 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision over Diversity: High-Precision Reward Generalizes to Robust Instruction Following
Jan 08, 2026A central belief in scaling reinforcement learning with verifiable rewards for instruction following (IF) tasks is that, a diverse mixture of verifiable hard and unverifiable soft constraints is essential for generalizing to unseen instructions. In this work, we challenge this prevailing consensus through a systematic empirical investigation. Counter-intuitively, we find that models trained on hard-only constraints consistently outperform those trained on mixed datasets. Extensive experiments reveal that reward precision, rather than constraint diversity, is the primary driver of effective alignment. The LLM judge suffers from a low recall rate in detecting false response, which leads to severe reward hacking, thereby undermining the benefits of diversity. Furthermore, analysis of the attention mechanism reveals that high-precision rewards develop a transferable meta-skill for IF. Motivated by these insights, we propose a simple yet effective data-centric refinement strategy that prioritizes reward precision. Evaluated on five benchmarks, our approach outperforms competitive baselines by 13.4\% in performance while achieving a 58\% reduction in training time, maintaining strong generalization beyond instruction following. Our findings advocate for a paradigm shift: moving away from the indiscriminate pursuit of data diversity toward high-precision rewards.
TreeAdv: Tree-Structured Advantage Redistribution for Group-Based RL
Jan 07, 2026Reinforcement learning with group-based objectives, such as Group Relative Policy Optimization (GRPO), is a common framework for aligning large language models on complex reasoning tasks. However, standard GRPO treats each rollout trajectory as an independent flat sequence and assigns a single sequence-level advantage to all tokens, which leads to sample inefficiency and a length bias toward verbose, redundant chains of thought without improving logical depth. We introduce TreeAdv (Tree-Structured Advantage Redistribution for Group-Based RL), which makes the tree structure of group rollouts explicit for both exploration and advantage assignment. Specifically, TreeAdv builds a group of trees (a forest) based on an entropy-driven sampling method where each tree branches at high-uncertainty decisions while sharing low-uncertainty tokens across rollouts. Then, TreeAdv aggregates token-level advantages for internal tree segments by redistributing the advantages of complete rollouts (all leaf nodes), and TreeAdv can easily apply to group-based objectives such as GRPO or GSPO. Across 10 math reasoning benchmarks, TreeAdv consistently outperforms GRPO and GSPO, while using substantially fewer generated tokens under identical supervision, data, and decoding budgets.
Process Reward Modeling with Entropy-Driven Uncertainty
Mar 28, 2025



This paper presents the Entropy-Driven Unified Process Reward Model (EDU-PRM), a novel framework that approximates state-of-the-art performance in process supervision while drastically reducing training costs. EDU-PRM introduces an entropy-guided dynamic step partitioning mechanism, using logit distribution entropy to pinpoint high-uncertainty regions during token generation dynamically. This self-assessment capability enables precise step-level feedback without manual fine-grained annotation, addressing a critical challenge in process supervision. Experiments on the Qwen2.5-72B model with only 7,500 EDU-PRM-generated training queries demonstrate accuracy closely approximating the full Qwen2.5-72B-PRM (71.1% vs. 71.6%), achieving a 98% reduction in query cost compared to prior methods. This work establishes EDU-PRM as an efficient approach for scalable process reward model training.
Boosting Tool Use of Large Language Models via Iterative Reinforced Fine-Tuning
Jan 15, 2025



Augmenting large language models (LLMs) with external tools is a promising approach to enhance their capabilities. Effectively leveraging this potential for complex tasks hinges crucially on improving their ability to use tools. Synthesizing tool use data by simulating the real world is an effective approach. Nevertheless, our investigation reveals that training gains significantly decay as the scale of these data increases. The primary factor is the model's poor performance (a.k.a deficiency) in complex scenarios, which hinders learning from data using SFT. Driven by this objective, we propose an iterative reinforced fine-tuning strategy to continually guide the model to alleviate it. Specifically, we first identify deficiency-related data based on feedback from the policy model, then perform a Monte Carlo Tree Search to collect fine-grained preference pairs to pinpoint deficiencies. Subsequently, we update the policy model using preference optimization to align with ground truth and misalign with deficiencies. This process can be iterated. Moreover, before the iteration, we propose an easy-to-hard warm-up SFT strategy to facilitate learning from challenging data. The experiments demonstrate our models go beyond the same parametric models, outperforming many larger open-source and closed-source models. Additionally, it has achieved notable training gains in complex tool use scenarios.
ToolACE: Winning the Points of LLM Function Calling
Sep 02, 2024



Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.
Joint Attention-Driven Domain Fusion and Noise-Tolerant Learning for Multi-Source Domain Adaptation
Aug 05, 2022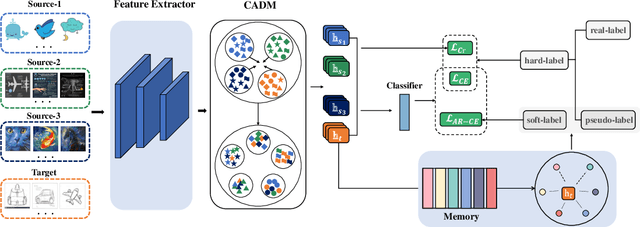

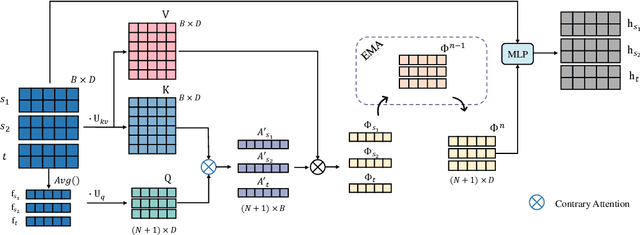

As a study on the efficient usage of data, Multi-source Unsupervised Domain Adaptation transfers knowledge from multiple source domains with labeled data to an unlabeled target domain. However, the distribution discrepancy between different domains and the noisy pseudo-labels in the target domain both lead to performance bottlenecks of the Multi-source Unsupervised Domain Adaptation methods. In light of this, we propose an approach that integrates Attention-driven Domain fusion and Noise-Tolerant learning (ADNT) to address the two issues mentioned above. Firstly, we establish a contrary attention structure to perform message passing between features and to induce domain movement. Through this approach, the discriminability of the features can also be significantly improved while the domain discrepancy is reduced. Secondly, based on the characteristics of the unsupervised domain adaptation training, we design an Adaptive Reverse Cross Entropy loss, which can directly impose constraints on the generation of pseudo-labels. Finally, combining these two approaches, experimental results on several benchmarks further validate the effectiveness of our proposed ADNT and demonstrate superior performance over the state-of-the-art methods.