 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case Study of Cross-Lingual Zero-Shot Generalization for Classical Languages in LLMs
May 19, 2025Large Language Models (LLMs) have demonstrated remarkable generalization capabilities across diverse tasks and languages. In this study, we focus on natural language understanding in three classical languages -- Sanskrit, Ancient Greek and Latin -- to investigate the factors affecting cross-lingual zero-shot generalization. First, we explore named entity recognition and machine translation into English. While LLMs perform equal to or better than fine-tuned baselines on out-of-domain data, smaller models often struggle, especially with niche or abstract entity types. In addition, we concentrate on Sanskrit by presenting a factoid question-answering (QA) dataset and show that incorporating context via retrieval-augmented generation approach significantly boosts performance. In contrast, we observe pronounced performance drops for smaller LLMs across these QA tasks. These results suggest model scale as an important factor influencing cross-lingual generalization. Assuming that models used such as GPT-4o and Llama-3.1 are not instruction fine-tuned on classical languages, our findings provide insights into how LLMs may generalize on these languages and their consequent utility in classical studies.
Sanskrit Knowledge-based Systems: Annotation and Computational Tools
Jun 26, 2024



We address the challenges and opportunities in the development of knowledge systems for Sanskrit, with a focus on question answering. By proposing a framework for the automated construction of knowledge graphs, introducing annotation tools for ontology-driven and general-purpose tasks, and offering a diverse collection of web-interfaces, tools, and software libraries, we have made significant contributions to the field of computational Sanskrit. These contributions not only enhance the accessibility and accuracy of Sanskrit text analysis but also pave the way for further advancements in knowledge representation and language processing. Ultimately, this research contributes to the preservation, understanding, and utilization of the rich linguistic information embodied in Sanskrit texts.
Antarlekhaka: A Comprehensive Tool for Multi-task Natural Language Annotation
Oct 11, 2023



One of the primary obstacles in the advancement of Natural Language Processing (NLP) technologies for low-resource languages is the lack of annotated datasets for training and testing machine learning models. In this paper, we present Antarlekhaka, a tool for manual annotation of a comprehensive set of tasks relevant to NLP. The tool is Unicode-compatible, language-agnostic, Web-deployable and supports distributed annotation by multiple simultaneous annotators. The system sports user-friendly interfaces for 8 categories of annotation tasks. These, in turn, enable the annotation of a considerably larger set of NLP tasks. The task categories include two linguistic tasks not handled by any other tool, namely, sentence boundary detection and deciding canonical word order, which are important tasks for text that is in the form of poetry. We propose the idea of sequential annotation based on small text units, where an annotator performs several tasks related to a single text unit before proceeding to the next unit. The research applications of the proposed mode of multi-task annotation are also discussed. Antarlekhaka outperforms other annotation tools in objective evaluation. It has been also used for two real-life annotation tasks on two different languages, namely, Sanskrit and Bengali. The tool is available at https://github.com/Antarlekhaka/code.
Framework for Question-Answering in Sanskrit through Automated Construction of Knowledge Graphs
Oct 11, 2023Sanskrit (sa\d{m}sk\d{r}ta) enjoys one of the largest and most varied literature in the whole world. Extracting the knowledge from it, however, is a challenging task due to multiple reasons including complexity of the language and paucity of standard natural language processing tools. In this paper, we target the problem of building knowledge graphs for particular types of relationships from sa\d{m}sk\d{r}ta texts. We build a natural language question-answering system in sa\d{m}sk\d{r}ta that uses the knowledge graph to answer factoid questions. We design a framework for the overall system and implement two separate instances of the system on human relationships from mah\=abh\=arata and r\=am\=aya\d{n}a, and one instance on synonymous relationships from bh\=avaprak\=a\'sa nigha\d{n}\d{t}u, a technical text from \=ayurveda. We show that about 50% of the factoid questions can be answered correctly by the system. More importantly, we analyse the shortcomings of the system in detail for each step, and discuss the possible ways forward.
* Accepted at 6th International Sanskrit Computational Linguistics Symposium (ISCLS) 2019
Chandojnanam: A Sanskrit Meter Identification and Utilization System
Sep 29, 2022
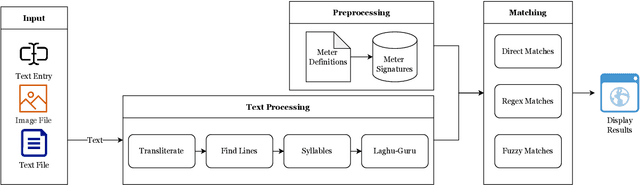
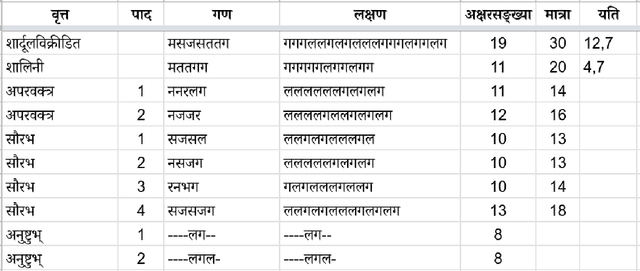

