 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongRM: Revealing and Unlocking the Context Boundary of Reward Modeling
Oct 08, 2025Reward model (RM) plays a pivotal role in aligning large language model (LLM) with human preferences. As real-world applications increasingly involve long history trajectories, e.g., LLM agent, it becomes indispensable to evaluate whether a model's responses are not only high-quality but also grounded in and consistent with the provided context. Yet, current RMs remain confined to short-context settings and primarily focus on response-level attributes (e.g., safety or helpfulness), while largely neglecting the critical dimension of long context-response consistency. In this work, we introduce Long-RewardBench, a benchmark specifically designed for long-context RM evaluation, featuring both Pairwise Comparison and Best-of-N tasks. Our preliminary study reveals that even state-of-the-art generative RMs exhibit significant fragility in long-context scenarios, failing to maintain context-aware preference judgments. Motivated by the analysis of failure patterns observed in model outputs, we propose a general multi-stage training strategy that effectively scales arbitrary models into robust Long-context RMs (LongRMs). Experiments show that our approach not only substantially improves performance on long-context evaluation but also preserves strong short-context capability. Notably, our 8B LongRM outperforms much larger 70B-scale baselines and matches the performance of the proprietary Gemini 2.5 Pro model.
Learning Active Perception via Self-Evolving Preference Optimization for GUI Grounding
Sep 04, 2025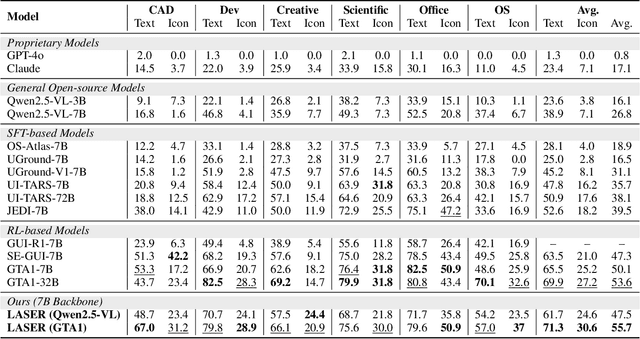



Vision Language Models (VLMs) have recently achieved significant progress in bridging visual perception and linguistic reasoning. Recently, OpenAI o3 model introduced a zoom-in search strategy that effectively elicits active perception capabilities in VLMs, improving downstream task performance. However, enabling VLMs to reason effectively over appropriate image regions remains a core challenge in GUI grounding, particularly under high-resolution inputs and complex multi-element visual interactions. In this work, we propose LASER, a self-evolving framework that progressively endows VLMs with multi-step perception capabilities, enabling precise coordinate prediction. Specifically, our approach integrate Monte Carlo quality estimation with Intersection-over-Union (IoU)-based region quality evaluation to jointly encourage both accuracy and diversity in constructing high-quality preference data. This combination explicitly guides the model to focus on instruction-relevant key regions while adaptively allocating reasoning steps based on task complexity. Comprehensive experiments on the ScreenSpot Pro and ScreenSpot-v2 benchmarks demonstrate consistent performance gains, validating the effectiveness of our method. Furthermore, when fine-tuned on GTA1-7B, LASER achieves a score of 55.7 on the ScreenSpot-Pro benchmark, establishing a new state-of-the-art (SoTA) among 7B-scale models.
Unlocking Recursive Thinking of LLMs: Alignment via Refinement
Jun 06, 2025The OpenAI o1-series models have demonstrated that leveraging long-form Chain of Thought (CoT) can substantially enhance performance. However, the recursive thinking capabilities of Large Language Models (LLMs) remain limited, particularly in the absence of expert-curated data for distillation. In this paper, we propose \textbf{AvR}: \textbf{Alignment via Refinement}, a novel method aimed at unlocking the potential of LLMs for recursive reasoning through long-form CoT. AvR introduces a refinement process that integrates criticism and improvement actions, guided by differentiable learning techniques to optimize \textbf{refinement-aware rewards}. As a result, the synthesized multi-round data can be organized as a long refinement thought, further enabling test-time scaling. Experimental results show that AvR significantly outperforms conventional preference optimization methods. Notably, with only 3k synthetic samples, our method boosts the performance of the LLaMA-3-8B-Instruct model by over 20\% in win rate on AlpacaEval 2.0. Our code is available at Github (https://github.com/Banner-Z/AvR.git).
