 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Few-Shot Early Rumor Detection with Imitation Agent
Dec 20, 2025Early Rumor Detection (EARD) aims to identify the earliest point at which a claim can be accurately classified based on a sequence of social media posts. This is especially challenging in data-scarce settings. While Large Language Models (LLMs) perform well in few-shot NLP tasks, they are not well-suited for time-series data and are computationally expensive for both training and inference. In this work, we propose a novel EARD framework that combines an autonomous agent and an LLM-based detection model, where the agent acts as a reliable decision-maker for \textit{early time point determination}, while the LLM serves as a powerful \textit{rumor detector}. This approach offers the first solution for few-shot EARD, necessitating only the training of a lightweight agent and allowing the LLM to remain training-free. Extensive experiments on four real-world datasets show our approach boosts performance across LLMs and surpasses existing EARD methods in accuracy and earliness.
New Recipe for Semi-supervised Community Detection: Clique Annealing under Crystallization Kinetics
Apr 22, 2025Semi-supervised community detection methods are widely used for identifying specific communities due to the label scarcity. Existing semi-supervised community detection methods typically involve two learning stages learning in both initial identification and subsequent adjustment, which often starts from an unreasonable community core candidate. Moreover, these methods encounter scalability issues because they depend on reinforcement learning and generative adversarial networks, leading to higher computational costs and restricting the selection of candidates. To address these limitations, we draw a parallel between crystallization kinetics and community detection to integrate the spontaneity of the annealing process into community detection. Specifically, we liken community detection to identifying a crystal subgrain (core) that expands into a complete grain (community) through a process similar to annealing. Based on this finding, we propose CLique ANNealing (CLANN), which applies kinetics concepts to community detection by integrating these principles into the optimization process to strengthen the consistency of the community core. Subsequently, a learning-free Transitive Annealer was employed to refine the first-stage candidates by merging neighboring cliques and repositioning the community core, enabling a spontaneous growth process that enhances scalability. Extensive experiments on \textbf{43} different network settings demonstrate that CLANN outperforms state-of-the-art methods across multiple real-world datasets, showcasing its exceptional efficacy and efficiency in community detection.
Proof-of-Data: A Consensus Protocol for Collaborative Intelligence
Jan 06, 2025



Existing research on federated learning has been focused on the setting where learning is coordinated by a centralized entity. Yet the greatest potential of future collaborative intelligence would be unleashed in a more open and democratized setting with no central entity in a dominant role, referred to as "decentralized federated learning". New challenges arise accordingly in achieving both correct model training and fair reward allocation with collective effort among all participating nodes, especially with the threat of the Byzantine node jeopardising both tasks. In this paper, we propose a blockchain-based decentralized Byzantine fault-tolerant federated learning framework based on a novel Proof-of-Data (PoD) consensus protocol to resolve both the "trust" and "incentive" components. By decoupling model training and contribution accounting, PoD is able to enjoy not only the benefit of learning efficiency and system liveliness from asynchronous societal-scale PoW-style learning but also the finality of consensus and reward allocation from epoch-based BFT-style voting. To mitigate false reward claims by data forgery from Byzantine attacks, a privacy-aware data verification and contribution-based reward allocation mechanism is designed to complete the framework. Our evaluation results show that PoD demonstrates performance in model training close to that of the centralized counterpart while achieving trust in consensus and fairness for reward allocation with a fault tolerance ratio of 1/3.
