 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning based Degradation Representation for Blind Super-Resolution
Jul 28, 2022


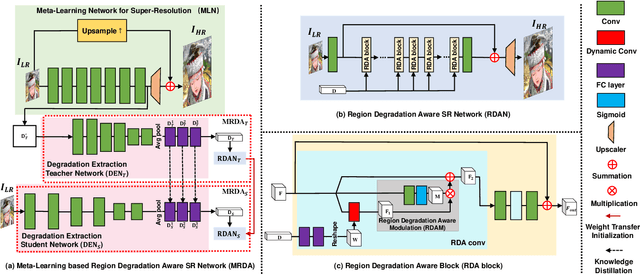
The most of CNN based super-resolution (SR) methods assume that the degradation is known (\eg, bicubic). These methods will suffer a severe performance drop when the degradation is different from their assumption. Therefore, some approaches attempt to train SR networks with the complex combination of multiple degradations to cover the real degradation space. To adapt to multiple unknown degradations, introducing an explicit degradation estimator can actually facilitate SR performance. However, previous explicit degradation estimation methods usually predict Gaussian blur with the supervision of groundtruth blur kernels, and estimation errors may lead to SR failure. Thus, it is necessary to design a method that can extract implicit discriminative degradation representation. To this end, we propose a Meta-Learning based Region Degradation Aware SR Network (MRDA), including Meta-Learning Network (MLN), Degradation Extraction Network (DEN), and Region Degradation Aware SR Network (RDAN). To handle the lack of groundtruth degradation, we use the MLN to rapidly adapt to the specific complex degradation after several iterations and extract implicit degradation information. Subsequently, a teacher network MRDA$_{T}$ is designed to further utilize the degradation information extracted by MLN for SR. However, MLN requires iterating on paired low-resolution (LR) and corresponding high-resolution (HR) images, which is unavailable in the inference phase. Therefore, we adopt knowledge distillation (KD) to make the student network learn to directly extract the same implicit degradation representation (IDR) as the teacher from LR images.
Residual Sparsity Connection Learning for Efficient Video Super-Resolution
Jun 15, 2022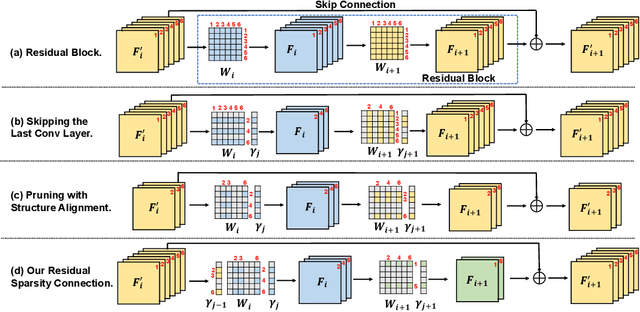
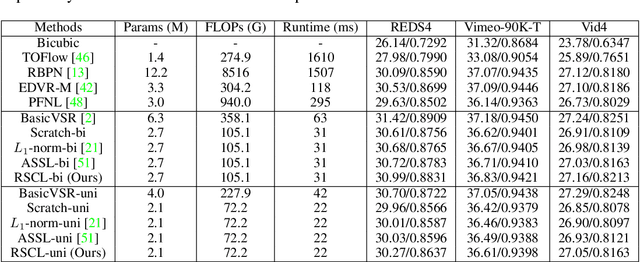
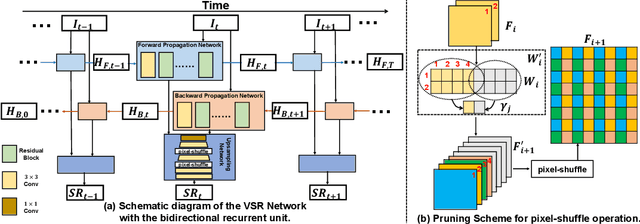
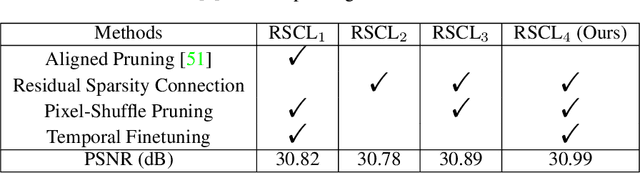
Lighter and faster models are crucial for the deployment of video super-resolution (VSR) on resource-limited devices, e.g., smartphones and wearable devices. In this paper, we develop Residual Sparsity Connection Learning (RSCL), a structured pruning scheme, to reduce the redundancy of convolution kernels and obtain a compact VSR network with a minor performance drop. However, residual blocks require the pruned filter indices of skip and residual connections to be the same, which is tricky for pruning. Thus, to mitigate the pruning restrictions of residual blocks, we design a Residual Sparsity Connection (RSC) scheme by preserving the feature channels and only operating on the important channels. Moreover, for the pixel-shuffle operation, we design a special pruning scheme by grouping several filters as pruning units to guarantee the accuracy of feature channel-space conversion after pruning. In addition, we introduce Temporal Finetuning (TF) to reduce the pruning error amplification of hidden states with temporal propagation. Extensive experiments show that the proposed RSCL significantly outperforms recent methods quantitatively and qualitatively. Codes and models will be released.
