 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Alignment Curse: Cross-Modality Jailbreak Transfer in Omni-Models
Jan 30, 2026Recent advances in end-to-end trained omni-models have significantly improved multimodal understanding. At the same time, safety red-teaming has expanded beyond text to encompass audio-based jailbreak attacks. However, an important bridge between textual and audio jailbreaks remains underexplored. In this work, we study the cross-modality transfer of jailbreak attacks from text to audio, motivated by the semantic similarity between the two modalities and the maturity of textual jailbreak methods. We first analyze the connection between modality alignment and cross-modality jailbreak transfer, showing that strong alignment can inadvertently propagate textual vulnerabilities to the audio modality, which we term the alignment curse. Guided by this analysis, we conduct an empirical evaluation of textual jailbreaks, text-transferred audio jailbreaks, and existing audio-based jailbreaks on recent omni-models. Our results show that text-transferred audio jailbreaks perform comparably to, and often better than, audio-based jailbreaks, establishing them as simple yet powerful baselines for future audio red-teaming. We further demonstrate strong cross-model transferability and show that text-transferred audio attacks remain effective even under a stricter audio-only access threat model.
A Fragile Guardrail: Diffusion LLM's Safety Blessing and Its Failure Mode
Jan 30, 2026Diffusion large language models (D-LLMs) offer an alternative to autoregressive LLMs (AR-LLMs) and have demonstrated advantages in generation efficiency. Beyond the utility benefits, we argue that D-LLMs exhibit a previously underexplored safety blessing: their diffusion-style generation confers intrinsic robustness against jailbreak attacks originally designed for AR-LLMs. In this work, we provide an initial analysis of the underlying mechanism, showing that the diffusion trajectory induces a stepwise reduction effect that progressively suppresses unsafe generations. This robustness, however, is not absolute. We identify a simple yet effective failure mode, termed context nesting, where harmful requests are embedded within structured benign contexts, effectively bypassing the stepwise reduction mechanism. Empirically, we show that this simple strategy is sufficient to bypass D-LLMs' safety blessing, achieving state-of-the-art attack success rates across models and benchmarks. Most notably, it enables the first successful jailbreak of Gemini Diffusion, to our knowledge, exposing a critical vulnerability in commercial D-LLMs. Together, our results characterize both the origins and the limits of D-LLMs' safety blessing, constituting an early-stage red-teaming of D-LLMs.
DeepfakeBench-MM: A Comprehensive Benchmark for Multimodal Deepfake Detection
Oct 26, 2025The misuse of advanced generative AI models has resulted in the widespread proliferation of falsified data, particularly forged human-centric audiovisual content, which poses substantial societal risks (e.g., financial fraud and social instability). In response to this growing threat, several works have preliminarily explored countermeasures. However, the lack of sufficient and diverse training data, along with the absence of a standardized benchmark, hinder deeper exploration. To address this challenge, we first build Mega-MMDF, a large-scale, diverse, and high-quality dataset for multimodal deepfake detection. Specifically, we employ 21 forgery pipelines through the combination of 10 audio forgery methods, 12 visual forgery methods, and 6 audio-driven face reenactment methods. Mega-MMDF currently contains 0.1 million real samples and 1.1 million forged samples, making it one of the largest and most diverse multimodal deepfake datasets, with plans for continuous expansion. Building on it, we present DeepfakeBench-MM, the first unified benchmark for multimodal deepfake detection. It establishes standardized protocols across the entire detection pipeline and serves as a versatile platform for evaluating existing methods as well as exploring novel approaches. DeepfakeBench-MM currently supports 5 datasets and 11 multimodal deepfake detectors. Furthermore, our comprehensive evaluations and in-depth analyses uncover several key findings from multiple perspectives (e.g., augmentation, stacked forgery). We believe that DeepfakeBench-MM, together with our large-scale Mega-MMDF, will serve as foundational infrastructures for advancing multimodal deepfake detection.
