 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Algorithms for Optimizing Generalized Metrics in Binary Classification
Dec 29, 2025In applications with significant class imbalance or asymmetric costs, metrics such as the $F_β$-measure, AM measure, Jaccard similarity coefficient, and weighted accuracy offer more suitable evaluation criteria than standard binary classification loss. However, optimizing these metrics present significant computational and statistical challenges. Existing approaches often rely on the characterization of the Bayes-optimal classifier, and use threshold-based methods that first estimate class probabilities and then seek an optimal threshold. This leads to algorithms that are not tailored to restricted hypothesis sets and lack finite-sample performance guarantees. In this work, we introduce principled algorithms for optimizing generalized metrics, supported by $H$-consistency and finite-sample generalization bounds. Our approach reformulates metric optimization as a generalized cost-sensitive learning problem, enabling the design of novel surrogate loss functions with provable $H$-consistency guarantees. Leveraging this framework, we develop new algorithms, METRO (Metric Optimization), with strong theoretical performance guarantees. We report the results of experiments demonstrating the effectiveness of our methods compared to prior baselines.
Theory and Algorithms for Learning with Multi-Class Abstention and Multi-Expert Deferral
Dec 28, 2025Large language models (LLMs) have achieved remarkable performance but face critical challenges: hallucinations and high inference costs. Leveraging multiple experts offers a solution: deferring uncertain inputs to more capable experts improves reliability, while routing simpler queries to smaller, distilled models enhances efficiency. This motivates the problem of learning with multiple-expert deferral. This thesis presents a comprehensive study of this problem and the related problem of learning with abstention, supported by strong consistency guarantees. First, for learning with abstention (a special case of deferral), we analyze score-based and predictor-rejector formulations in multi-class classification. We introduce new families of surrogate losses and prove strong non-asymptotic, hypothesis set-specific consistency guarantees, resolving two existing open questions. We analyze both single-stage and practical two-stage settings, with experiments on CIFAR-10, CIFAR-100, and SVHN demonstrating the superior performance of our algorithms. Second, we address general multi-expert deferral in classification. We design new surrogate losses for both single-stage and two-stage scenarios and prove they benefit from strong $H$-consistency bounds. For the two-stage scenario, we show that our surrogate losses are realizable $H$-consistent for constant cost functions, leading to effective new algorithms. Finally, we introduce a novel framework for regression with deferral to address continuous label spaces. Our versatile framework accommodates multiple experts and various cost structures, supporting both single-stage and two-stage methods. It subsumes recent work on regression with abstention. We propose new surrogate losses with proven $H$-consistency and demonstrate the empirical effectiveness of the resulting algorithms.
Mastering Multiple-Expert Routing: Realizable $H$-Consistency and Strong Guarantees for Learning to Defer
Jun 25, 2025The problem of learning to defer with multiple experts consists of optimally assigning input instances to experts, balancing the trade-off between their accuracy and computational cost. This is a critical challenge in natural language generation, but also in other fields such as image processing, and medical diagnostics. Recent studies have proposed surrogate loss functions to optimize deferral, but challenges remain in ensuring their consistency properties. This paper introduces novel surrogate loss functions and efficient algorithms with strong theoretical learning guarantees. We address open questions regarding realizable $H$-consistency, $H$-consistency bounds, and Bayes-consistency for both single-stage (jointly learning predictor and deferral function) and two-stage (learning only the deferral function with a fixed expert) learning scenarios. For single-stage deferral, we introduce a family of new realizable $H$-consistent surrogate losses and further prove $H$-consistency for a selected member. For two-stage deferral, we derive new surrogate losses that achieve realizable $H$-consistency, $H$-consistency bounds, and Bayes-consistency for the two-expert scenario and, under natural assumptions, multiple-expert scenario. Additionally, we provide enhanced theoretical guarantees under low-noise assumptions for both scenarios. Finally, we report the results of experiments using our proposed surrogate losses, comparing their performance against existing baselines.