Modeling of UV NLoS Communication Channels: From Atmospheric Scattering and Obstacle Reflection Perspectives
Nov 08, 2024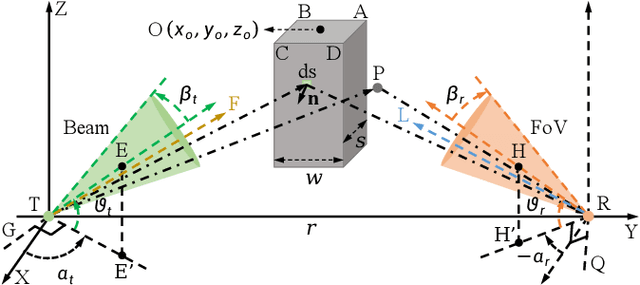
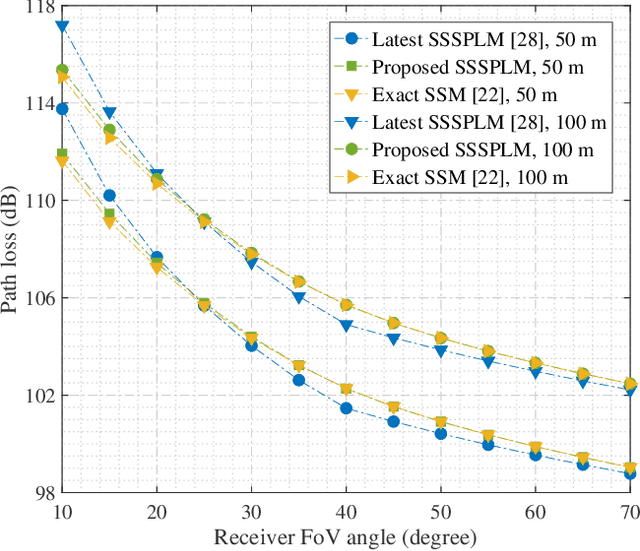
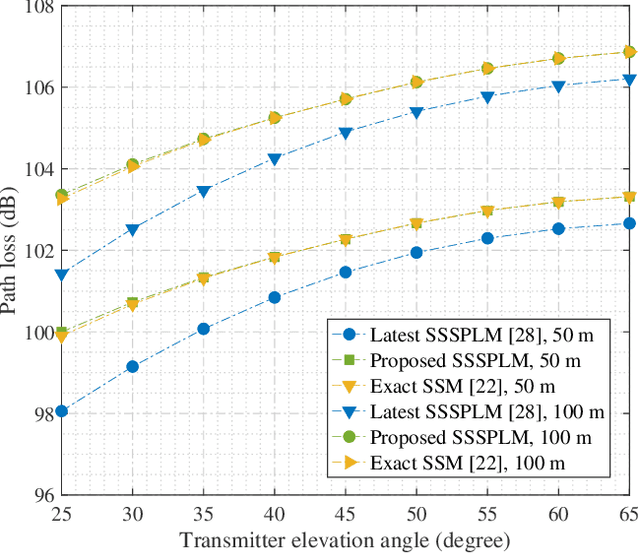
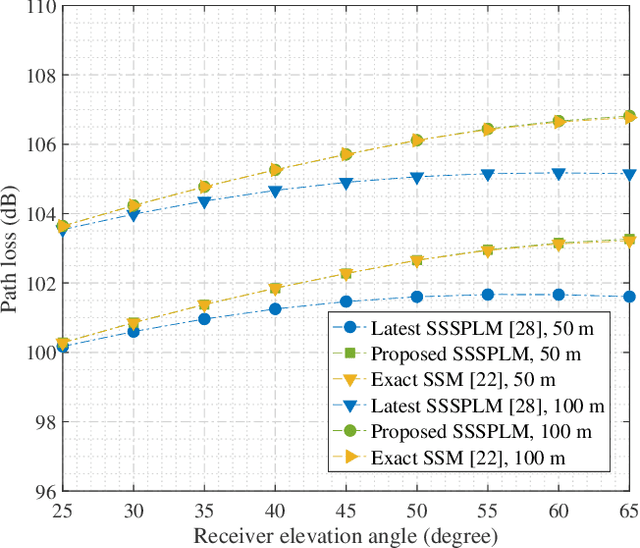
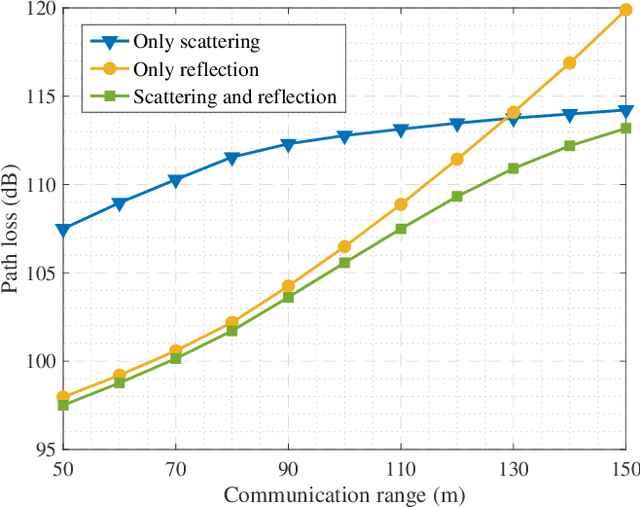
As transceiver elevation angles increase from small to large, existing ultraviolet (UV) non-line-of-sight (NLoS) models encounter two challenges: i) cannot estimate the channel characteristics of UV NLoS communication scenarios when there exists an obstacle in the overlap volume between the transmitter beam and the receiver field-of-view (FoV), and ii) cannot evaluate the channel path loss for the wide beam and wide FoV scenarios with existing simplified single-scattering path loss models. To address these challenges, a UV NLoS scattering model incorporating an obstacle was investigated, where the obstacle's orientation angle, coordinates, and geometric dimensions were taken into account to approach actual application environments. Then, a UV NLoS reflection model was developed combined with specific geometric diagrams. Further, a simplified single-scattering path loss model was proposed with a closed-form expression. Finally, the proposed models were validated by comparing them with the Monte-Carlo photon-tracing model, the exact single-scattering model, and the latest simplified single-scattering model. Numerical results show that the path loss curves obtained