 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation Invariant Deep CBIR
Jun 21, 2020



Introduction of Convolutional Neural Networks has improved results on almost every image-based problem and Content-Based Image Retrieval is not an exception. But the CNN features, being rotation invariant, creates problems to build a rotation-invariant CBIR system. Though rotation-invariant features can be hand-engineered, the retrieval accuracy is very low because by hand engineering only low-level features can be created, unlike deep learning models that create high-level features along with low-level features. This paper shows a novel method to build a rotational invariant CBIR system by introducing a deep learning orientation angle detection model along with the CBIR feature extraction model. This paper also highlights that this rotation invariant deep CBIR can retrieve images from a large dataset in real-time.
An Improved Relevance Feedback in CBIR
Jun 21, 2020


Relevance Feedback in Content-Based Image Retrieval is a method where the feedback of the performance is being used to improve itself. Prior works use feature re-weighting and classification techniques as the Relevance Feedback methods. This paper shows a novel addition to the prior methods to further improve the retrieval accuracy. In addition to all of these, the paper also shows a novel idea to even improve the 0-th iteration retrieval accuracy from the information of Relevance Feedback.
Deep Image Orientation Angle Detection
Jun 21, 2020



Estimating and rectifying the orientation angle of any image is a pretty challenging task. Initial work used the hand engineering features for this purpose, where after the invention of deep learning using convolution-based neural network showed significant improvement in this problem. However, this paper shows that the combination of CNN and a custom loss function specially designed for angles lead to a state-of-the-art results. This includes the estimation of the orientation angle of any image or document at any degree (0 to 360 degree),
CBIR using features derived by Deep Learning
Feb 13, 2020



In a Content Based Image Retrieval (CBIR) System, the task is to retrieve similar images from a large database given a query image. The usual procedure is to extract some useful features from the query image, and retrieve images which have similar set of features. For this purpose, a suitable similarity measure is chosen, and images with high similarity scores are retrieved. Naturally the choice of these features play a very important role in the success of this system, and high level features are required to reduce the semantic gap. In this paper, we propose to use features derived from pre-trained network models from a deep-learning convolution network trained for a large image classification problem. This approach appears to produce vastly superior results for a variety of databases, and it outperforms many contemporary CBIR systems. We analyse the retrieval time of the method, and also propose a pre-clustering of the database based on the above-mentioned features which yields comparable results in a much shorter time in most of the cases.
A Novel Minimum Divergence Approach to Robust Speaker Identification
Dec 16, 2015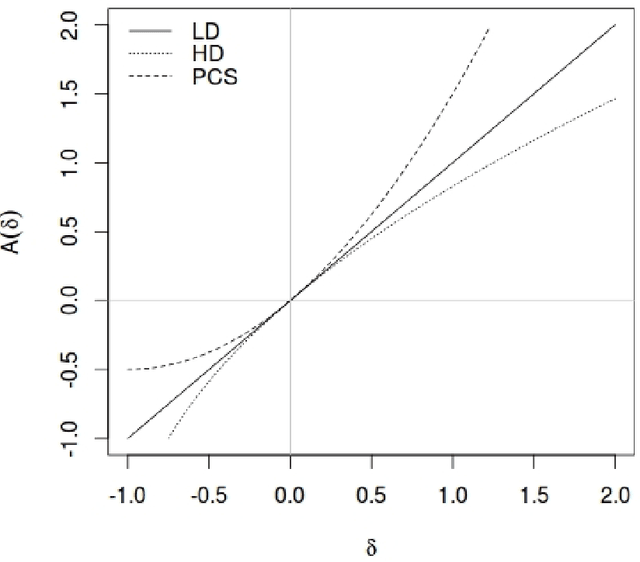
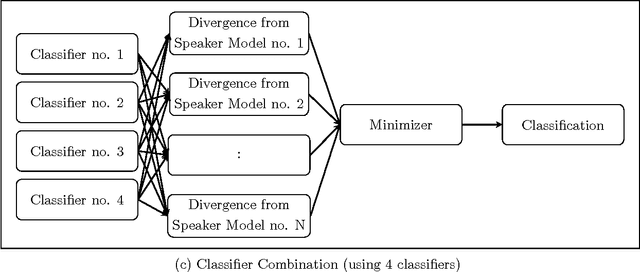
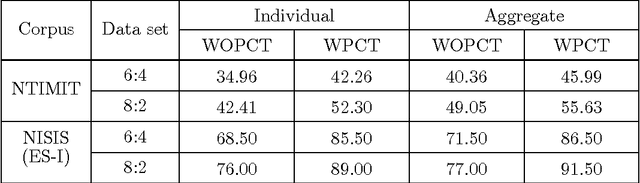
In this work, a novel solution to the speaker identification problem is proposed through minimization of statistical divergences between the probability distribution (g). of feature vectors from the test utterance and the probability distributions of the feature vector corresponding to the speaker classes. This approach is made more robust to the presence of outliers, through the use of suitably modified versions of the standard divergence measures. The relevant solutions to the minimum distance methods are referred to as the minimum rescaled modified distance estimators (MRMDEs). Three measures were considered - the likelihood disparity, the Hellinger distance and Pearson's chi-square distance. The proposed approach is motivated by the observation that, in the case of the likelihood disparity, when the empirical distribution function is used to estimate g, it becomes equivalent to maximum likelihood classification with Gaussian Mixture Models (GMMs) for speaker classes, a highly effective approach used, for example, by Reynolds [22] based on Mel Frequency Cepstral Coefficients (MFCCs) as features. Significant improvement in classification accuracy is observed under this approach on the benchmark speech corpus NTIMIT and a new bilingual speech corpus NISIS, with MFCC features, both in isolation and in combination with delta MFCC features. Moreover, the ubiquitous principal component transformation, by itself and in conjunction with the principle of classifier combination, is found to further enhance the performance.
A Hybrid Approach for Improved Content-based Image Retrieval using Segmentation
Feb 11, 2015


