 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT5Gemma 2: Seeing, Reading, and Understanding Longer
Dec 23, 2025We introduce T5Gemma 2, the next generation of the T5Gemma family of lightweight open encoder-decoder models, featuring strong multilingual, multimodal and long-context capabilities. T5Gemma 2 follows the adaptation recipe (via UL2) in T5Gemma -- adapting a pretrained decoder-only model into an encoder-decoder model, and extends it from text-only regime to multimodal based on the Gemma 3 models. We further propose two methods to improve the efficiency: tied word embedding that shares all embeddings across encoder and decoder, and merged attention that unifies decoder self- and cross-attention into a single joint module. Experiments demonstrate the generality of the adaptation strategy over architectures and modalities as well as the unique strength of the encoder-decoder architecture on long context modeling. Similar to T5Gemma, T5Gemma 2 yields comparable or better pretraining performance and significantly improved post-training performance than its Gemma 3 counterpart. We release the pretrained models (270M-270M, 1B-1B and 4B-4B) to the community for future research.
Encoder-Decoder Gemma: Improving the Quality-Efficiency Trade-Off via Adaptation
Apr 08, 2025While decoder-only large language models (LLMs) have shown impressive results, encoder-decoder models are still widely adopted in real-world applications for their inference efficiency and richer encoder representation. In this paper, we study a novel problem: adapting pretrained decoder-only LLMs to encoder-decoder, with the goal of leveraging the strengths of both approaches to achieve a more favorable quality-efficiency trade-off. We argue that adaptation not only enables inheriting the capability of decoder-only LLMs but also reduces the demand for computation compared to pretraining from scratch. We rigorously explore different pretraining objectives and parameter initialization/optimization techniques. Through extensive experiments based on Gemma 2 (2B and 9B) and a suite of newly pretrained mT5-sized models (up to 1.6B), we demonstrate the effectiveness of adaptation and the advantage of encoder-decoder LLMs. Under similar inference budget, encoder-decoder LLMs achieve comparable (often better) pretraining performance but substantially better finetuning performance than their decoder-only counterpart. For example, Gemma 2B-2B outperforms Gemma 2B by $\sim$7\% after instruction tuning. Encoder-decoder adaptation also allows for flexible combination of different-sized models, where Gemma 9B-2B significantly surpasses Gemma 2B-2B by $>$3\%. The adapted encoder representation also yields better results on SuperGLUE. We will release our checkpoints to facilitate future research.
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Adapting Decoder-Based Language Models for Diverse Encoder Downstream Tasks
Mar 04, 2025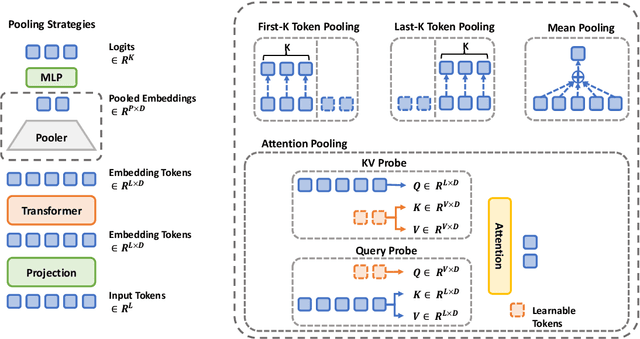
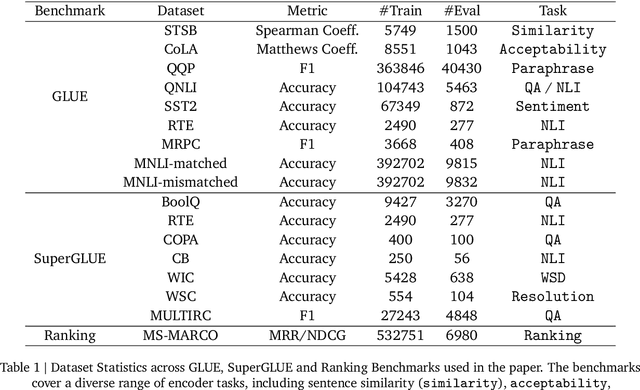
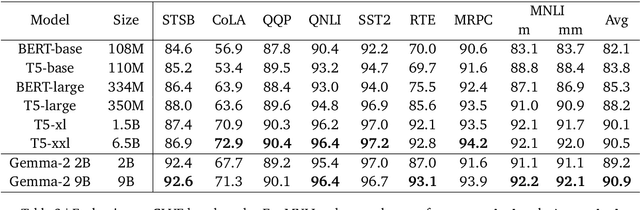
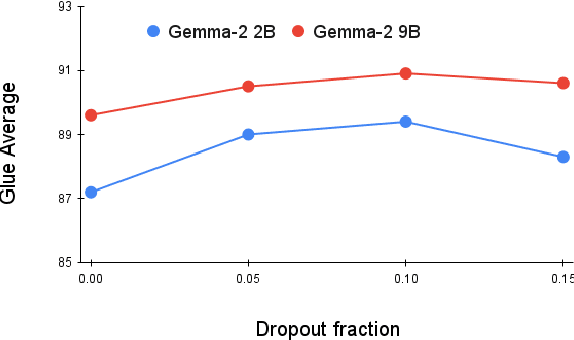
Decoder-based transformers, while revolutionizing language modeling and scaling to immense sizes, have not completely overtaken encoder-heavy architectures in natural language processing. Specifically, encoder-only models remain dominant in tasks like classification, regression, and ranking. This is primarily due to the inherent structure of decoder-based models, which limits their direct applicability to these tasks. In this paper, we introduce Gemma Encoder, adapting the powerful Gemma decoder model to an encoder architecture, thereby unlocking its potential for a wider range of non-generative applications. To optimize the adaptation from decoder to encoder, we systematically analyze various pooling strategies, attention mechanisms, and hyperparameters (e.g., dropout rate). Furthermore, we benchmark Gemma Encoder against established approaches on the GLUE benchmarks, and MS MARCO ranking benchmark, demonstrating its effectiveness and versatility.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.