by the proposed models agree well with those attained by related NLoS models under identical parameter settings, and avoiding obstacles is not always a good option for UV NLoS communications. Moreover, the accuracy of the proposed simplified model is superior to that of the existing simplified model for all kinds of transceiver FoV angles.
Single-Collision Model for Non-Line-of-Sight UV Communication Channel With Obstacle
Nov 08, 2024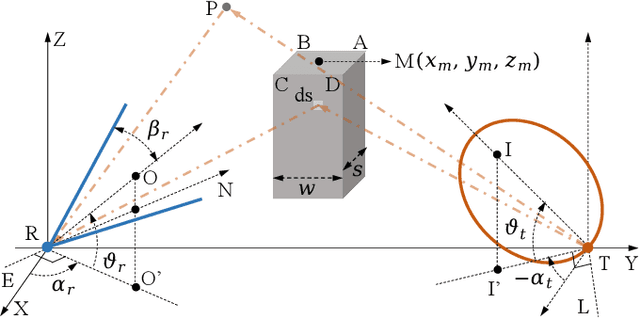

Existing research on non-line-of-sight (NLoS) ultraviolet (UV) channel modeling mainly focuses on scenarios where the signal propagation process is not affected by any obstacle and the radiation intensity (RI) of the light source is uniformly distributed. To eliminate these restrictions, we propose a single-collision model for the NLoS UV channel incorporating a cuboid-shaped obstacle, where the RI of the UV light source is modeled as the Lambertian distribution. For easy interpretation, we categorize the intersection circumstances between the receiver field-of-view and the obstacle into six cases and provide derivations of the weighting factor for each case. To investigate the accuracy of the proposed model, we compare it with the associated Monte Carlo photon tracing model via simulations and experiments. Results verify the correctness of the proposed model. This work reveals that obstacle avoidance is not always beneficial for NLoS UV communications and provides guidelines for relevant system design.
