 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParametric Pareto Set Learning for Expensive Multi-Objective Optimization
Nov 08, 2025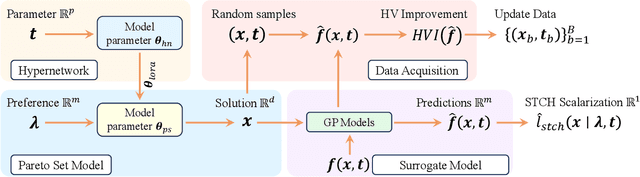
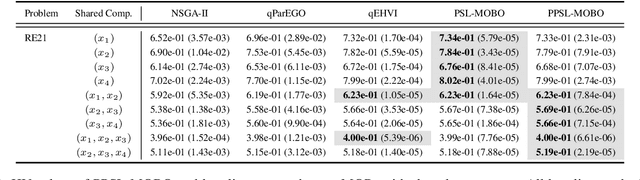
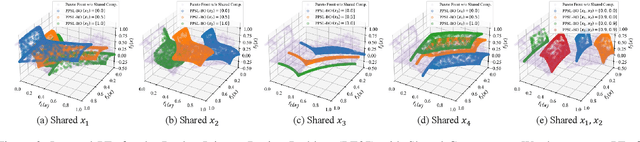
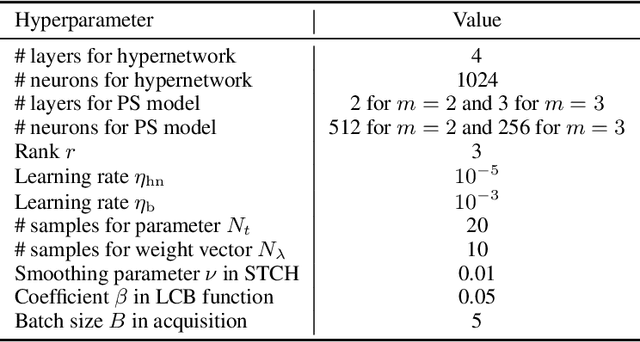
Parametric multi-objective optimization (PMO) addresses the challenge of solving an infinite family of multi-objective optimization problems, where optimal solutions must adapt to varying parameters. Traditional methods require re-execution for each parameter configuration, leading to prohibitive costs when objective evaluations are computationally expensive. To address this issue, we propose Parametric Pareto Set Learning with multi-objective Bayesian Optimization (PPSL-MOBO), a novel framework that learns a unified mapping from both preferences and parameters to Pareto-optimal solutions. PPSL-MOBO leverages a hypernetwork with Low-Rank Adaptation (LoRA) to efficiently capture parametric variations, while integrating Gaussian process surrogates and hypervolume-based acquisition to minimize expensive function evaluations. We demonstrate PPSL-MOBO's effectiveness on two challenging applications: multi-objective optimization with shared components, where certain design variables must be identical across solution families due to modular constraints, and dynamic multi-objective optimization, where objectives evolve over time. Unlike existing methods that cannot directly solve PMO problems in a unified manner, PPSL-MOBO learns a single model that generalizes across the entire parameter space. By enabling instant inference of Pareto sets for new parameter values without retraining, PPSL-MOBO provides an efficient solution for expensive PMO problems.
Practical multi-fidelity machine learning: fusion of deterministic and Bayesian models
Jul 21, 2024Multi-fidelity machine learning methods address the accuracy-efficiency trade-off by integrating scarce, resource-intensive high-fidelity data with abundant but less accurate low-fidelity data. We propose a practical multi-fidelity strategy for problems spanning low- and high-dimensional domains, integrating a non-probabilistic regression model for the low-fidelity with a Bayesian model for the high-fidelity. The models are trained in a staggered scheme, where the low-fidelity model is transfer-learned to the high-fidelity data and a Bayesian model is trained for the residual. This three-model strategy -- deterministic low-fidelity, transfer learning, and Bayesian residual -- leads to a prediction that includes uncertainty quantification both for noisy and noiseless multi-fidelity data. The strategy is general and unifies the topic, highlighting the expressivity trade-off between the transfer-learning and Bayesian models (a complex transfer-learning model leads to a simpler Bayesian model, and vice versa). We propose modeling choices for two scenarios, and argue in favor of using a linear transfer-learning model that fuses 1) kernel ridge regression for low-fidelity with Gaussian processes for high-fidelity; or 2) deep neural network for low-fidelity with a Bayesian neural network for high-fidelity. We demonstrate the effectiveness and efficiency of the proposed strategies and contrast them with the state-of-the-art based on various numerical examples. The simplicity of these formulations makes them practical for a broad scope of future engineering applications.