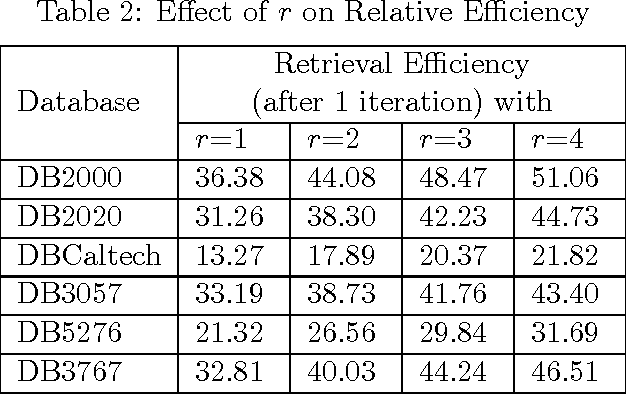
The objective of Content-Based Image Retrieval (CBIR) methods is essentially to extract, from large (image) databases, a specified number of images similar in visual and semantic content to a so-called query image. To bridge the semantic gap that exists between the representation of an image by low-level features (namely, colour, shape, texture) and its high-level semantic content as perceived by humans, CBIR systems typically make use of the relevance feedback (RF) mechanism. RF iteratively incorporates user-given inputs regarding the relevance of retrieved images, to improve retrieval efficiency. One approach is to vary the weights of the features dynamically via feature reweighting. In this work, an attempt has been made to improve retrieval accuracy by enhancing a CBIR system based on color features alone, through implicit incorporation of shape information obtained through prior segmentation of the images. Novel schemes for feature reweighting as well as for initialization of the relevant set for improved relevance feedback, have also been proposed for boosting performance of RF- based CBIR. At the same time, new measures for evaluation of retrieval accuracy have been suggested, to overcome the limitations of existing measures in the RF context. Results of extensive experiments have been presented to illustrate the effectiveness of the proposed approaches.