Unleashing Reasoning Capability of LLMs via Scalable Question Synthesis from Scratch
Oct 24, 2024



The availability of high-quality data is one of the most important factors in improving the reasoning capability of LLMs. Existing works have demonstrated the effectiveness of creating more instruction data from seed questions or knowledge bases. Recent research indicates that continually scaling up data synthesis from strong models (e.g., GPT-4) can further elicit reasoning performance. Though promising, the open-sourced community still lacks high-quality data at scale and scalable data synthesis methods with affordable costs. To address this, we introduce ScaleQuest, a scalable and novel data synthesis method that utilizes "small-size" (e.g., 7B) open-source models to generate questions from scratch without the need for seed data with complex augmentation constraints. With the efficient ScaleQuest, we automatically constructed a mathematical reasoning dataset consisting of 1 million problem-solution pairs, which are more effective than existing open-sourced datasets. It can universally increase the performance of mainstream open-source models (i.e., Mistral, Llama3, DeepSeekMath, and Qwen2-Math) by achieving 29.2% to 46.4% gains on MATH. Notably, simply fine-tuning the Qwen2-Math-7B-Base model with our dataset can even surpass Qwen2-Math-7B-Instruct, a strong and well-aligned model on closed-source data, and proprietary models such as GPT-4-Turbo and Claude-3.5 Sonnet.
Fennec: Fine-grained Language Model Evaluation and Correction Extended through Branching and Bridging
May 20, 2024



The rapid advancement of large language models has given rise to a plethora of applications across a myriad of real-world tasks, mainly centered on aligning with human intent. However, the complexities inherent in human intent necessitate a dependence on labor-intensive and time-consuming human evaluation. To alleviate this constraint, we delve into the paradigm of employing open-source large language models as evaluators, aligning with the prevailing trend of utilizing GPT-4. Particularly, we present a step-by-step evaluation framework: \textbf{Fennec}, capable of \textbf{F}ine-grained \textbf{E}valuatio\textbf{N} and correctio\textbf{N} \textbf{E}xtended through bran\textbf{C}hing and bridging. Specifically, the branching operation dissects the evaluation task into various dimensions and granularities, thereby alleviating the challenges associated with evaluation. Concurrently, the bridging operation amalgamates diverse training datasets, augmenting the variety of evaluation tasks. In experimental trials, our 7B model consistently outperforms open-source larger-scale evaluation models across various widely adopted benchmarks in terms of both \textit{Agreement} and \textit{Consistency}, closely approaching the capabilities of GPT-4. We employ the fine-grained correction capabilities induced by the evaluation model to refine multiple model responses, and the results show that the refinement elevates the quality of responses, leading to an improvement of 1-2 points on the MT-Bench. Our code is available at Github\footnote{\url{https://github.com/dropreg/Fennec}}.
