 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking for Deep Uplift Modeling in Online Marketing
Paper and Code
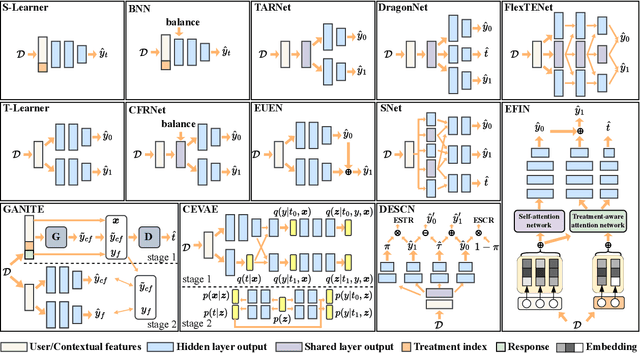



Online marketing is critical for many industrial platforms and business applications, aiming to increase user engagement and platform revenue by identifying corresponding delivery-sensitive groups for specific incentives, such as coupons and bonuses. As the scale and complexity of features in industrial scenarios increase, deep uplift modeling (DUM) as a promising technique has attracted increased research from academia and industry, resulting in various predictive models. However, current DUM still lacks some standardized benchmarks and unified evaluation protocols, which limit the reproducibility of experimental results in existing studies and the practical value and potential impact in this direction. In this paper, we provide an open benchmark for DUM and present comparison results of existing models in a reproducible and uniform manner. To this end, we conduct extensive experiments on two representative industrial datasets with different preprocessing settings to re-evaluate 13 existing models. Surprisingly, our experimental results show that the most recent work differs less than expected from traditional work in many cases. In addition, our experiments also reveal the limitations of DUM in generalization, especially for different preprocessing and test distributions. Our benchmarking work allows researchers to evaluate the performance of new models quickly but also reasonably demonstrates fair comparison results with existing models. It also gives practitioners valuable insights into often overlooked considerations when deploying DUM. We will make this benchmarking library, evaluation protocol, and experimental setup available on GitHub.