 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplete the Look: Scene-based Complementary Product Recommendation
Paper and Code


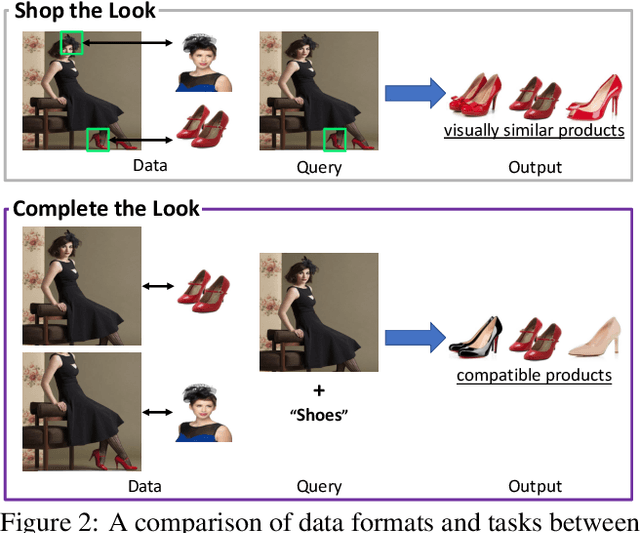
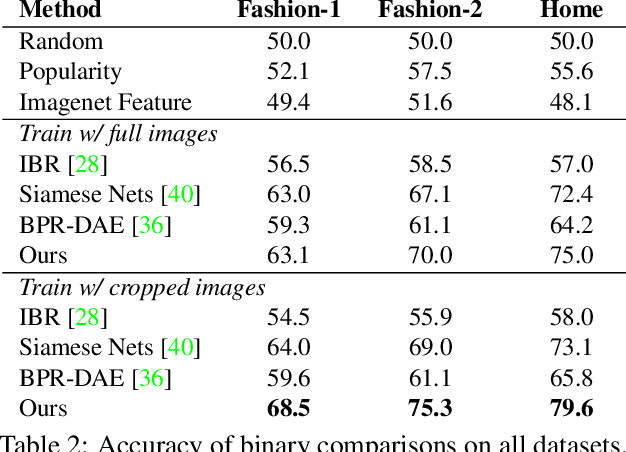
Modeling fashion compatibility is challenging due to its complexity and subjectivity. Existing work focuses on predicting compatibility between product images (e.g. an image containing a t-shirt and an image containing a pair of jeans). However, these approaches ignore real-world 'scene' images (e.g. selfies); such images are hard to deal with due to their complexity, clutter, variations in lighting and pose (etc.) but on the other hand could potentially provide key context (e.g. the user's body type, or the season) for making more accurate recommendations. In this work, we propose a new task called 'Complete the Look', which seeks to recommend visually compatible products based on scene images. We design an approach to extract training data for this task, and propose a novel way to learn the scene-product compatibility from fashion or interior design images. Our approach measures compatibility both globally and locally via CNNs and attention mechanisms. Extensive experiments show that our method achieves significant performance gains over alternative systems. Human evaluation and qualitative analysis are also conducted to further understand model behavior. We hope this work could lead to useful applications which link large corpora of real-world scenes with shoppable products.