 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE-DTI: Semi-Inductive Dataset Construction and Framework Optimization for Practical Usability Enhancement in Deep Learning-Based Drug Target Interaction Prediction
Mar 12, 2025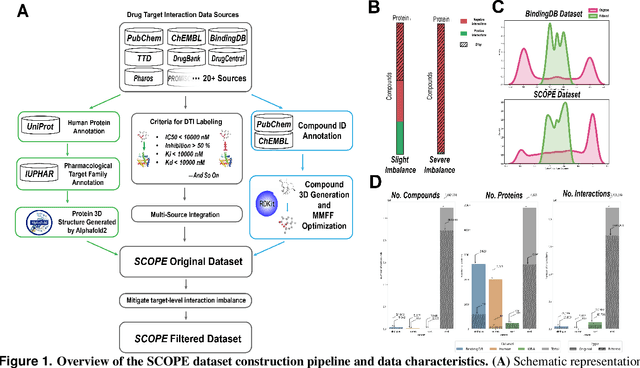
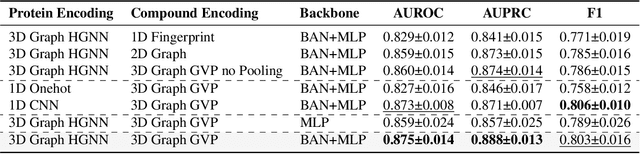
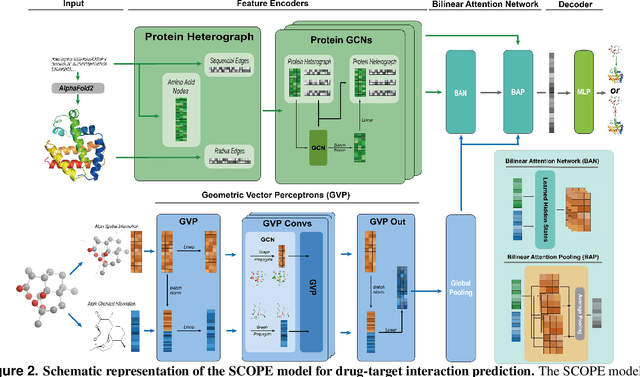
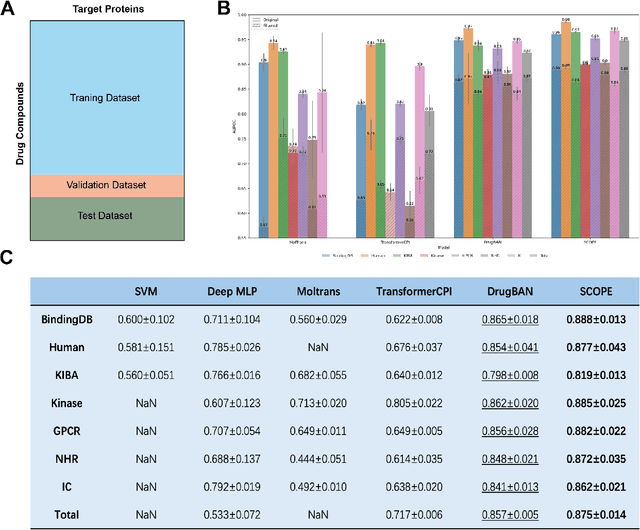
Deep learning-based drug-target interaction (DTI) prediction methods have demonstrated strong performance; however, real-world applicability remains constrained by limited data diversity and modeling complexity. To address these challenges, we propose SCOPE-DTI, a unified framework combining a large-scale, balanced semi-inductive human DTI dataset with advanced deep learning modeling. Constructed from 13 public repositories, the SCOPE dataset expands data volume by up to 100-fold compared to common benchmarks such as the Human dataset. The SCOPE model integrates three-dimensional protein and compound representations, graph neural networks, and bilinear attention mechanisms to effectively capture cross domain interaction patterns, significantly outperforming state-of-the-art methods across various DTI prediction tasks. Additionally, SCOPE-DTI provides a user-friendly interface and database. We further validate its effectiveness by experimentally identifying anticancer targets of Ginsenoside Rh1. By offering comprehensive data, advanced modeling, and accessible tools, SCOPE-DTI accelerates drug discovery research.
EditBoard: Towards A Comprehensive Evaluation Benchmark for Text-based Video Editing Models
Sep 15, 2024The rapid development of diffusion models has significantly advanced AI-generated content (AIGC), particularly in Text-to-Image (T2I) and Text-to-Video (T2V) generation. Text-based video editing, leveraging these generative capabilities, has emerged as a promising field, enabling precise modifications to videos based on text prompts. Despite the proliferation of innovative video editing models, there is a conspicuous lack of comprehensive evaluation benchmarks that holistically assess these models' performance across various dimensions. Existing evaluations are limited and inconsistent, typically summarizing overall performance with a single score, which obscures models' effectiveness on individual editing tasks. To address this gap, we propose EditBoard, the first comprehensive evaluation benchmark for text-based video editing models. EditBoard encompasses nine automatic metrics across four dimensions, evaluating models on four task categories and introducing three new metrics to assess fidelity. This task-oriented benchmark facilitates objective evaluation by detailing model performance and providing insights into each model's strengths and weaknesses. By open-sourcing EditBoard, we aim to standardize evaluation and advance the development of robust video editing models.