Channel Modeling for Ultraviolet Non-Line-of-Sight Communications Incorporating an Obstacle
Nov 08, 2024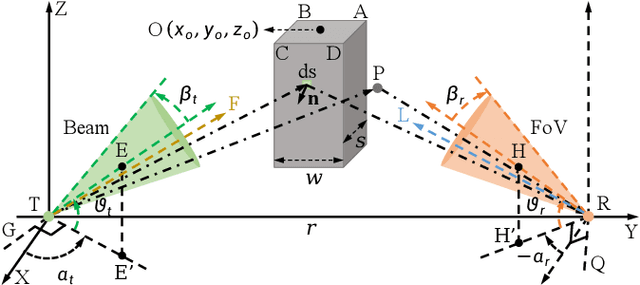

Existing studies on ultraviolet (UV) non-line-of-sight (NLoS) channel modeling primarily focus on scenarios without any obstacle, which makes them unsuitable for small transceiver elevation angles in most cases. To address this issue, a UV NLoS channel model incorporating an obstacle was investigated in this paper, where the impacts of atmospheric scattering and obstacle reflection on UV signals were both taken into account. To validate the proposed model, we compared it to the related Monte-Carlo photon-tracing (MCPT) model that had been verified by outdoor experiments. Numerical results manifest that the path loss curves obtained by the proposed model agree well with those determined by the MCPT model, while its computation complexity is lower than that of the MCPT model. This work discloses that obstacle reflection can effectively reduce the channel path loss of UV NLoS communication systems.
Modeling of UV NLoS Communication Channels: From Atmospheric Scattering and Obstacle Reflection Perspectives
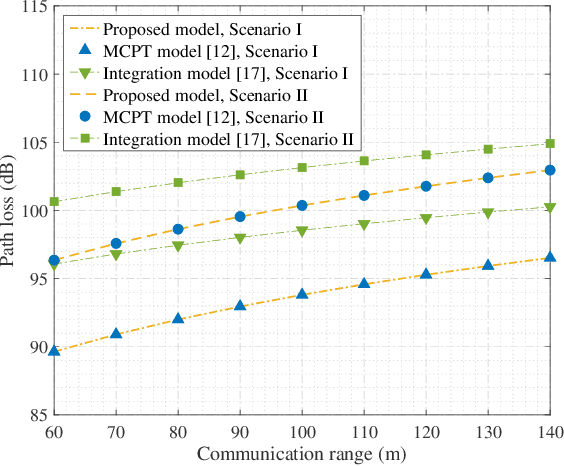
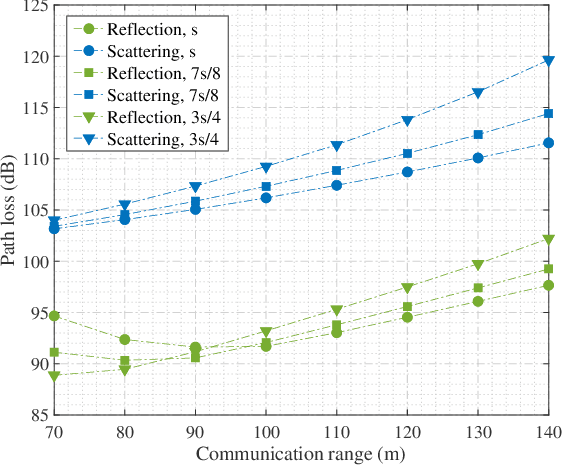
Nov 08, 2024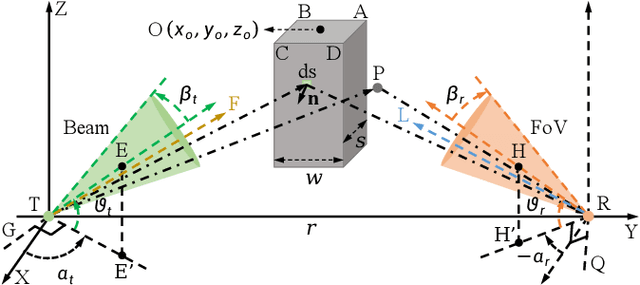
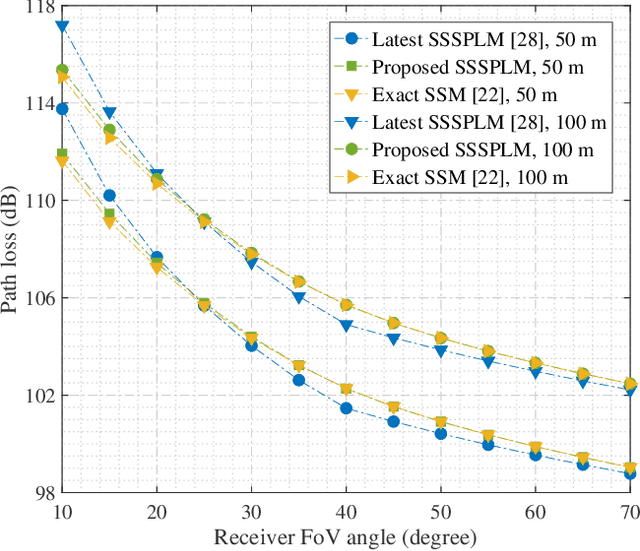
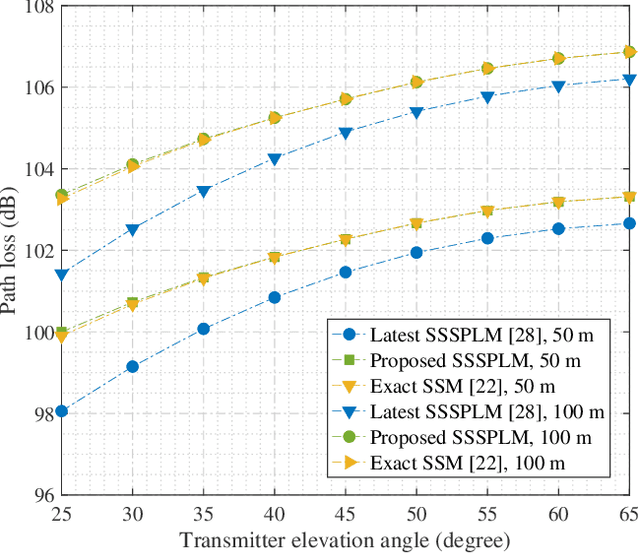
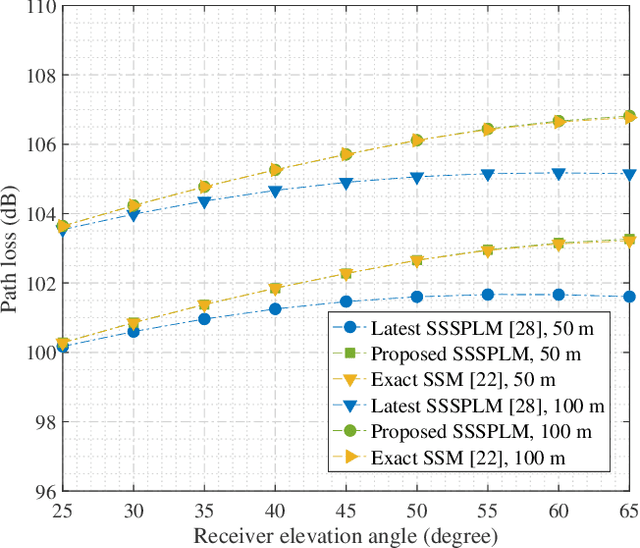
As transceiver elevation angles increase from small to large, existing ultraviolet (UV) non-line-of-sight (NLoS) models encounter two challenges: i) cannot estimate the channel characteristics of UV NLoS communication scenarios when there exists an obstacle in the overlap volume between the transmitter beam and the receiver field-of-view (FoV), and ii) cannot evaluate the channel path loss for the wide beam and wide FoV scenarios with existing simplified single-scattering path loss models. To address these challenges, a UV NLoS scattering model incorporating an obstacle was investigated, where the obstacle's orientation angle, coordinates, and geometric dimensions were taken into account to approach actual application environments. Then, a UV NLoS reflection model was developed combined with specific geometric diagrams. Further, a simplified single-scattering path loss model was proposed with a closed-form expression. Finally, the proposed models were validated by comparing them with the Monte-Carlo photon-tracing model, the exact single-scattering model, and the latest simplified single-scattering model. Numerical results show that the path loss curves obtained by the proposed models agree well with those attained by related NLoS models under identical parameter settings, and avoiding obstacles is not always a good option for UV NLoS communications. Moreover, the accuracy of the proposed simplified model is superior to that of the existing simplified model for all kinds of transceiver FoV angles.