Channel Modeling for Ultraviolet Non-Line-of-Sight Communications Incorporating an Obstacle
Nov 08, 2024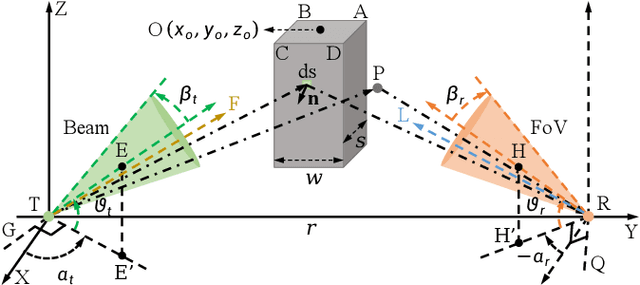
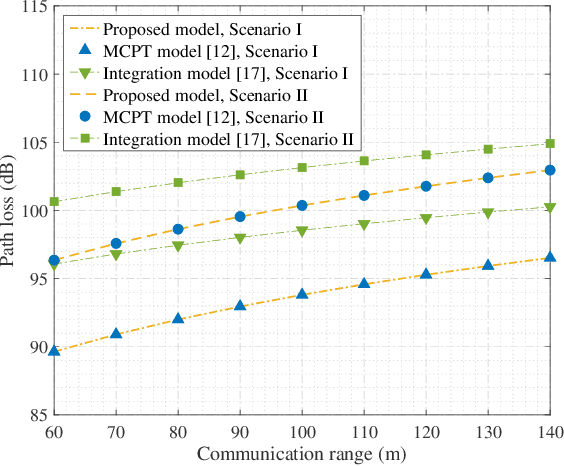
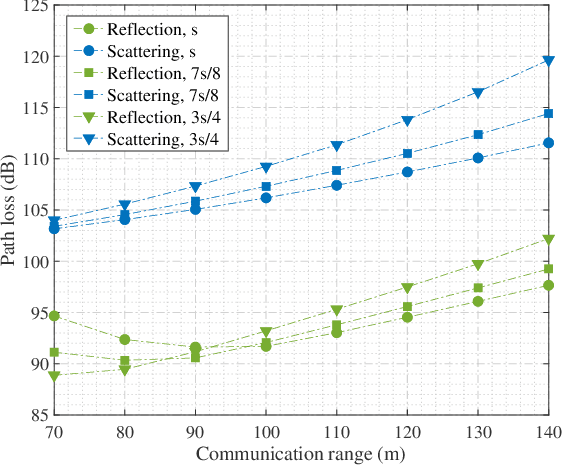

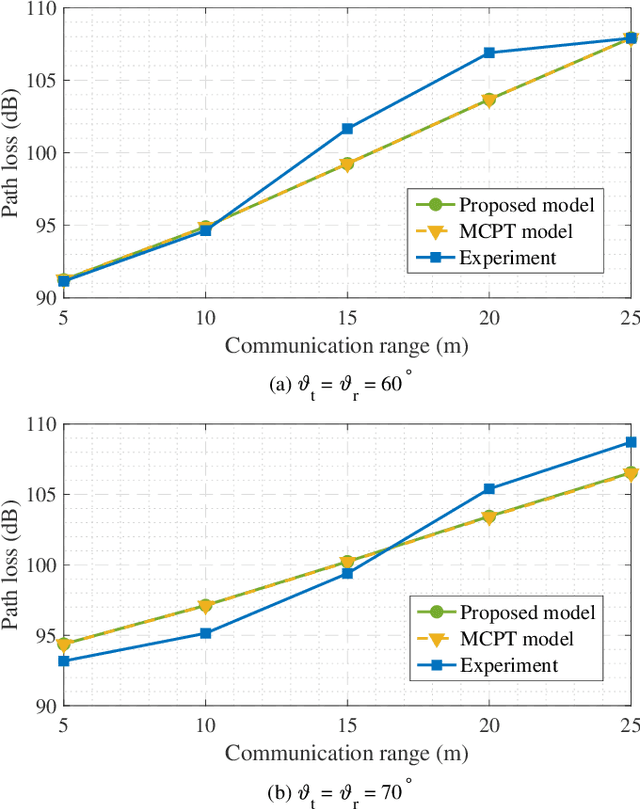
Existing studies on ultraviolet (UV) non-line-of-sight (NLoS) channel modeling primarily focus on scenarios without any obstacle, which makes them unsuitable for small transceiver elevation angles in most cases. To address this issue, a UV NLoS channel model incorporating an obstacle was investigated in this paper, where the impacts of atmospheric scattering and obstacle reflection on UV signals were both taken into account. To validate the proposed model, we compared it to the related Monte-Carlo photon-tracing (MCPT) model that had been verified by outdoor experiments. Numerical results manifest that the path loss curves obtained by the proposed model agree well with those determined by the MCPT model, while its computation complexity is lower than that of the MCPT model. This work discloses that obstacle reflection can effectively reduce the channel path loss of UV NLoS communication systems.