Multi-Label Learning with Stronger Consistency Guarantees
Jul 18, 2024We present a detailed study of surrogate losses and algorithms for multi-label learning, supported by $H$-consistency bounds. We first show that, for the simplest form of multi-label loss (the popular Hamming loss), the well-known consistent binary relevance surrogate suffers from a sub-optimal dependency on the number of labels in terms of $H$-consistency bounds, when using smooth losses such as logistic losses. Furthermore, this loss function fails to account for label correlations. To address these drawbacks, we introduce a novel surrogate loss, multi-label logistic loss, that accounts for label correlations and benefits from label-independent $H$-consistency bounds. We then broaden our analysis to cover a more extensive family of multi-label losses, including all common ones and a new extension defined based on linear-fractional functions with respect to the confusion matrix. We also extend our multi-label logistic losses to more comprehensive multi-label comp-sum losses, adapting comp-sum losses from standard classification to the multi-label learning. We prove that this family of surrogate losses benefits from $H$-consistency bounds, and thus Bayes-consistency, across any general multi-label loss. Our work thus proposes a unified surrogate loss framework benefiting from strong consistency guarantees for any multi-label loss, significantly expanding upon previous work which only established Bayes-consistency and for specific loss functions. Additionally, we adapt constrained losses from standard classification to multi-label constrained losses in a similar way, which also benefit from $H$-consistency bounds and thus Bayes-consistency for any multi-label loss. We further describe efficient gradient computation algorithms for minimizing the multi-label logistic loss.
Enhanced $H$-Consistency Bounds
Jul 18, 2024Recent research has introduced a key notion of $H$-consistency bounds for surrogate losses. These bounds offer finite-sample guarantees, quantifying the relationship between the zero-one estimation error (or other target loss) and the surrogate loss estimation error for a specific hypothesis set. However, previous bounds were derived under the condition that a lower bound of the surrogate loss conditional regret is given as a convex function of the target conditional regret, without non-constant factors depending on the predictor or input instance. Can we derive finer and more favorable $H$-consistency bounds? In this work, we relax this condition and present a general framework for establishing enhanced $H$-consistency bounds based on more general inequalities relating conditional regrets. Our theorems not only subsume existing results as special cases but also enable the derivation of more favorable bounds in various scenarios. These include standard multi-class classification, binary and multi-class classification under Tsybakov noise conditions, and bipartite ranking.
Realizable $H$-Consistent and Bayes-Consistent Loss Functions for Learning to Defer
Jul 18, 2024We present a comprehensive study of surrogate loss functions for learning to defer. We introduce a broad family of surrogate losses, parameterized by a non-increasing function $\Psi$, and establish their realizable $H$-consistency under mild conditions. For cost functions based on classification error, we further show that these losses admit $H$-consistency bounds when the hypothesis set is symmetric and complete, a property satisfied by common neural network and linear function hypothesis sets. Our results also resolve an open question raised in previous work (Mozannar et al., 2023) by proving the realizable $H$-consistency and Bayes-consistency of a specific surrogate loss. Furthermore, we identify choices of $\Psi$ that lead to $H$-consistent surrogate losses for any general cost function, thus achieving Bayes-consistency, realizable $H$-consistency, and $H$-consistency bounds simultaneously. We also investigate the relationship between $H$-consistency bounds and realizable $H$-consistency in learning to defer, highlighting key differences from standard classification. Finally, we empirically evaluate our proposed surrogate losses and compare them with existing baselines.
Cardinality-Aware Set Prediction and Top-$k$ Classification
Jul 09, 2024We present a detailed study of cardinality-aware top-$k$ classification, a novel approach that aims to learn an accurate top-$k$ set predictor while maintaining a low cardinality. We introduce a new target loss function tailored to this setting that accounts for both the classification error and the cardinality of the set predicted. To optimize this loss function, we propose two families of surrogate losses: cost-sensitive comp-sum losses and cost-sensitive constrained losses. Minimizing these loss functions leads to new cardinality-aware algorithms that we describe in detail in the case of both top-$k$ and threshold-based classifiers. We establish $H$-consistency bounds for our cardinality-aware surrogate loss functions, thereby providing a strong theoretical foundation for our algorithms. We report the results of extensive experiments on CIFAR-10, CIFAR-100, ImageNet, and SVHN datasets demonstrating the effectiveness and benefits of our cardinality-aware algorithms.
