 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCFNet: A Multimodal Collaborative Fusion Network for Fine-Grained Semantic Classification
May 29, 2025



Multimodal information processing has become increasingly important for enhancing image classification performance. However, the intricate and implicit dependencies across different modalities often hinder conventional methods from effectively capturing fine-grained semantic interactions, thereby limiting their applicability in high-precision classification tasks. To address this issue, we propose a novel Multimodal Collaborative Fusion Network (MCFNet) designed for fine-grained classification. The proposed MCFNet architecture incorporates a regularized integrated fusion module that improves intra-modal feature representation through modality-specific regularization strategies, while facilitating precise semantic alignment via a hybrid attention mechanism. Additionally, we introduce a multimodal decision classification module, which jointly exploits inter-modal correlations and unimodal discriminative features by integrating multiple loss functions within a weighted voting paradigm. Extensive experiments and ablation studies on benchmark datasets demonstrate that the proposed MCFNet framework achieves consistent improvements in classification accuracy, confirming its effectiveness in modeling subtle cross-modal semantics.
Pre-trained Language Models can be Fully Zero-Shot Learners
Dec 14, 2022



How can we extend a pre-trained model to many language understanding tasks, without labeled or additional unlabeled data? Pre-trained language models (PLMs) have been effective for a wide range of NLP tasks. However, existing approaches either require fine-tuning on downstream labeled datasets or manually constructing proper prompts. In this paper, we propose nonparametric prompting PLM (NPPrompt) for fully zero-shot language understanding. Unlike previous methods, NPPrompt uses only pre-trained language models and does not require any labeled data or additional raw corpus for further fine-tuning, nor does it rely on humans to construct a comprehensive set of prompt label words. We evaluate NPPrompt against previous major few-shot and zero-shot learning methods on diverse NLP tasks: including text classification, text entailment, similar text retrieval, and paraphrasing. Experimental results demonstrate that our NPPrompt outperforms the previous best fully zero-shot method by big margins, with absolute gains of 12.8% in accuracy on text classification and 18.9% on the GLUE benchmark.
Photonic sampled and quantized analog-to-digital converters on thin-film lithium niobate platform
Jul 28, 2022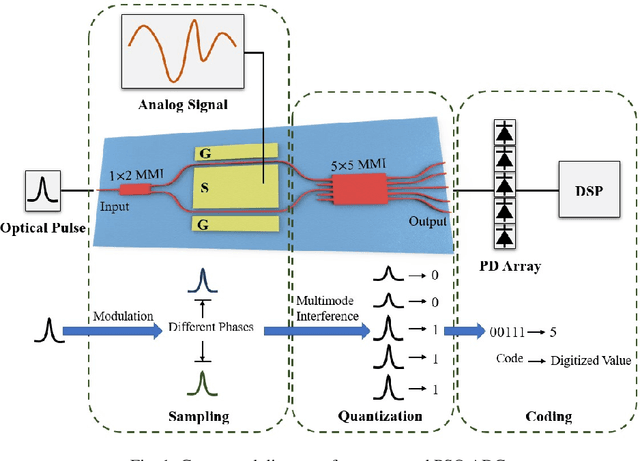
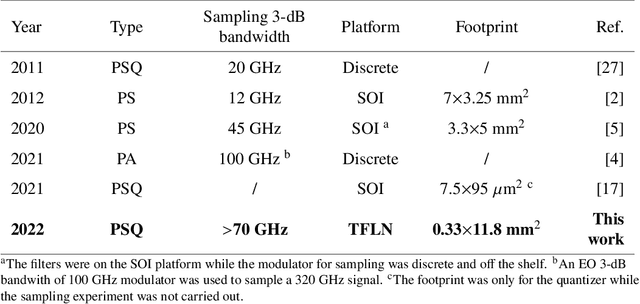

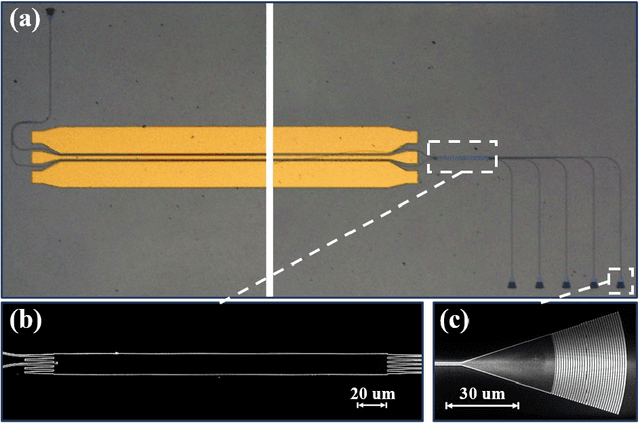
In this paper, an on-chip photonic sampled and quantized analog-to-digital converter (ADC) on thin-film lithium niobate platform is experimentally demonstrated. Using two phase modulators as a sampler and a 5$\times$5 multimode interference (MMI) coupler as a quantizer, an 1 GHz sinusoidal analog input signal was successfully converted to a digitized output with a 20 GSample/s sampling rate. To evaluate the system performance, the quantization curves together with the transfer function of the ADC were measured. The experimental effective number of bits (ENOB) was 3.17 bit. The demonstrated device is capable of operating at a high frequency up to 70 GHz, making it a promising solution for on-chip ultra-high speed analog-to-digital conversion.