Crafting a Good Prompt or Providing Exemplary Dialogues? A Study of In-Context Learning for Persona-based Dialogue Generation
Feb 17, 2024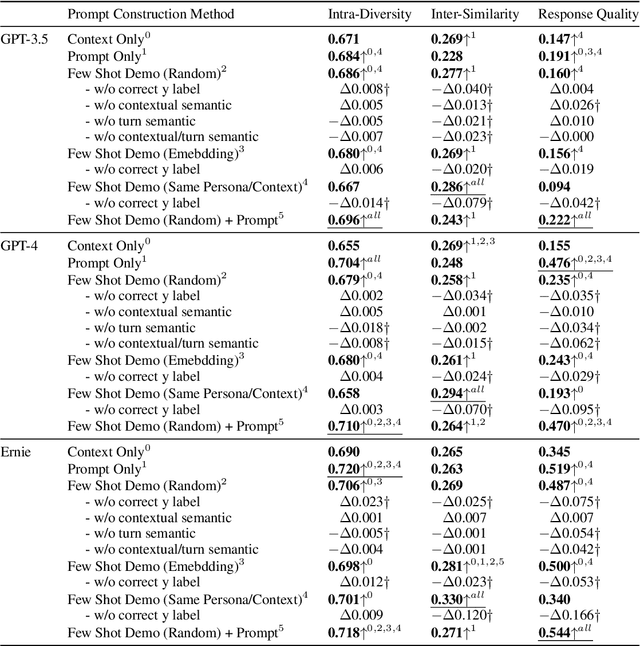
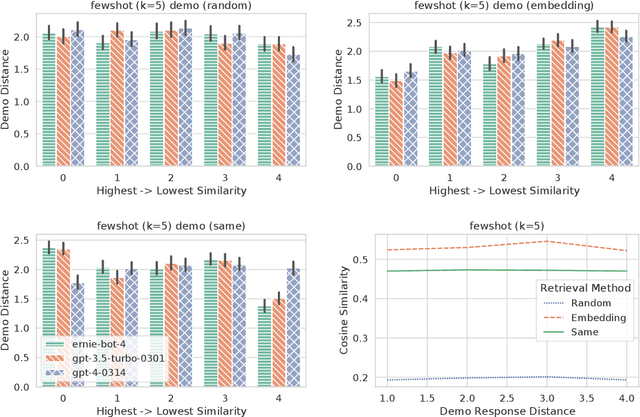
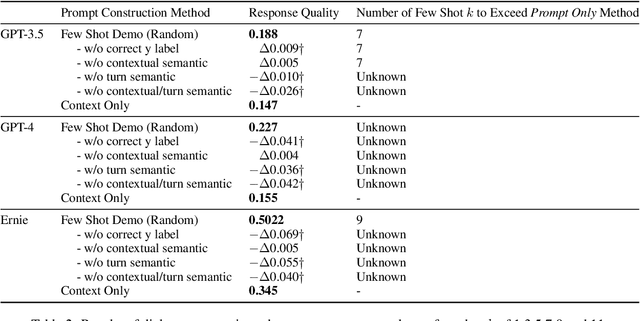
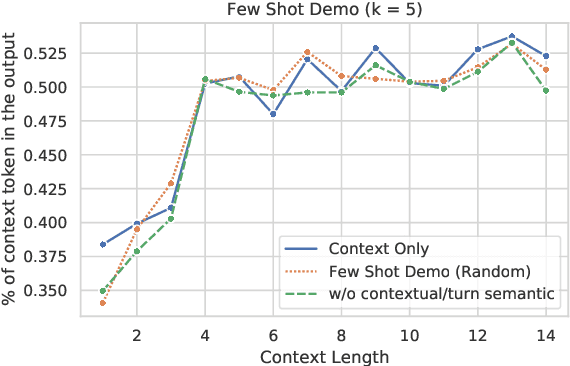
Previous in-context learning (ICL) research has focused on tasks such as classification, machine translation, text2table, etc., while studies on whether ICL can improve human-like dialogue generation are scarce. Our work fills this gap by systematically investigating the ICL capabilities of large language models (LLMs) in persona-based dialogue generation, conducting extensive experiments on high-quality real human Chinese dialogue datasets. From experimental results, we draw three conclusions: 1) adjusting prompt instructions is the most direct, effective, and economical way to improve generation quality; 2) randomly retrieving demonstrations (demos) achieves the best results, possibly due to the greater diversity and the amount of effective information; counter-intuitively, retrieving demos with a context identical to the query performs the worst; 3) even when we destroy the multi-turn associations and single-turn semantics in the demos, increasing the number of demos still improves dialogue performance, proving that LLMs can learn from corrupted dialogue demos. Previous explanations of the ICL mechanism, such as $n$-gram induction head, cannot fully account for this phenomenon.
