 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Minimum Divergence Approach to Robust Speaker Identification
Paper and Code
Dec 16, 2015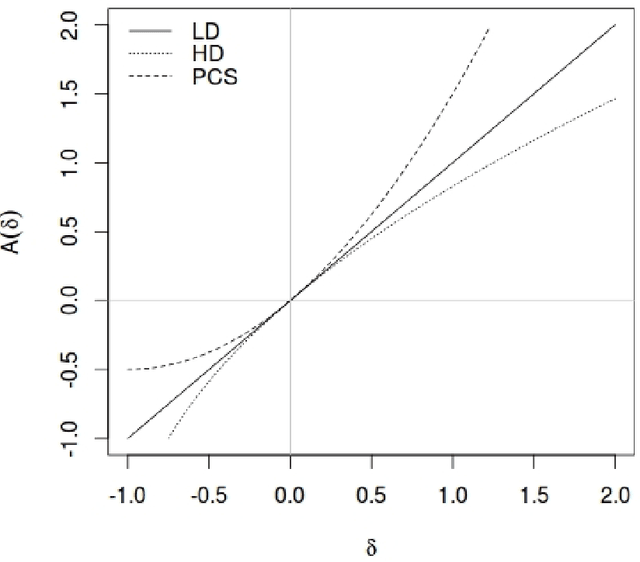
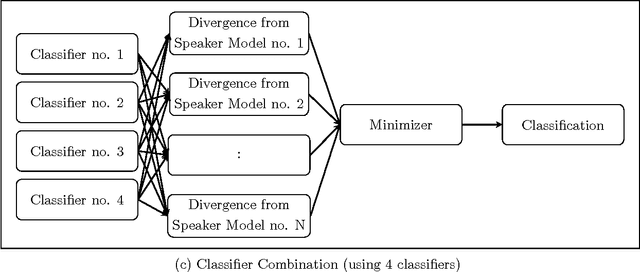
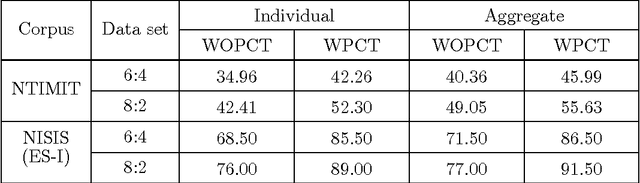
In this work, a novel solution to the speaker identification problem is proposed through minimization of statistical divergences between the probability distribution (g). of feature vectors from the test utterance and the probability distributions of the feature vector corresponding to the speaker classes. This approach is made more robust to the presence of outliers, through the use of suitably modified versions of the standard divergence measures. The relevant solutions to the minimum distance methods are referred to as the minimum rescaled modified distance estimators (MRMDEs). Three measures were considered - the likelihood disparity, the Hellinger distance and Pearson's chi-square distance. The proposed approach is motivated by the observation that, in the case of the likelihood disparity, when the empirical distribution function is used to estimate g, it becomes equivalent to maximum likelihood classification with Gaussian Mixture Models (GMMs) for speaker classes, a highly effective approach used, for example, by Reynolds [22] based on Mel Frequency Cepstral Coefficients (MFCCs) as features. Significant improvement in classification accuracy is observed under this approach on the benchmark speech corpus NTIMIT and a new bilingual speech corpus NISIS, with MFCC features, both in isolation and in combination with delta MFCC features. Moreover, the ubiquitous principal component transformation, by itself and in conjunction with the principle of classifier combination, is found to further enhance the performance.