Compressing Sentence Representation for Semantic Retrieval via Homomorphic Projective Distillation
Mar 15, 2022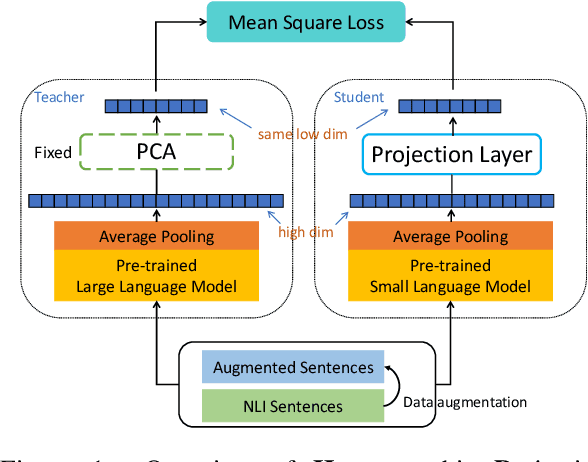
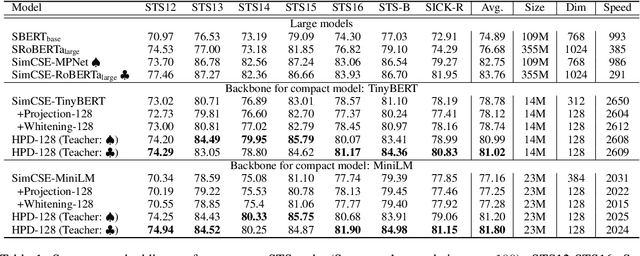
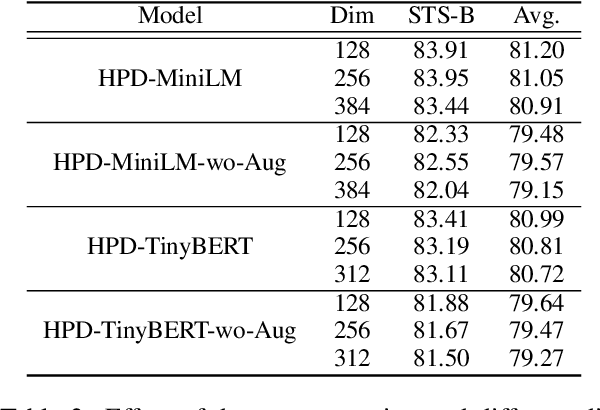

How to learn highly compact yet effective sentence representation? Pre-trained language models have been effective in many NLP tasks. However, these models are often huge and produce large sentence embeddings. Moreover, there is a big performance gap between large and small models. In this paper, we propose Homomorphic Projective Distillation (HPD) to learn compressed sentence embeddings. Our method augments a small Transformer encoder model with learnable projection layers to produce compact representations while mimicking a large pre-trained language model to retain the sentence representation quality. We evaluate our method with different model sizes on both semantic textual similarity (STS) and semantic retrieval (SR) tasks. Experiments show that our method achieves 2.7-4.5 points performance gain on STS tasks compared with previous best representations of the same size. In SR tasks, our method improves retrieval speed (8.2$\times$) and memory usage (8.0$\times$) compared with state-of-the-art large models.