From Asset Flow to Status, Action and Intention Discovery: Early Malice Detection in Cryptocurrency
Sep 26, 2023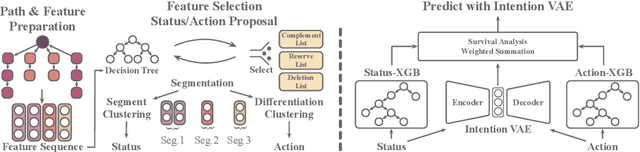
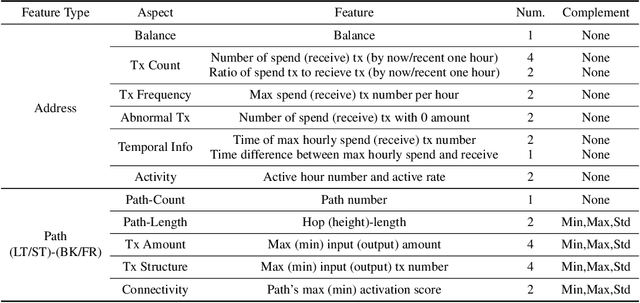
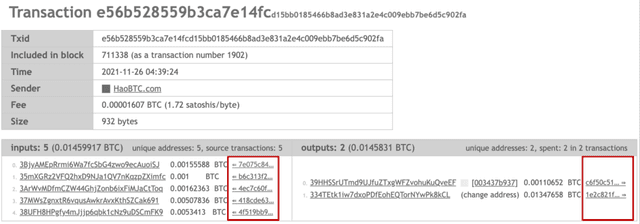
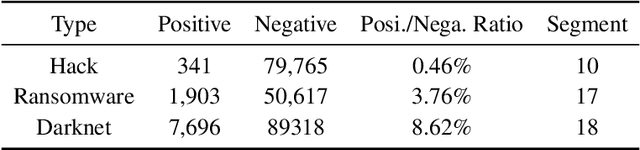
Cryptocurrency has been subject to illicit activities probably more often than traditional financial assets due to the pseudo-anonymous nature of its transacting entities. An ideal detection model is expected to achieve all three critical properties of (I) early detection, (II) good interpretability, and (III) versatility for various illicit activities. However, existing solutions cannot meet all these requirements, as most of them heavily rely on deep learning without interpretability and are only available for retrospective analysis of a specific illicit type. To tackle all these challenges, we propose Intention-Monitor for early malice detection in Bitcoin (BTC), where the on-chain record data for a certain address are much scarcer than other cryptocurrency platforms. We first define asset transfer paths with the Decision-Tree based feature Selection and Complement (DT-SC) to build different feature sets for different malice types. Then, the Status/Action Proposal Module (S/A-PM) and the Intention-VAE module generate the status, action, intent-snippet, and hidden intent-snippet embedding. With all these modules, our model is highly interpretable and can detect various illegal activities. Moreover, well-designed loss functions further enhance the prediction speed and model's interpretability. Extensive experiments on three real-world datasets demonstrate that our proposed algorithm outperforms the state-of-the-art methods. Furthermore, additional case studies justify our model can not only explain existing illicit patterns but can also find new suspicious characters.