C$^2$-Rec: An Effective Consistency Constraint for Sequential Recommendation
Dec 13, 2021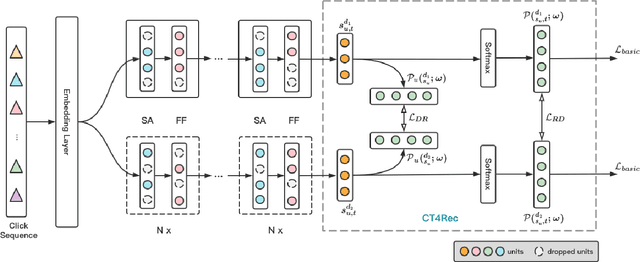


Sequential recommendation methods play an important role in real-world recommender systems. These systems are able to catch user preferences by taking advantage of historical records and then performing recommendations. Contrastive learning(CL) is a cutting-edge technology that can assist us in obtaining informative user representations, but these CL-based models need subtle negative sampling strategies, tedious data augmentation methods, and heavy hyper-parameters tuning work. In this paper, we introduce another way to generate better user representations and recommend more attractive items to users. Particularly, we put forward an effective \textbf{C}onsistency \textbf{C}onstraint for sequential \textbf{Rec}ommendation(C$^2$-Rec) in which only two extra training objectives are used without any structural modifications and data augmentation strategies. Substantial experiments have been conducted on three benchmark datasets and one real industrial dataset, which proves that our proposed method outperforms SOTA models substantially. Furthermore, our method needs much less training time than those CL-based models. Online AB-test on real-world recommendation systems also achieves 10.141\% improvement on the click-through rate and 10.541\% increase on the average click number per capita. The code is available at \url{https://github.com/zhengrongqin/C2-Rec}.
R-Drop: Regularized Dropout for Neural Networks
Jun 28, 2021



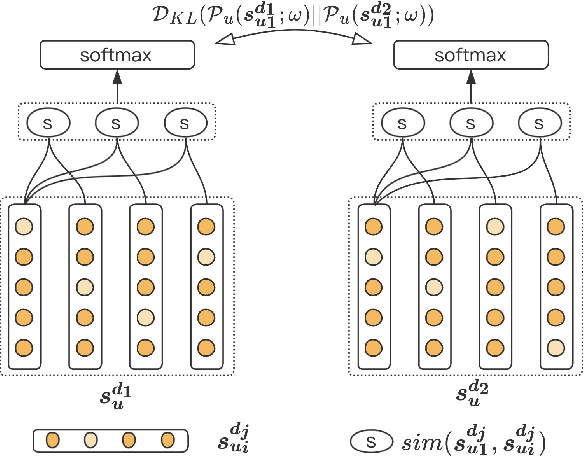
Dropout is a powerful and widely used technique to regularize the training of deep neural networks. In this paper, we introduce a simple regularization strategy upon dropout in model training, namely R-Drop, which forces the output distributions of different sub models generated by dropout to be consistent with each other. Specifically, for each training sample, R-Drop minimizes the bidirectional KL-divergence between the output distributions of two sub models sampled by dropout. Theoretical analysis reveals that R-Drop reduces the freedom of the model parameters and complements dropout. Experiments on $\bf{5}$ widely used deep learning tasks ($\bf{18}$ datasets in total), including neural machine translation, abstractive summarization, language understanding, language modeling, and image classification, show that R-Drop is universally effective. In particular, it yields substantial improvements when applied to fine-tune large-scale pre-trained models, e.g., ViT, RoBERTa-large, and BART, and achieves state-of-the-art (SOTA) performances with the vanilla Transformer model on WMT14 English$\to$German translation ($\bf{30.91}$ BLEU) and WMT14 English$\to$French translation ($\bf{43.95}$ BLEU), even surpassing models trained with extra large-scale data and expert-designed advanced variants of Transformer models. Our code is available at GitHub{\url{https://github.com/dropreg/R-Drop}}.