SCS-Co: Self-Consistent Style Contrastive Learning for Image Harmonization
Apr 29, 2022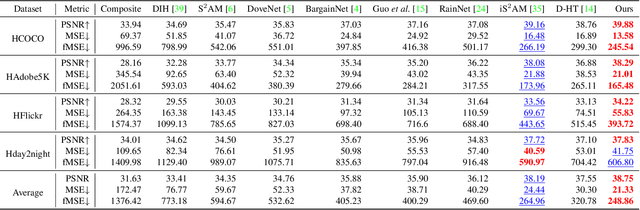
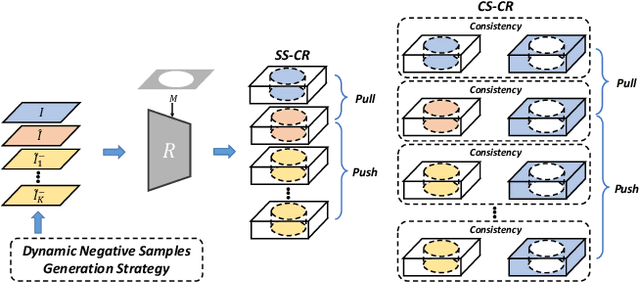
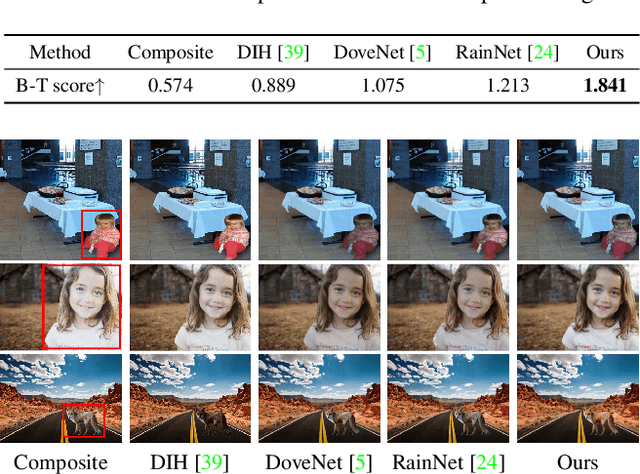
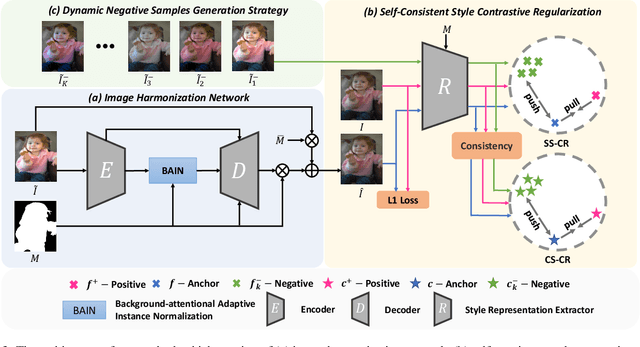
Image harmonization aims to achieve visual consistency in composite images by adapting a foreground to make it compatible with a background. However, existing methods always only use the real image as the positive sample to guide the training, and at most introduce the corresponding composite image as a single negative sample for an auxiliary constraint, which leads to limited distortion knowledge, and further causes a too large solution space, making the generated harmonized image distorted. Besides, none of them jointly constrain from the foreground self-style and foreground-background style consistency, which exacerbates this problem. Moreover, recent region-aware adaptive instance normalization achieves great success but only considers the global background feature distribution, making the aligned foreground feature distribution biased. To address these issues, we propose a self-consistent style contrastive learning scheme (SCS-Co). By dynamically generating multiple negative samples, our SCS-Co can learn more distortion knowledge and well regularize the generated harmonized image in the style representation space from two aspects of the foreground self-style and foreground-background style consistency, leading to a more photorealistic visual result. In addition, we propose a background-attentional adaptive instance normalization (BAIN) to achieve an attention-weighted background feature distribution according to the foreground-background feature similarity. Experiments demonstrate the superiority of our method over other state-of-the-art methods in both quantitative comparison and visual analysis.
