 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Temporal Synergic Residual Learning for Video Person Re-Identification
Jul 16, 2018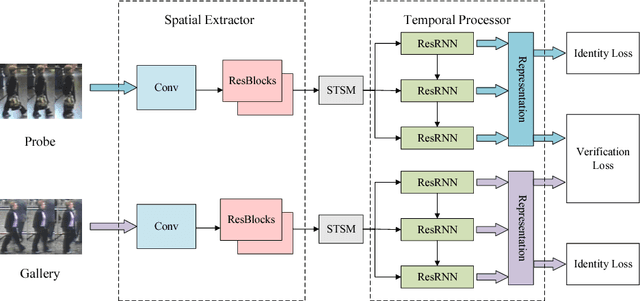



We tackle the problem of person re-identification in video setting in this paper, which has been viewed as a crucial task in many applications. Meanwhile, it is very challenging since the task requires learning effective representations from video sequences with heterogeneous spatial-temporal information. We present a novel method - Spatial-Temporal Synergic Residual Network (STSRN) for this problem. STSRN contains a spatial residual extractor, a temporal residual processor and a spatial-temporal smooth module. The smoother can alleviate sample noises along the spatial-temporal dimensions thus enable STSRN extracts more robust spatial-temporal features of consecutive frames. Extensive experiments are conducted on several challenging datasets including iLIDS-VID, PRID2011 and MARS. The results demonstrate that the proposed method achieves consistently superior performance over most of state-of-the-art methods.