Examining the Effect of Pre-training on Time Series Classification
Sep 11, 2023Although the pre-training followed by fine-tuning paradigm is used extensively in many fields, there is still some controversy surrounding the impact of pre-training on the fine-tuning process. Currently, experimental findings based on text and image data lack consensus. To delve deeper into the unsupervised pre-training followed by fine-tuning paradigm, we have extended previous research to a new modality: time series. In this study, we conducted a thorough examination of 150 classification datasets derived from the Univariate Time Series (UTS) and Multivariate Time Series (MTS) benchmarks. Our analysis reveals several key conclusions. (i) Pre-training can only help improve the optimization process for models that fit the data poorly, rather than those that fit the data well. (ii) Pre-training does not exhibit the effect of regularization when given sufficient training time. (iii) Pre-training can only speed up convergence if the model has sufficient ability to fit the data. (iv) Adding more pre-training data does not improve generalization, but it can strengthen the advantage of pre-training on the original data volume, such as faster convergence. (v) While both the pre-training task and the model structure determine the effectiveness of the paradigm on a given dataset, the model structure plays a more significant role.
Evolve Path Tracer: Early Detection of Malicious Addresses in Cryptocurrency
Jan 13, 2023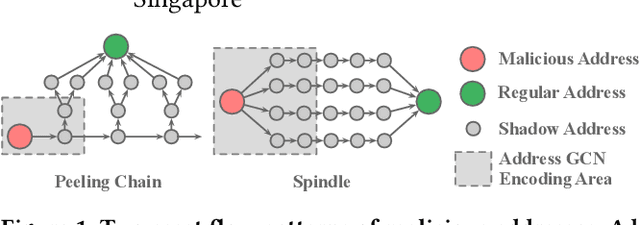
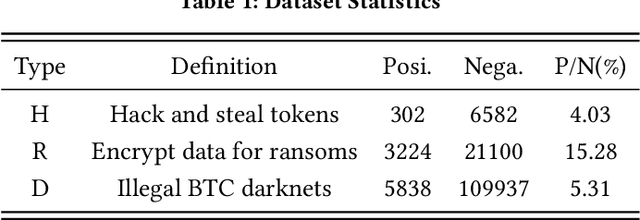
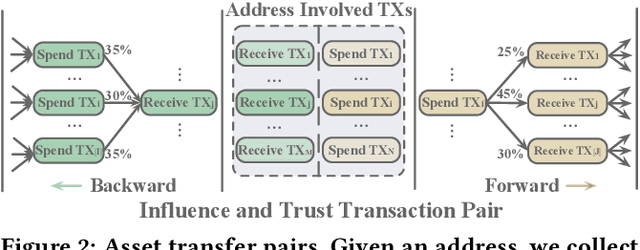
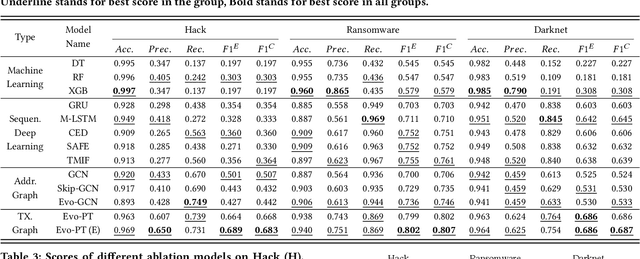
With the ever-increasing boom of Cryptocurrency, detecting fraudulent behaviors and associated malicious addresses draws significant research effort. However, most existing studies still rely on the full history features or full-fledged address transaction networks, thus cannot meet the requirements of early malicious address detection, which is urgent but seldom discussed by existing studies. To detect fraud behaviors of malicious addresses in the early stage, we present Evolve Path Tracer, which consists of Evolve Path Encoder LSTM, Evolve Path Graph GCN, and Hierarchical Survival Predictor. Specifically, in addition to the general address features, we propose asset transfer paths and corresponding path graphs to characterize early transaction patterns. Further, since the transaction patterns are changing rapidly during the early stage, we propose Evolve Path Encoder LSTM and Evolve Path Graph GCN to encode asset transfer path and path graph under an evolving structure setting. Hierarchical Survival Predictor then predicts addresses' labels with nice scalability and faster prediction speed. We investigate the effectiveness and versatility of Evolve Path Tracer on three real-world illicit bitcoin datasets. Our experimental results demonstrate that Evolve Path Tracer outperforms the state-of-the-art methods. Extensive scalability experiments demonstrate the model's adaptivity under a dynamic prediction setting.