 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReEx-SQL: Reasoning with Execution-Aware Reinforcement Learning for Text-to-SQL
May 19, 2025In Text-to-SQL, execution feedback is essential for guiding large language models (LLMs) to reason accurately and generate reliable SQL queries. However, existing methods treat execution feedback solely as a post-hoc signal for correction or selection, failing to integrate it into the generation process. This limitation hinders their ability to address reasoning errors as they occur, ultimately reducing query accuracy and robustness. To address this issue, we propose ReEx-SQL (Reasoning with Execution-Aware Reinforcement Learning), a framework for Text-to-SQL that enables models to interact with the database during decoding and dynamically adjust their reasoning based on execution feedback. ReEx-SQL introduces an execution-aware reasoning paradigm that interleaves intermediate SQL execution into reasoning paths, facilitating context-sensitive revisions. It achieves this through structured prompts with markup tags and a stepwise rollout strategy that integrates execution feedback into each stage of generation. To supervise policy learning, we develop a composite reward function that includes an exploration reward, explicitly encouraging effective database interaction. Additionally, ReEx-SQL adopts a tree-based decoding strategy to support exploratory reasoning, enabling dynamic expansion of alternative reasoning paths. Notably, ReEx-SQL achieves 88.8% on Spider and 64.9% on BIRD at the 7B scale, surpassing the standard reasoning baseline by 2.7% and 2.6%, respectively. It also shows robustness, achieving 85.2% on Spider-Realistic with leading performance. In addition, its tree-structured decoding improves efficiency and performance over linear decoding, reducing inference time by 51.9% on the BIRD development set.
Towards DS-NER: Unveiling and Addressing Latent Noise in Distant Annotations
May 18, 2025Distantly supervised named entity recognition (DS-NER) has emerged as a cheap and convenient alternative to traditional human annotation methods, enabling the automatic generation of training data by aligning text with external resources. Despite the many efforts in noise measurement methods, few works focus on the latent noise distribution between different distant annotation methods. In this work, we explore the effectiveness and robustness of DS-NER by two aspects: (1) distant annotation techniques, which encompasses both traditional rule-based methods and the innovative large language model supervision approach, and (2) noise assessment, for which we introduce a novel framework. This framework addresses the challenges by distinctly categorizing them into the unlabeled-entity problem (UEP) and the noisy-entity problem (NEP), subsequently providing specialized solutions for each. Our proposed method achieves significant improvements on eight real-world distant supervision datasets originating from three different data sources and involving four distinct annotation techniques, confirming its superiority over current state-of-the-art methods.
OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
May 09, 2024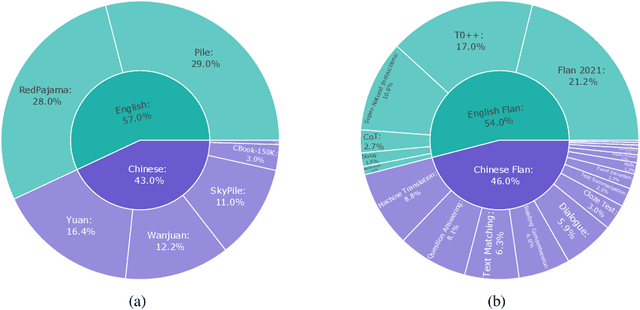

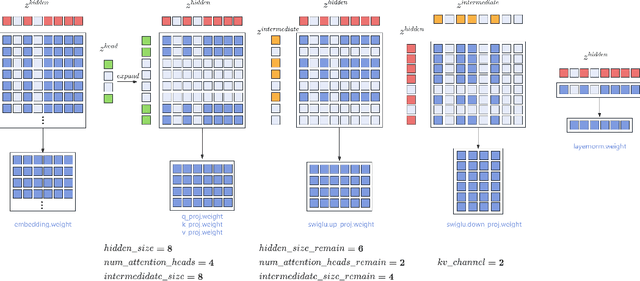
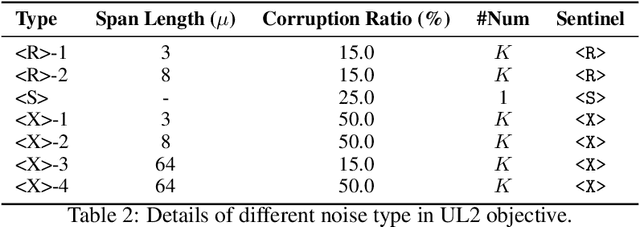
Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.
CED: Catalog Extraction from Documents
Apr 28, 2023



Sentence-by-sentence information extraction from long documents is an exhausting and error-prone task. As the indicator of document skeleton, catalogs naturally chunk documents into segments and provide informative cascade semantics, which can help to reduce the search space. Despite their usefulness, catalogs are hard to be extracted without the assist from external knowledge. For documents that adhere to a specific template, regular expressions are practical to extract catalogs. However, handcrafted heuristics are not applicable when processing documents from different sources with diverse formats. To address this problem, we build a large manually annotated corpus, which is the first dataset for the Catalog Extraction from Documents (CED) task. Based on this corpus, we propose a transition-based framework for parsing documents into catalog trees. The experimental results demonstrate that our proposed method outperforms baseline systems and shows a good ability to transfer. We believe the CED task could fill the gap between raw text segments and information extraction tasks on extremely long documents. Data and code are available at \url{https://github.com/Spico197/CatalogExtraction}