EditBoard: Towards A Comprehensive Evaluation Benchmark for Text-based Video Editing Models
Sep 15, 2024The rapid development of diffusion models has significantly advanced AI-generated content (AIGC), particularly in Text-to-Image (T2I) and Text-to-Video (T2V) generation. Text-based video editing, leveraging these generative capabilities, has emerged as a promising field, enabling precise modifications to videos based on text prompts. Despite the proliferation of innovative video editing models, there is a conspicuous lack of comprehensive evaluation benchmarks that holistically assess these models' performance across various dimensions. Existing evaluations are limited and inconsistent, typically summarizing overall performance with a single score, which obscures models' effectiveness on individual editing tasks. To address this gap, we propose EditBoard, the first comprehensive evaluation benchmark for text-based video editing models. EditBoard encompasses nine automatic metrics across four dimensions, evaluating models on four task categories and introducing three new metrics to assess fidelity. This task-oriented benchmark facilitates objective evaluation by detailing model performance and providing insights into each model's strengths and weaknesses. By open-sourcing EditBoard, we aim to standardize evaluation and advance the development of robust video editing models.
MoFO: Momentum-Filtered Optimizer for Mitigating Forgetting in LLM Fine-Tuning
Jul 31, 2024Recently, large language models (LLMs) have demonstrated remarkable capabilities in a wide range of tasks. Typically, an LLM is pre-trained on large corpora and subsequently fine-tuned on task-specific datasets. However, during fine-tuning, LLMs may forget the knowledge acquired in the pre-training stage, leading to a decline in general capabilities. To address this issue, we propose a new fine-tuning algorithm termed Momentum-Filtered Optimizer (MoFO). The key idea of MoFO is to iteratively select and update the model parameters with the largest momentum magnitudes. Compared to full-parameter training, MoFO achieves similar fine-tuning performance while keeping parameters closer to the pre-trained model, thereby mitigating knowledge forgetting. Unlike