 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARAMANU-GANITA: Language Model with Mathematical Capabilities
Apr 22, 2024

In this paper, we present Paramanu-Ganita, a 208 million parameter novel Auto Regressive (AR) decoder based language model on mathematics. The model is pretrained from scratch at context size of 4096 on our curated mixed mathematical corpus. We evaluate our model on both perplexity metric and GSM8k mathematical benchmark. Paramanu-Ganita despite being 35 times smaller than 7B LLMs, outperformed generalist LLMs such as LLaMa-1 7B by 28.4% points, LLaMa-2 7B by 27.6% points, Falcon 7B by 32.6% points, PaLM 8B by 35.3% points, and math specialised LLMs such as Minerva 8B by 23.2% points, and LLEMMA-7B by 3.0% points in GSM8k test accuracy metric respectively. Paramanu-Ganita also outperformed giant LLMs like PaLM 62B by 6.4% points, Falcon 40B by 19.8% points, LLaMa-1 33B by 3.8% points and Vicuna 13B by 11.8% points respectively. The large significant margin improvement in performance of our math model over the existing LLMs signifies that reasoning capabilities of language model are just not restricted to LLMs with humongous number of parameters. Paramanu-Ganita took 146 hours of A100 training whereas math specialised LLM, LLEMMA 7B, was trained for 23,000 A100 hours of training equivalent. Thus, our approach of pretraining powerful domain specialised language models from scratch for domain adaptation is much more cost-effective than performing continual training of LLMs for domain adaptation. Hence, we conclude that for strong mathematical reasoning abilities of language model, we do not need giant LLMs and immense computing power to our end. In the end, we want to point out that we have only trained Paramanu-Ganita only on a part of our entire mathematical corpus and yet to explore the full potential of our model.
PARAMANU-AYN: An Efficient Novel Generative and Instruction-tuned Language Model for Indian Legal Case Documents
Mar 20, 2024



In this paper, we present PARAMANU-AYN, a language model based exclusively on case documents of the Supreme Court of India, the Constitution of India, and the Indian Penal Code. The novel Auto Regressive (AR) decoder based model is pretrained from scratch at a context size of 8192. We evaluated our pretrained legal model on perplexity metrics. We also instruction-tuned our pretrained model on a set of 10,763 instructions covering various legal tasks such as legal reasoning, judgement explanation, legal clause generation, legal drafting, legal contract drafting, case summarization, constitutional question-answering, etc. We also evaluated the responses of prompts for instruction-tuned models by GPT-3.5-Turbo on clarity, relevance, completeness, and legal reasoning metrics in a scale of 10. Our model can be run on CPU and achieved 42.46 tokens/sec CPU inference speed. We found that our models, despite not being pretrained on legal books, various legal contracts, and legal documents, were able to learn the domain knowledge required for drafting various legal contracts and legal clauses, and generalize to draft legal contracts and legal clauses with limited instruction tuning. Hence, we conclude that for a strong domain-specialized generative language model (such as legal), very large amounts of data are not required to develop models from scratch. We believe that this work is the first attempt to make a dedicated generative legal language model from scratch for Indian Supreme Court jurisdiction or in legal NLP overall. We plan to release our Paramanu-Ayn model at https://www.bharatgpts.com.