A Universal Growth Rate for Learning with Smooth Surrogate Losses
May 09, 2024


This paper presents a comprehensive analysis of the growth rate of $H$-consistency bounds (and excess error bounds) for various surrogate losses used in classification. We prove a square-root growth rate near zero for smooth margin-based surrogate losses in binary classification, providing both upper and lower bounds under mild assumptions. This result also translates to excess error bounds. Our lower bound requires weaker conditions than those in previous work for excess error bounds, and our upper bound is entirely novel. Moreover, we extend this analysis to multi-class classification with a series of novel results, demonstrating a universal square-root growth rate for smooth comp-sum and constrained losses, covering common choices for training neural networks in multi-class classification. Given this universal rate, we turn to the question of choosing among different surrogate losses. We first examine how $H$-consistency bounds vary across surrogates based on the number of classes. Next, ignoring constants and focusing on behavior near zero, we identify minimizability gaps as the key differentiating factor in these bounds. Thus, we thoroughly analyze these gaps, to guide surrogate loss selection, covering: comparisons across different comp-sum losses, conditions where gaps become zero, and general conditions leading to small gaps. Additionally, we demonstrate the key role of minimizability gaps in comparing excess error bounds and $H$-consistency bounds.
Regression with Multi-Expert Deferral
Mar 28, 2024Learning to defer with multiple experts is a framework where the learner can choose to defer the prediction to several experts. While this problem has received significant attention in classification contexts, it presents unique challenges in regression due to the infinite and continuous nature of the label space. In this work, we introduce a novel framework of regression with deferral, which involves deferring the prediction to multiple experts. We present a comprehensive analysis for both the single-stage scenario, where there is simultaneous learning of predictor and deferral functions, and the two-stage scenario, which involves a pre-trained predictor with a learned deferral function. We introduce new surrogate loss functions for both scenarios and prove that they are supported by $H$-consistency bounds. These bounds provide consistency guarantees that are stronger than Bayes consistency, as they are non-asymptotic and hypothesis set-specific. Our framework is versatile, applying to multiple experts, accommodating any bounded regression losses, addressing both instance-dependent and label-dependent costs, and supporting both single-stage and two-stage methods. A by-product is that our single-stage formulation includes the recent regression with abstention framework (Cheng et al., 2023) as a special case, where only a single expert, the squared loss and a label-independent cost are considered. Minimizing our proposed loss functions directly leads to novel algorithms for regression with deferral. We report the results of extensive experiments showing the effectiveness of our proposed algorithms.
Top-$k$ Classification and Cardinality-Aware Prediction
Mar 28, 2024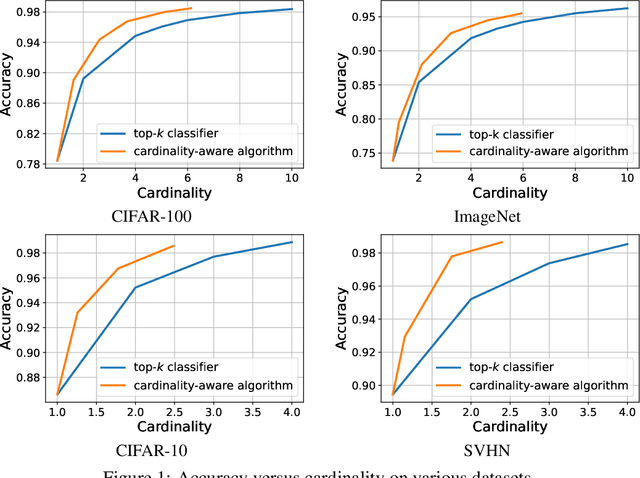
We present a detailed study of top-$k$ classification, the task of predicting the $k$ most probable classes for an input, extending beyond single-class prediction. We demonstrate that several prevalent surrogate loss functions in multi-class classification, such as comp-sum and constrained losses, are supported by $H$-consistency bounds with respect to the top-$k$ loss. These bounds guarantee consistency in relation to the hypothesis set $H$, providing stronger guarantees than Bayes-consistency due to their non-asymptotic and hypothesis-set specific nature. To address the trade-off between accuracy and cardinality $k$, we further introduce cardinality-aware loss functions through instance-dependent cost-sensitive learning. For these functions, we derive cost-sensitive comp-sum and constrained surrogate losses, establishing their $H$-consistency bounds and Bayes-consistency. Minimizing these losses leads to new cardinality-aware algorithms for top-$k$ classification. We report the results of extensive experiments on CIFAR-100, ImageNet, CIFAR-10, and SVHN datasets demonstrating the effectiveness and benefit of these algorithms.