most existing methods for forgetting mitigation, MoFO combines the following two advantages. First, MoFO does not require access to pre-training data. This makes MoFO particularly suitable for fine-tuning scenarios where pre-training data is unavailable, such as fine-tuning checkpoint-only open-source LLMs. Second, MoFO does not alter the original loss function. This could avoid impairing the model performance on the fine-tuning tasks. We validate MoFO through rigorous convergence analysis and extensive experiments, demonstrating its superiority over existing methods in mitigating forgetting and enhancing fine-tuning performance.
PDHG-Unrolled Learning-to-Optimize Method for Large-Scale Linear Programming
Jun 04, 2024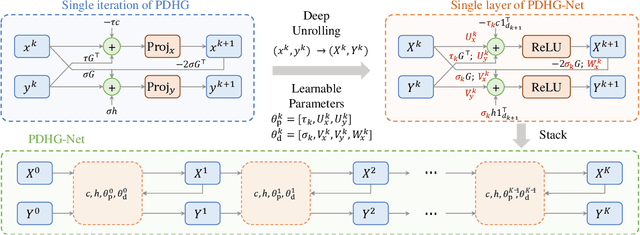
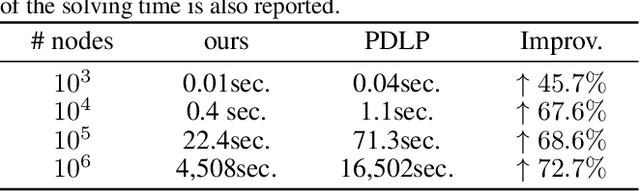
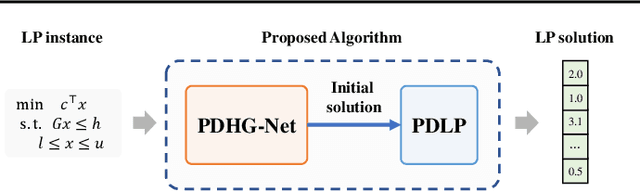
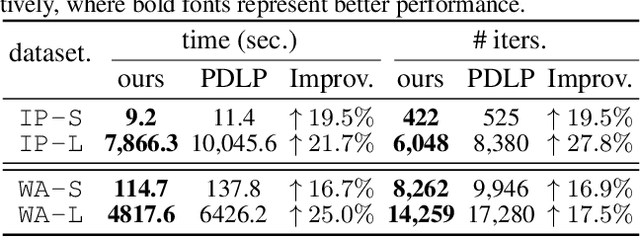
Solving large-scale linear programming (LP) problems is an important task in various areas such as communication networks, power systems, finance and logistics. Recently, two distinct approaches have emerged to expedite LP solving: (i) First-order methods (FOMs); (ii) Learning to optimize (L2O). In this work, we propose an FOM-unrolled neural network (NN) called PDHG-Net, and propose a two-stage L2O method to solve large-scale LP problems. The new architecture PDHG-Net is designed by unrolling the recently emerged PDHG method into a neural network, combined with channel-expansion techniques borrowed from graph neural networks. We prove that the proposed PDHG-Net can recover PDHG algorithm, thus can approximate optimal solutions of LP instances with a polynomial number of neurons. We propose a two-stage inference approach: first use PDHG-Net to generate an approximate solution, and then apply PDHG algorithm to further improve the solution. Experiments show that our approach can significantly accelerate LP solving, achieving up to a 3$\times$ speedup compared to FOMs for large-scale LP problems.
Ultraviolet Scattering Communication Using Subcarrier Intensity Modulation over Atmospheric Turbulence Channels
Dec 01, 2022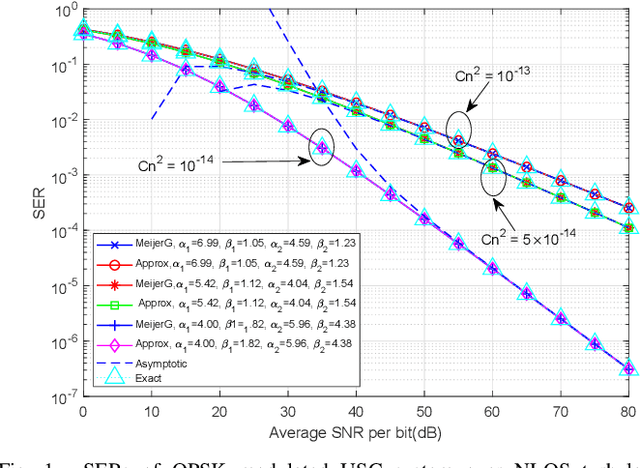
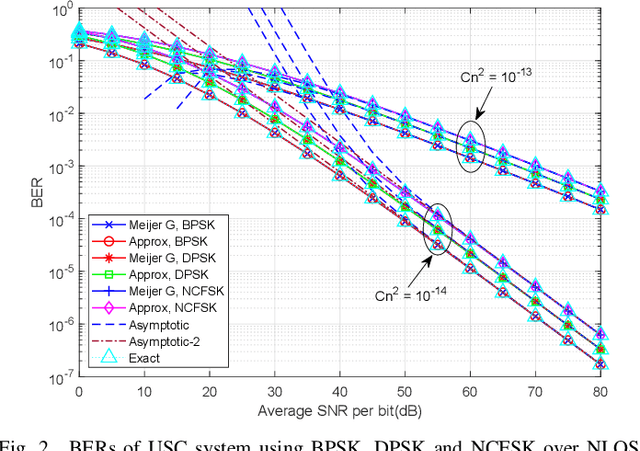
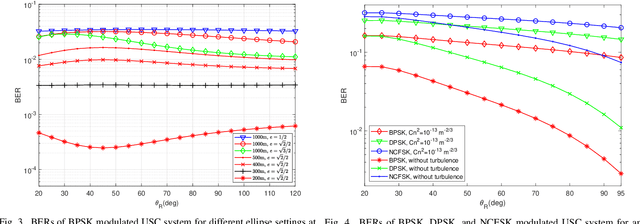