Retrofitting Concept Vector Representations of Medical Concepts to Improve Estimates of Semantic Similarity and Relatedness
Sep 21, 2017
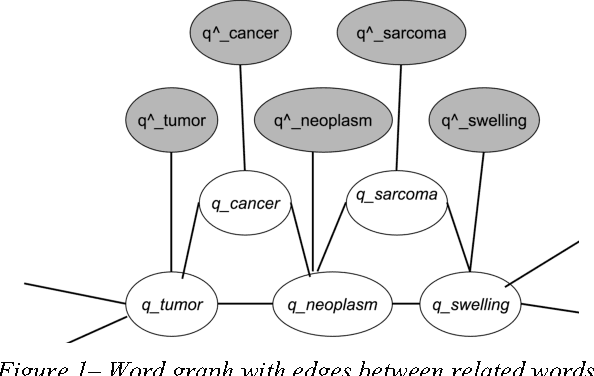
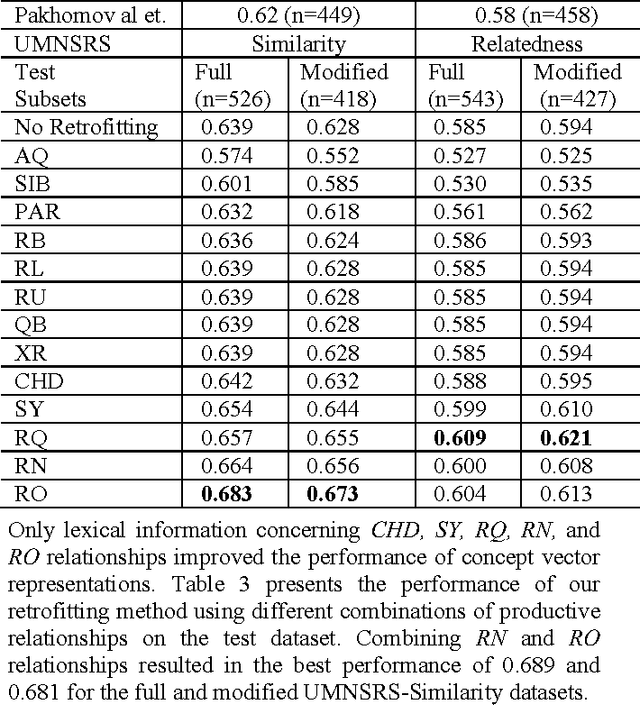
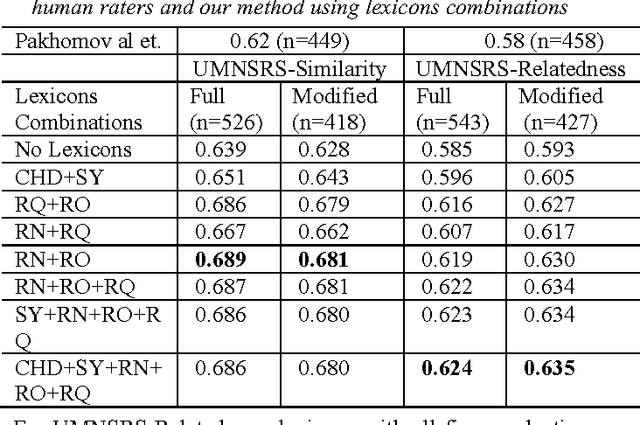
Estimation of semantic similarity and relatedness between biomedical concepts has utility for many informatics applications. Automated methods fall into two categories: methods based on distributional statistics drawn from text corpora, and methods using the structure of existing knowledge resources. Methods in the former category disregard taxonomic structure, while those in the latter fail to consider semantically relevant empirical information. In this paper, we present a method that retrofits distributional context vector representations of biomedical concepts using structural information from the UMLS Metathesaurus, such that the similarity between vector representations of linked concepts is augmented. We evaluated it on the UMNSRS benchmark. Our results demonstrate that retrofitting of concept vector representations leads to better correlation with human raters for both similarity and relatedness, surpassing the best results reported to date. They also demonstrate a clear improvement in performance on this reference standard for retrofitted vector representations, as compared to those without retrofitting.