Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Approaches to Building Collaborative, Task-Oriented Dialog Agents through Self-Play
Paper and Code
Sep 20, 2021
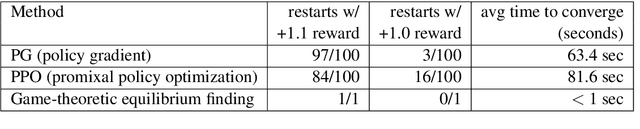
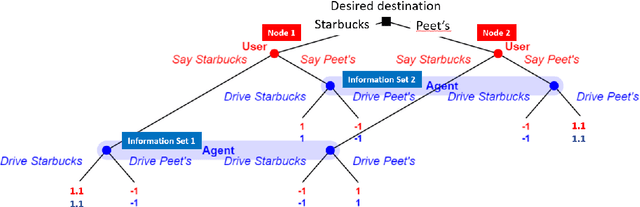
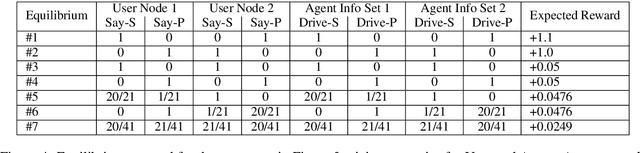
Task-oriented dialog systems are often trained on human/human dialogs, such as collected from Wizard-of-Oz interfaces. However, human/human corpora are frequently too small for supervised training to be effective. This paper investigates two approaches to training agent-bots and user-bots through self-play, in which they autonomously explore an API environment, discovering communication strategies that enable them to solve the task. We give empirical results for both reinforcement learning and game-theoretic equilibrium finding.
* 4 pages, 5 figures
View paper on