 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Curriculum Learning for Low-Resource Neural Machine Translation
Nov 30, 2020

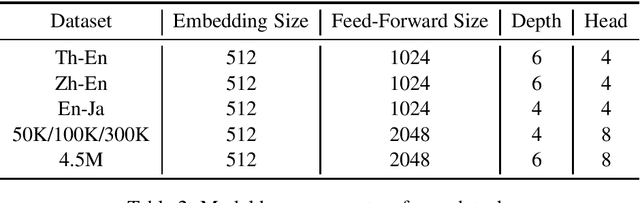

Large amounts of data has made neural machine translation (NMT) a big success in recent years. But it is still a challenge if we train these models on small-scale corpora. In this case, the way of using data appears to be more important. Here, we investigate the effective use of training data for low-resource NMT. In particular, we propose a dynamic curriculum learning (DCL) method to reorder training samples in training. Unlike previous work, we do not use a static scoring function for reordering. Instead, the order of training samples is dynamically determined in two ways - loss decline and model competence. This eases training by highlighting easy samples that the current model has enough competence to learn. We test our DCL method in a Transformer-based system. Experimental results show that DCL outperforms several strong baselines on three low-resource machine translation benchmarks and different sized data of WMT' 16 En-De.