 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-switching pre-training for neural machine translation
Sep 17, 2020
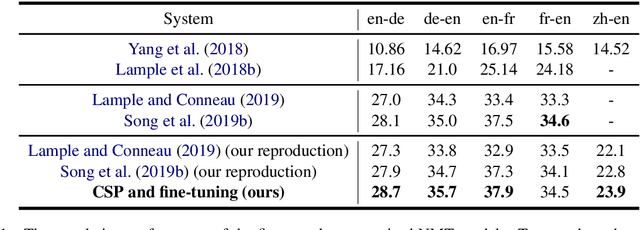

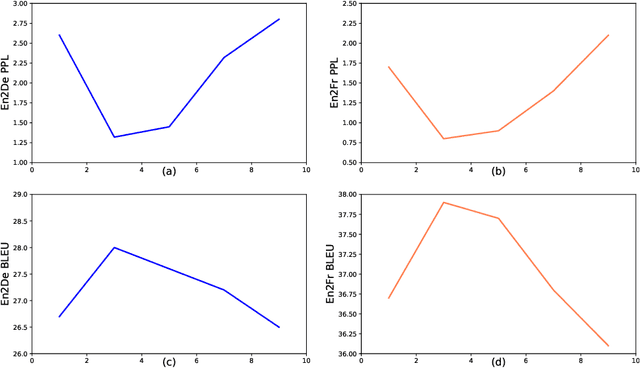
This paper proposes a new pre-training method, called Code-Switching Pre-training (CSP for short) for Neural Machine Translation (NMT). Unlike traditional pre-training method which randomly masks some fragments of the input sentence, the proposed CSP randomly replaces some words in the source sentence with their translation words in the target language. Specifically, we firstly perform lexicon induction with unsupervised word embedding mapping between the source and target languages, and then randomly replace some words in the input sentence with their translation words according to the extracted translation lexicons. CSP adopts the encoder-decoder framework: its encoder takes the code-mixed sentence as input, and its decoder predicts the replaced fragment of the input sentence. In this way, CSP is able to pre-train the NMT model by explicitly making the most of the cross-lingual alignment information extracted from the source and target monolingual corpus. Additionally, we relieve the pretrain-finetune discrepancy caused by the artificial symbols like [mask]. To verify the effectiveness of the proposed method, we conduct extensive experiments on unsupervised and supervised NMT. Experimental results show that CSP achieves significant improvements over baselines without pre-training or with other pre-training methods.