TechKG: A Large-Scale Chinese Technology-Oriented Knowledge Graph
Dec 17, 2018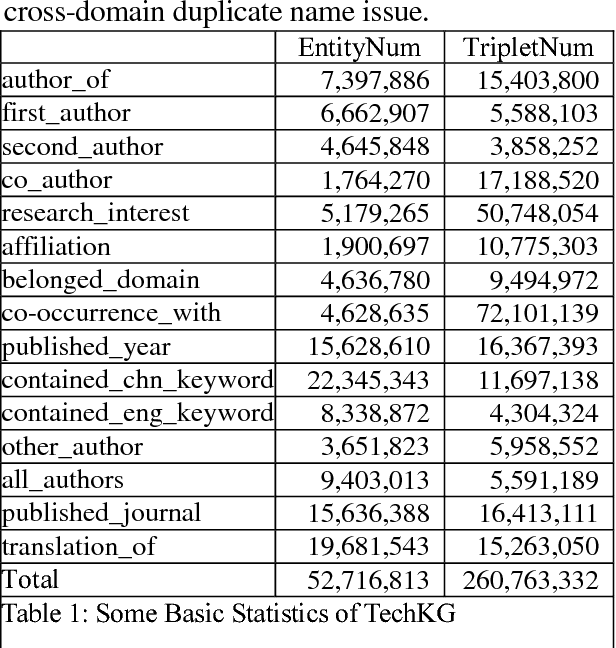
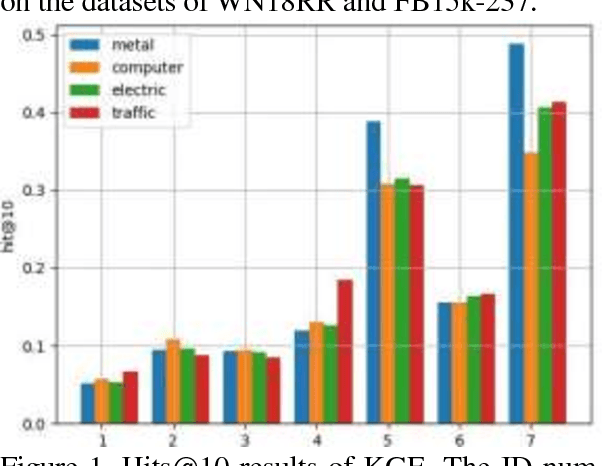
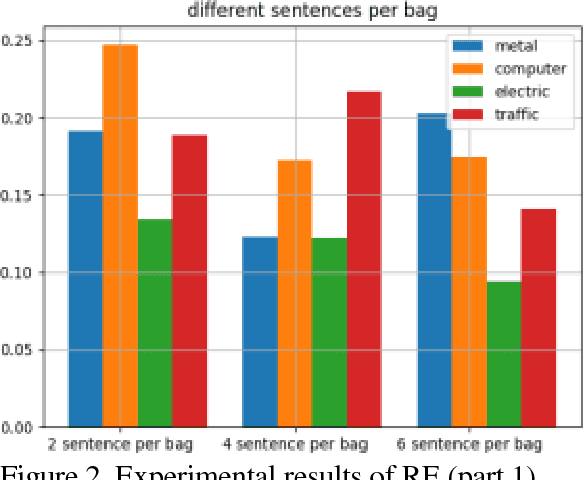
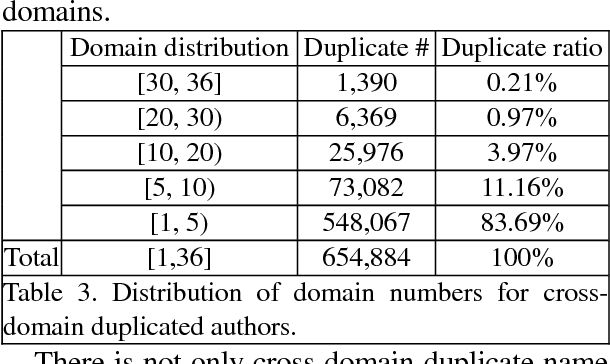
Knowledge graph is a kind of valuable knowledge base which would benefit lots of AI-related applications. Up to now, lots of large-scale knowledge graphs have been built. However, most of them are non-Chinese and designed for general purpose. In this work, we introduce TechKG, a large scale Chinese knowledge graph that is technology-oriented. It is built automatically from massive technical papers that are published in Chinese academic journals of different research domains. Some carefully designed heuristic rules are used to extract high quality entities and relations. Totally, it comprises of over 260 million triplets that are built upon more than 52 million entities which come from 38 research domains. Our preliminary ex-periments indicate that TechKG has high adaptability and can be used as a dataset for many diverse AI-related applications. We released TechKG at: http://www.techkg.cn.