We present Chandoj\~n\=anam, a web-based Sanskrit meter (Chanda) identification and utilization system. In addition to the core functionality of identifying meters, it sports a friendly user interface to display the scansion, which is a graphical representation of the metrical pattern. The system supports identification of meters from uploaded images by using optical character recognition (OCR) engines in the backend. It is also able to process entire text files at a time. The text can be processed in two modes, either by treating it as a list of individual lines, or as a collection of verses. When a line or a verse does not correspond exactly to a known meter, Chandoj\~n\=anam is capable of finding fuzzy (i.e., approximate and close) matches based on sequence matching. This opens up the scope of a meter-based correction of erroneous digital corpora. The system is available for use at https://sanskrit.iitk.ac.in/jnanasangraha/chanda/, and the source code in the form of a Python library is made available at https://github.com/hrishikeshrt/chanda/.
A Novel Multi-Task Learning Approach for Context-Sensitive Compound Type Identification in Sanskrit
Aug 22, 2022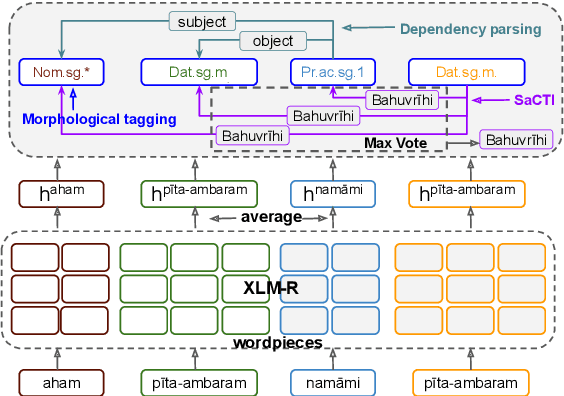
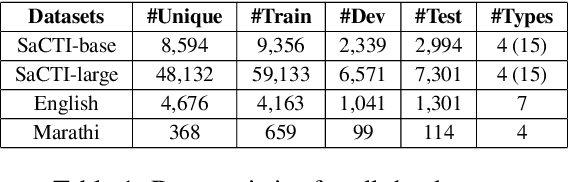
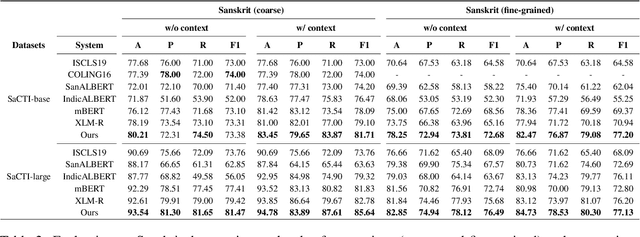
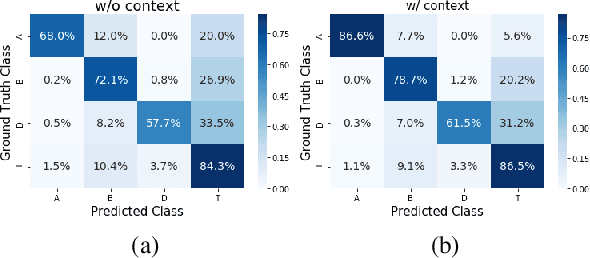
The phenomenon of compounding is ubiquitous in Sanskrit. It serves for achieving brevity in expressing thoughts, while simultaneously enriching the lexical and structural formation of the language. In this work, we focus on the Sanskrit Compound Type Identification (SaCTI) task, where we consider the problem of identifying semantic relations between the components of a compound word. Earlier approaches solely rely on the lexical information obtained from the components and ignore the most crucial contextual and syntactic information useful for SaCTI. However, the SaCTI task is challenging primarily due to the implicitly encoded context-sensitive semantic relation between the compound components. Thus, we propose a novel multi-task learning architecture which incorporates the contextual information and enriches the complementary syntactic information using morphological tagging and dependency parsing as two auxiliary tasks. Experiments on the benchmark datasets for SaCTI show 6.1 points (Accuracy) and 7.7 points (F1-score) absolute gain compared to the state-of-the-art system. Further, our multi-lingual experiments demonstrate the efficacy of the proposed architecture in English and Marathi languages.The code and datasets are publicly available at https://github.com/ashishgupta2598/SaCTI