Coarse-to-Fine Embedded PatchMatch and Multi-Scale Dynamic Aggregation for Reference-based Super-Resolution
Jan 12, 2022
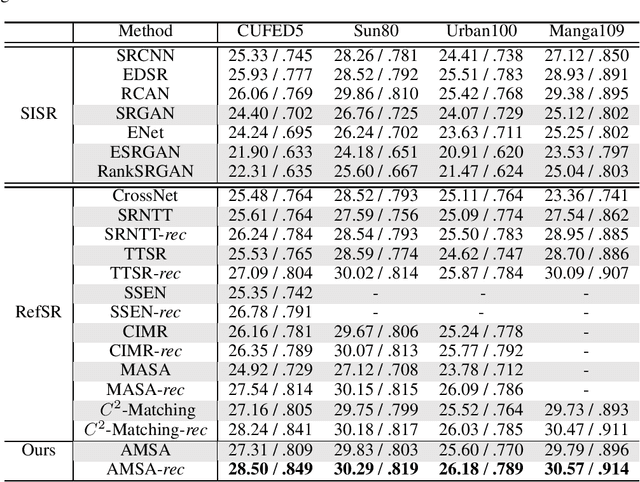
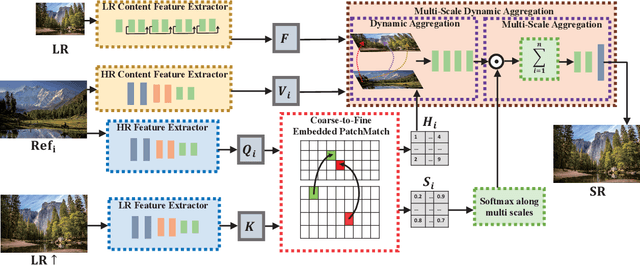
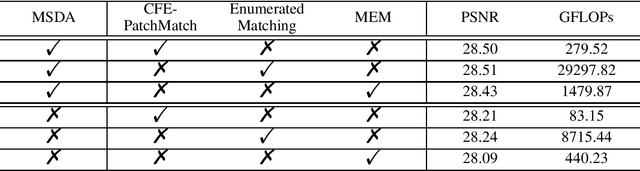
Reference-based super-resolution (RefSR) has made significant progress in producing realistic textures using an external reference (Ref) image. However, existing RefSR methods obtain high-quality correspondence matchings consuming quadratic computation resources with respect to the input size, limiting its application. Moreover, these approaches usually suffer from scale misalignments between the low-resolution (LR) image and Ref image. In this paper, we propose an Accelerated Multi-Scale Aggregation network (AMSA) for Reference-based Super-Resolution, including Coarse-to-Fine Embedded PatchMatch (CFE-PatchMatch) and Multi-Scale Dynamic Aggregation (MSDA) module. To improve matching efficiency, we design a novel Embedded PatchMacth scheme with random samples propagation, which involves end-to-end training with asymptotic linear computational cost to the input size. To further reduce computational cost and speed up convergence, we apply the coarse-to-fine strategy on Embedded PatchMacth constituting CFE-PatchMatch. To fully leverage reference information across multiple scales and enhance robustness to scale misalignment, we develop the MSDA module consisting of Dynamic Aggregation and Multi-Scale Aggregation. The Dynamic Aggregation corrects minor scale misalignment by dynamically aggregating features, and the Multi-Scale Aggregation brings robustness to large scale misalignment by fusing multi-scale information. Experimental results show that the proposed AMSA achieves superior performance over state-of-the-art approaches on both quantitative and qualitative evaluations.
Efficient Non-Local Contrastive Attention for Image Super-Resolution
Jan 11, 2022
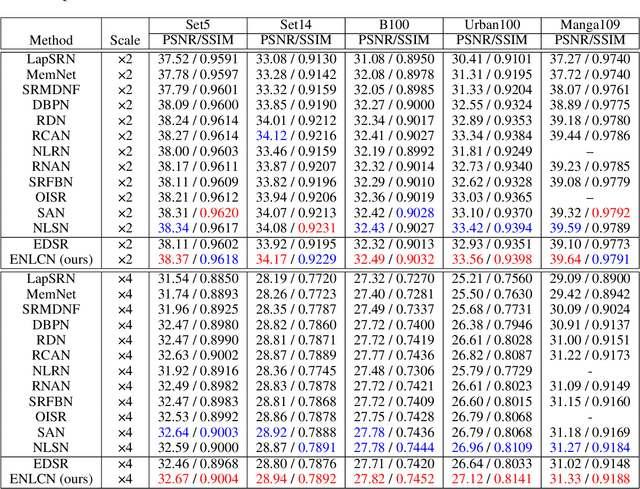
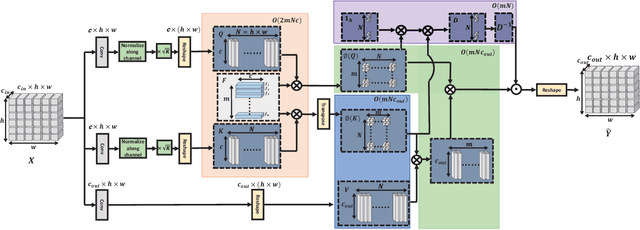

Non-Local Attention (NLA) brings significant improvement for Single Image Super-Resolution (SISR) by leveraging intrinsic feature correlation in natural images. However, NLA gives noisy information large weights and consumes quadratic computation resources with respect to the input size, limiting its performance and application. In this paper, we propose a novel Efficient Non-Local Contrastive Attention (ENLCA) to perform long-range visual modeling and leverage more relevant non-local features. Specifically, ENLCA consists of two parts, Efficient Non-Local Attention (ENLA) and Sparse Aggregation. ENLA adopts the kernel method to approximate exponential function and obtains linear computation complexity. For Sparse Aggregation, we multiply inputs by an amplification factor to focus on informative features, yet the variance of approximation increases exponentially. Therefore, contrastive learning is applied to further separate relevant and irrelevant features. To demonstrate the effectiveness of ENLCA, we build an architecture called Efficient Non-Local Contrastive Network (ENLCN) by adding a few of our modules in a simple backbone. Extensive experimental results show that ENLCN reaches superior performance over state-of-the-art approaches on both quantitative and qualitative evaluations.