Provably Neural Active Learning Succeeds via Prioritizing Perplexing Samples
Jun 06, 2024Neural Network-based active learning (NAL) is a cost-effective data selection technique that utilizes neural networks to select and train on a small subset of samples. While existing work successfully develops various effective or theory-justified NAL algorithms, the understanding of the two commonly used query criteria of NAL: uncertainty-based and diversity-based, remains in its infancy. In this work, we try to move one step forward by offering a unified explanation for the success of both query criteria-based NAL from a feature learning view. Specifically, we consider a feature-noise data model comprising easy-to-learn or hard-to-learn features disrupted by noise, and conduct analysis over 2-layer NN-based NALs in the pool-based scenario. We provably show that both uncertainty-based and diversity-based NAL are inherently amenable to one and the same principle, i.e., striving to prioritize samples that contain yet-to-be-learned features. We further prove that this shared principle is the key to their success-achieve small test error within a small labeled set. Contrastingly, the strategy-free passive learning exhibits a large test error due to the inadequate learning of yet-to-be-learned features, necessitating resort to a significantly larger label complexity for a sufficient test error reduction. Experimental results validate our findings.
Diffusion-based Contrastive Learning for Sequential Recommendation
May 15, 2024



Contrastive learning has been effectively applied to alleviate the data sparsity issue and enhance recommendation performance.The majority of existing methods employ random augmentation to generate augmented views of original sequences. The learning objective then aims to minimize the distance between representations of different views for the same user. However, these random augmentation strategies (e.g., mask or substitution) neglect the semantic consistency of different augmented views for the same user, leading to semantically inconsistent sequences with similar representations. Furthermore, most augmentation methods fail to utilize context information, which is critical for understanding sequence semantics. To address these limitations, we introduce a diffusion-based contrastive learning approach for sequential recommendation. Specifically, given a user sequence, we first select some positions and then leverage context information to guide the generation of alternative items via a guided diffusion model. By repeating this approach, we can get semantically consistent augmented views for the same user, which are used to improve the effectiveness of contrastive learning. To maintain cohesion between the representation spaces of both the diffusion model and the recommendation model, we train the entire framework in an end-to-end fashion with shared item embeddings. Extensive experiments on five benchmark datasets demonstrate the superiority of our proposed method.
Evolve Cost-aware Acquisition Functions Using Large Language Models
Apr 25, 2024Many real-world optimization scenarios involve expensive evaluation with unknown and heterogeneous costs. Cost-aware Bayesian optimization stands out as a prominent solution in addressing these challenges. To approach the global optimum within a limited budget in a cost-efficient manner, the design of cost-aware acquisition functions (AFs) becomes a crucial step. However, traditional manual design paradigm typically requires extensive domain knowledge and involves a labor-intensive trial-and-error process. This paper introduces EvolCAF, a novel framework that integrates large language models (LLMs) with evolutionary computation (EC) to automatically design cost-aware AFs. Leveraging the crossover and mutation in the algorithm space, EvolCAF offers a novel design paradigm, significantly reduces the reliance on domain expertise and model training. The designed cost-aware AF maximizes the utilization of available information from historical data, surrogate models and budget details. It introduces novel ideas not previously explored in the existing literature on acquisition function design, allowing for clear interpretations to provide insights into its behavior and decision-making process. In comparison to the well-known EIpu and EI-cool methods designed by human experts, our approach showcases remarkable efficiency and generalization across various tasks, including 12 synthetic problems and 3 real-world hyperparameter tuning test sets.