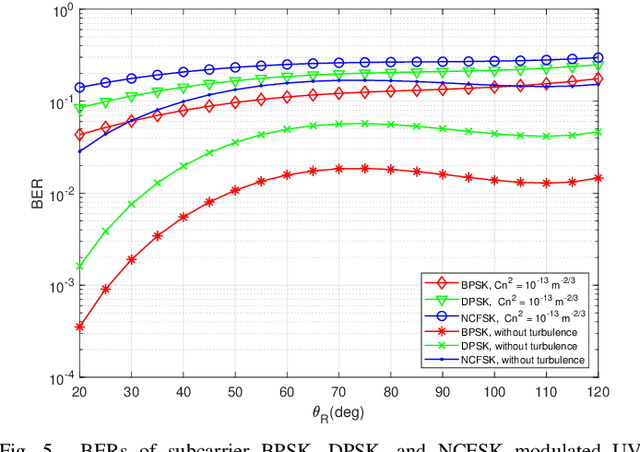
A closed-form non-line-of-sight (NLOS) turbulenceinduced fluctuation model is derived for ultraviolet scattering communication (USC), which models the received irradiance fluctuation by Meijer G function. Based on this model, we investigate the error rates of the USC system in NLOS case using different modulation techniques. Closed-form error rate results are derived by integration of Meijer G function. Inspired by the decomposition of different turbulence parameters, we use a series expansion of hypergeometric function and obtain the error rate expressions by the sum of four infinite series. The numerical results show that our error rate results are accurate in NLOS case. We also study the relationship between the turbulence influence and NLOS transceiver configurations. The numerical results show that when two-LOS link formulates the same distance, the turbulence influence is the strongest for long ranges and the weakest for short ranges.
An Unbiased Symmetric Matrix Estimator for Topology Inference under Partial Observability
Mar 29, 2022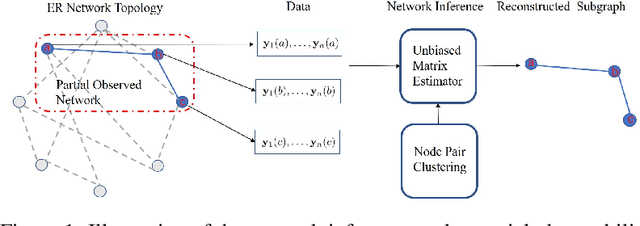

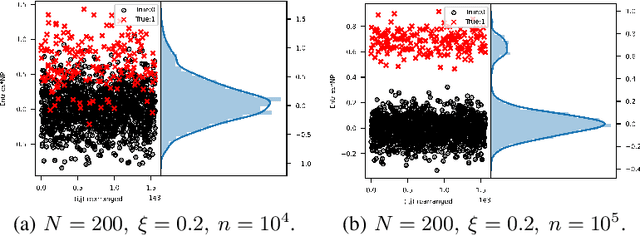
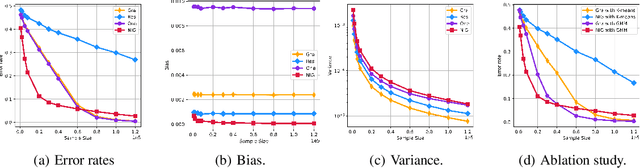
Network topology inference is a fundamental problem in many applications of network science, such as locating the source of fake news, brain connectivity networks detection, etc. Many real-world situations suffer from a critical problem that only a limited part of observations are available. This letter considers the problem of network topology inference under the framework of partial observability. Based on the vector autoregressive model, we propose a novel unbiased estimator for the symmetric network topology with the Gaussian noise and the Laplacian combination rule. Theoretically, we prove that it converges to the network combination matrix in probability. Furthermore, by utilizing the Gaussian mixture model algorithm, an effective algorithm called network inference Gauss algorithm is developed to infer the network structure. Finally, compared with the state-of-the-art methods, numerical experiments demonstrate the proposed algorithm enjoys better performance in the case of small sample sizes.