Neural Models for Source Code Synthesis and Completion
Feb 08, 2024Natural language (NL) to code suggestion systems assist developers in Integrated Development Environments (IDEs) by translating NL utterances into compilable code snippet. The current approaches mainly involve hard-coded, rule-based systems based on semantic parsing. These systems make heavy use of hand-crafted rules that map patterns in NL or elements in its syntax parse tree to various query constructs and can only work on a limited subset of NL with a restricted NL syntax. These systems are unable to extract semantic information from the coding intents of the developer, and often fail to infer types, names, and the context of the source code to get accurate system-level code suggestions. In this master thesis, we present sequence-to-sequence deep learning models and training paradigms to map NL to general-purpose programming languages that can assist users with suggestions of source code snippets, given a NL intent, and also extend auto-completion functionality of the source code to users while they are writing source code. The developed architecture incorporates contextual awareness into neural models which generate source code tokens directly instead of generating parse trees/abstract meaning representations from the source code and converting them back to source code. The proposed pretraining strategy and the data augmentation techniques improve the performance of the proposed architecture. The proposed architecture has been found to exceed the performance of a neural semantic parser, TranX, based on the BLEU-4 metric by 10.82%. Thereafter, a finer analysis for the parsable code translations from the NL intent for CoNaLA challenge was introduced. The proposed system is bidirectional as it can be also used to generate NL code documentation given source code. Lastly, a RoBERTa masked language model for Python was proposed to extend the developed system for code completion.
Paramanu: A Family of Novel Efficient Indic Generative Foundation Language Models
Jan 31, 2024We present Gyan AI Paramanu ("atom"), a family of novel language models for Indian languages. It is a collection of auto-regressive monolingual, bilingual, and multilingual Indic language models pretrained from scratch on a single GPU for 10 Indian languages (Assamese, Bangla, Hindi, Konkani, Maithili, Marathi, Odia, Sanskrit, Tamil, Telugu) across 5 scripts (Bangla, Devanagari, Odia, Tamil, Telugu) of varying sizes ranging from 13.29M to 367.5M.The models are pretrained with a context size of 1024 on a single GPU. The models are very efficient, small, fast, and powerful. We have also developed an efficient most advanced Indic tokenizer that can even tokenize unseen languages. In order to avoid the "curse of multi-linguality" in our multilingual mParamanu model, we pretrained on comparable corpora by typological grouping using the same script. We performed human evaluation of our pretrained models for open end text generation on grammar, coherence, creativity, and factuality metrics for Bangla, Hindi, and Sanskrit. Our Bangla, Hindi, and Sanskrit models outperformed GPT-3.5-Turbo (ChatGPT), Bloom 7B, LLaMa-2 7B, OPT 6.7B, GPT-J 6B, GPTNeo 1.3B, GPT2-XL large language models (LLMs) by a large margin despite being smaller in size by 66 to 20 times compared to standard 7B LLMs. To run inference on our pretrained models, CPU is enough, and GPU is not needed. We also instruction-tuned our pretrained Bangla, Hindi, Marathi, Tamil, and Telugu models on 23k instructions in respective languages. Our pretrained and instruction-tuned models which are first of its kind, most powerful efficient small generative language models ever developed for Indic languages, and the various results lead to the conclusion that high quality generative language models are possible without high amount of compute power and humongous number of parameters. We plan to release our models at https://www.bharatgpts.com.
Learning Multilingual Embeddings for Cross-Lingual Information Retrieval in the Presence of Topically Aligned Corpora
Apr 12, 2018



Cross-lingual information retrieval is a challenging task in the absence of aligned parallel corpora. In this paper, we address this problem by considering topically aligned corpora designed for evaluating an IR setup. To emphasize, we neither use any sentence-aligned corpora or document-aligned corpora, nor do we use any language specific resources such as dictionary, thesaurus, or grammar rules. Instead, we use an embedding into a common space and learn word correspondences directly from there. We test our proposed approach for bilingual IR on standard FIRE datasets for Bangla, Hindi and English. The proposed method is superior to the state-of-the-art method not only for IR evaluation measures but also in terms of time requirements. We extend our method successfully to the trilingual setting.