Attention Cube Network for Image Restoration
Sep 15, 2020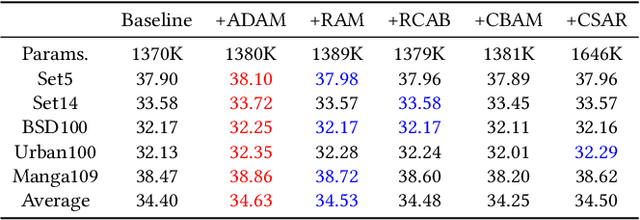
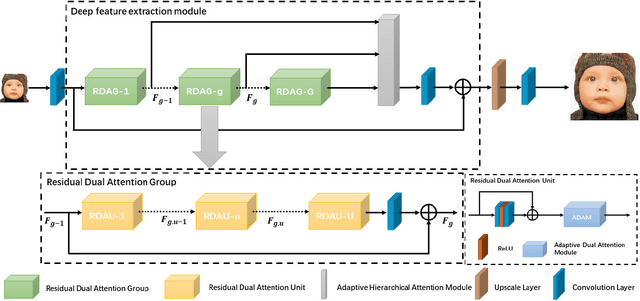
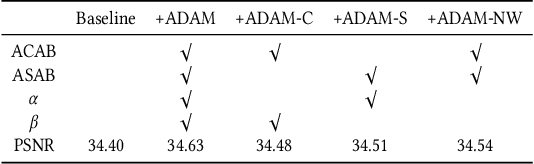
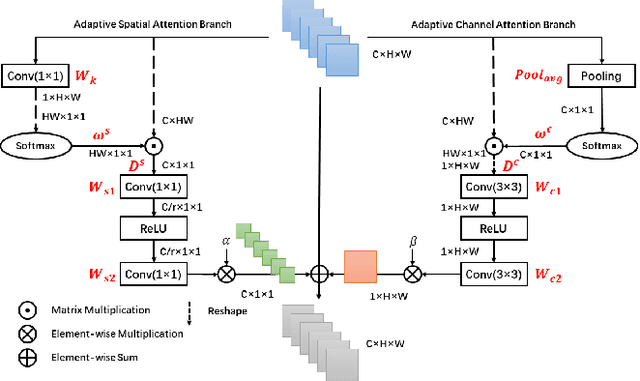
Recently, deep convolutional neural network (CNN) have been widely used in image restoration and obtained great success. However, most of existing methods are limited to local receptive field and equal treatment of different types of information. Besides, existing methods always use a multi-supervised method to aggregate different feature maps, which can not effectively aggregate hierarchical feature information. To address these issues, we propose an attention cube network (A-CubeNet) for image restoration for more powerful feature expression and feature correlation learning. Specifically, we design a novel attention mechanism from three dimensions, namely spatial dimension, channel-wise dimension and hierarchical dimension. The adaptive spatial attention branch (ASAB) and the adaptive channel attention branch (ACAB) constitute the adaptive dual attention module (ADAM), which can capture the long-range spatial and channel-wise contextual information to expand the receptive field and distinguish different types of information for more effective feature representations. Furthermore, the adaptive hierarchical attention module (AHAM) can capture the long-range hierarchical contextual information to flexibly aggregate different feature maps by weights depending on the global context. The ADAM and AHAM cooperate to form an "attention in attention" structure, which means AHAM's inputs are enhanced by ASAB and ACAB. Experiments demonstrate the superiority of our method over state-of-the-art image restoration methods in both quantitative comparison and visual analysis.