 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldWarp: Propagating 3D Geometry with Asynchronous Video Diffusion
Dec 22, 2025Generating long-range, geometrically consistent video presents a fundamental dilemma: while consistency demands strict adherence to 3D geometry in pixel space, state-of-the-art generative models operate most effectively in a camera-conditioned latent space. This disconnect causes current methods to struggle with occluded areas and complex camera trajectories. To bridge this gap, we propose WorldWarp, a framework that couples a 3D structural anchor with a 2D generative refiner. To establish geometric grounding, WorldWarp maintains an online 3D geometric cache built via Gaussian Splatting (3DGS). By explicitly warping historical content into novel views, this cache acts as a structural scaffold, ensuring each new frame respects prior geometry. However, static warping inevitably leaves holes and artifacts due to occlusions. We address this using a Spatio-Temporal Diffusion (ST-Diff) model designed for a "fill-and-revise" objective. Our key innovation is a spatio-temporal varying noise schedule: blank regions receive full noise to trigger generation, while warped regions receive partial noise to enable refinement. By dynamically updating the 3D cache at every step, WorldWarp maintains consistency across video chunks. Consequently, it achieves state-of-the-art fidelity by ensuring that 3D logic guides structure while diffusion logic perfects texture. Project page: \href{https://hyokong.github.io/worldwarp-page/}{https://hyokong.github.io/worldwarp-page/}.
Efficient Gaussian Splatting for Monocular Dynamic Scene Rendering via Sparse Time-Variant Attribute Modeling
Feb 27, 2025Rendering dynamic scenes from monocular videos is a crucial yet challenging task. The recent deformable Gaussian Splatting has emerged as a robust solution to represent real-world dynamic scenes. However, it often leads to heavily redundant Gaussians, attempting to fit every training view at various time steps, leading to slower rendering speeds. Additionally, the attributes of Gaussians in static areas are time-invariant, making it unnecessary to model every Gaussian, which can cause jittering in static regions. In practice, the primary bottleneck in rendering speed for dynamic scenes is the number of Gaussians. In response, we introduce Efficient Dynamic Gaussian Splatting (EDGS), which represents dynamic scenes via sparse time-variant attribute modeling. Our approach formulates dynamic scenes using a sparse anchor-grid representation, with the motion flow of dense Gaussians calculated via a classical kernel representation. Furthermore, we propose an unsupervised strategy to efficiently filter out anchors corresponding to static areas. Only anchors associated with deformable objects are input into MLPs to query time-variant attributes. Experiments on two real-world datasets demonstrate that our EDGS significantly improves the rendering speed with superior rendering quality compared to previous state-of-the-art methods.
DreamDrone
Dec 17, 2023



We introduce DreamDrone, an innovative method for generating unbounded flythrough scenes from textual prompts. Central to our method is a novel feature-correspondence-guidance diffusion process, which utilizes the strong correspondence of intermediate features in the diffusion model. Leveraging this guidance strategy, we further propose an advanced technique for editing the intermediate latent code, enabling the generation of subsequent novel views with geometric consistency. Extensive experiments reveal that DreamDrone significantly surpasses existing methods, delivering highly authentic scene generation with exceptional visual quality. This approach marks a significant step in zero-shot perpetual view generation from textual prompts, enabling the creation of diverse scenes, including natural landscapes like oases and caves, as well as complex urban settings such as Lego-style street views. Our code is publicly available.
Priority-Centric Human Motion Generation in Discrete Latent Space
Aug 30, 2023Text-to-motion generation is a formidable task, aiming to produce human motions that align with the input text while also adhering to human capabilities and physical laws. While there have been advancements in diffusion models, their application in discrete spaces remains underexplored. Current methods often overlook the varying significance of different motions, treating them uniformly. It is essential to recognize that not all motions hold the same relevance to a particular textual description. Some motions, being more salient and informative, should be given precedence during generation. In response, we introduce a Priority-Centric Motion Discrete Diffusion Model (M2DM), which utilizes a Transformer-based VQ-VAE to derive a concise, discrete motion representation, incorporating a global self-attention mechanism and a regularization term to counteract code collapse. We also present a motion discrete diffusion model that employs an innovative noise schedule, determined by the significance of each motion token within the entire motion sequence. This approach retains the most salient motions during the reverse diffusion process, leading to more semantically rich and varied motions. Additionally, we formulate two strategies to gauge the importance of motion tokens, drawing from both textual and visual indicators. Comprehensive experiments on the HumanML3D and KIT-ML datasets confirm that our model surpasses existing techniques in fidelity and diversity, particularly for intricate textual descriptions.
Cross-Resolution Face Recognition via Prior-Aided Face Hallucination and Residual Knowledge Distillation
May 26, 2019


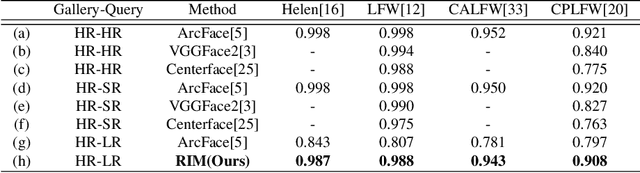
Recent deep learning based face recognition methods have achieved great performance, but it still remains challenging to recognize very low-resolution query face like 28x28 pixels when CCTV camera is far from the captured subject. Such face with very low-resolution is totally out of detail information of the face identity compared to normal resolution in a gallery and hard to find corresponding faces therein. To this end, we propose a Resolution Invariant Model (RIM) for addressing such cross-resolution face recognition problems, with three distinct novelties. First, RIM is a novel and unified deep architecture, containing a Face Hallucination sub-Net (FHN) and a Heterogeneous Recognition sub-Net (HRN), which are jointly learned end to end. Second, FHN is a well-designed tri-path Generative Adversarial Network (GAN) which simultaneously perceives facial structure and geometry prior information, i.e. landmark heatmaps and parsing maps, incorporated with an unsupervised cross-domain adversarial training strategy to super-resolve very low-resolution query image to its 8x larger ones without requiring them to be well aligned. Third, HRN is a generic Convolutional Neural Network (CNN) for heterogeneous face recognition with our proposed residual knowledge distillation strategy for learning discriminative yet generalized feature representation. Quantitative and qualitative experiments on several benchmarks demonstrate the superiority of the proposed model over the state-of-the-arts. Codes and models will be released upon acceptance.