Discovering conversational topics and emotions associated with Demonetization tweets in India
Nov 11, 2017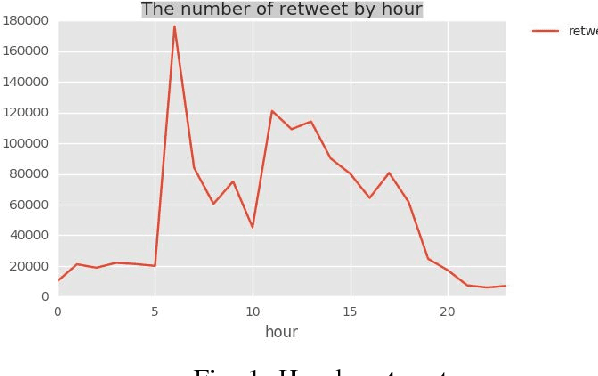
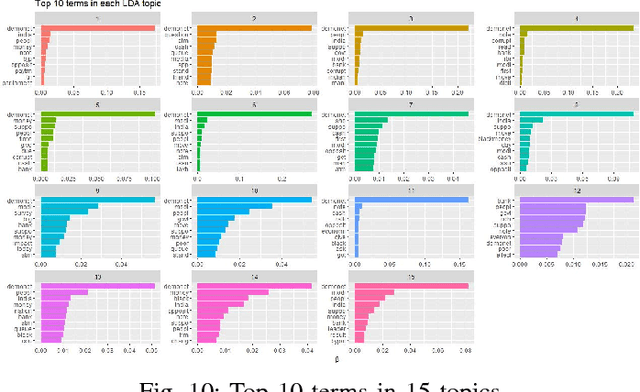
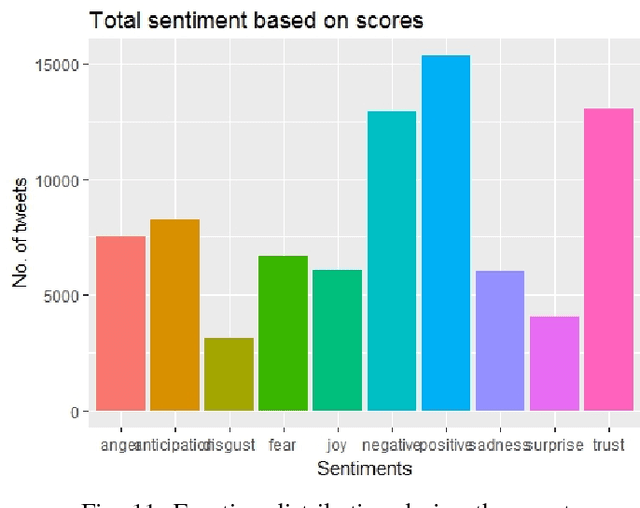
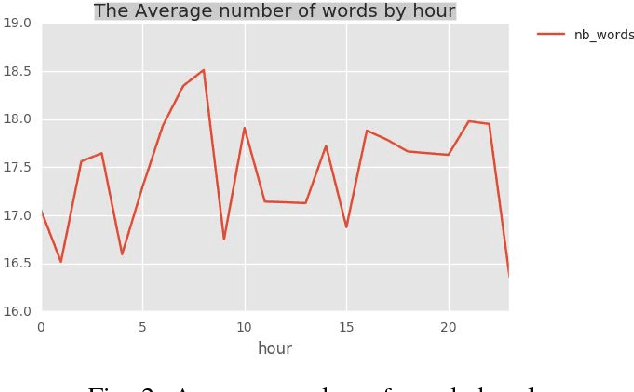
Social media platforms contain great wealth of information which provides us opportunities explore hidden patterns or unknown correlations, and understand people's satisfaction with what they are discussing. As one showcase, in this paper, we summarize the data set of Twitter messages related to recent demonetization of all Rs. 500 and Rs. 1000 notes in India and explore insights from Twitter's data. Our proposed system automatically extracts the popular latent topics in conversations regarding demonetization discussed in Twitter via the Latent Dirichlet Allocation (LDA) based topic model and also identifies the correlated topics across different categories. Additionally, it also discovers people's opinions expressed through their tweets related to the event under consideration via the emotion analyzer. The system also employs an intuitive and informative visualization to show the uncovered insight. Furthermore, we use an evaluation measure, Normalized Mutual Information (NMI), to select the best LDA models. The obtained LDA results show that the tool can be effectively used to extract discussion topics and summarize them for further manual analysis.