Zero-shot Entity Retrieval
Nov 20, 2022Zero-shot entity retrieval, aiming to link mentions to candidate entities under the zero-shot setting, is vital for many tasks in Natural Language Processing. Most existing methods represent mentions/entities via the sentence embeddings of corresponding context from the Pre-trained Language Model. However, we argue that such coarse-grained sentence embeddings can not fully model the mentions/entities, especially when the attention scores towards mentions/entities are relatively low. In this work, we propose GER, a \textbf{G}raph enhanced \textbf{E}ntity \textbf{R}etrieval framework, to capture more fine-grained information as complementary to sentence embeddings. We extract the knowledge units from the corresponding context and then construct a mention/entity centralized graph. Hence, we can learn the fine-grained information about mention/entity by aggregating information from these knowledge units. To avoid the graph information bottleneck for the central mention/entity node, we construct a hierarchical graph and design a novel Hierarchical Graph Attention Network~(HGAN). Experimental results on popular benchmarks demonstrate that our proposed GER framework performs better than previous state-of-the-art models. The code has been available at https://github.com/wutaiqiang/GER-WSDM2023.
* 9 pages, 5 figures