Semantic Annotation and Querying Framework based on Semi-structured Ayurvedic Text
Feb 01, 2022Knowledge bases (KB) are an important resource in a number of natural language processing (NLP) and information retrieval (IR) tasks, such as semantic search, automated question-answering etc. They are also useful for researchers trying to gain information from a text. Unfortunately, however, the state-of-the-art in Sanskrit NLP does not yet allow automated construction of knowledge bases due to unavailability or lack of sufficient accuracy of tools and methods. Thus, in this work, we describe our efforts on manual annotation of Sanskrit text for the purpose of knowledge graph (KG) creation. We choose the chapter Dhanyavarga from Bhavaprakashanighantu of the Ayurvedic text Bhavaprakasha for annotation. The constructed knowledge graph contains 410 entities and 764 relationships. Since Bhavaprakashanighantu is a technical glossary text that describes various properties of different substances, we develop an elaborate ontology to capture the semantics of the entity and relationship types present in the text. To query the knowledge graph, we design 31 query templates that cover most of the common question patterns. For both manual annotation and querying, we customize the Sangrahaka framework previously developed by us. The entire system including the dataset is available from https://sanskrit.iitk.ac.in/ayurveda/ . We hope that the knowledge graph that we have created through manual annotation and subsequent curation will help in development and testing of NLP tools in future as well as studying of the Bhavaprakasanighantu text.
* 19 pages including appendix
Sangrahaka: A Tool for Annotating and Querying Knowledge Graphs
Jul 06, 2021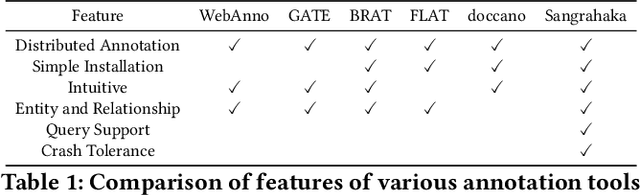

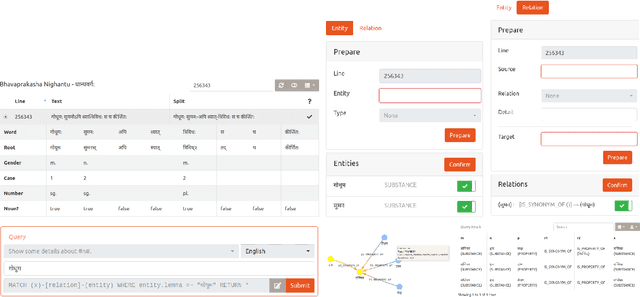

In this work, we present a web-based annotation and querying tool Sangrahaka. It annotates entities and relationships from text corpora and constructs a knowledge graph (KG). The KG is queried using templatized natural language queries. The application is language and corpus agnostic, but can be tuned for special needs of a specific language or a corpus. A customized version of the framework has been used in two annotation tasks. The application is available for download and installation. Besides having a user-friendly interface, it is fast, supports customization, and is fault tolerant on both client and server side. The code is available at https://github.com/hrishikeshrt/sangrahaka and the presentation with a demo is available at https://youtu.be/nw9GFLVZMMo.