 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Multi-Granularity Click Confidence Learning via Self-Distillation in Recommendation
Sep 28, 2023



Recommendation systems rely on historical clicks to learn user interests and provide appropriate items. However, current studies tend to treat clicks equally, which may ignore the assorted intensities of user interests in different clicks. In this paper, we aim to achieve multi-granularity Click confidence Learning via Self-Distillation in recommendation (CLSD). Due to the lack of supervised signals in click confidence, we first apply self-supervised learning to obtain click confidence scores via a global self-distillation method. After that, we define a local confidence function to adapt confidence scores at the user group level, since the confidence distributions can be varied among user groups. With the combination of multi-granularity confidence learning, we can distinguish the quality of clicks and model user interests more accurately without involving extra data and model structures. The significant improvements over different backbones on industrial offline and online experiments in a real-world recommender system prove the effectiveness of our model. Recently, CLSD has been deployed on a large-scale recommender system, affecting over 400 million users.
Learning from All Sides: Diversified Positive Augmentation via Self-distillation in Recommendation
Aug 15, 2023



Personalized recommendation relies on user historical behaviors to provide user-interested items, and thus seriously struggles with the data sparsity issue. A powerful positive item augmentation is beneficial to address the sparsity issue, while few works could jointly consider both the accuracy and diversity of these augmented training labels. In this work, we propose a novel model-agnostic Diversified self-distillation guided positive augmentation (DivSPA) for accurate and diverse positive item augmentations. Specifically, DivSPA first conducts three types of retrieval strategies to collect high-quality and diverse positive item candidates according to users' overall interests, short-term intentions, and similar users. Next, a self-distillation module is conducted to double-check and rerank these candidates as the final positive augmentations. Extensive offline and online evaluations verify the effectiveness of our proposed DivSPA on both accuracy and diversity. DivSPA is simple and effective, which could be conveniently adapted to other base models and systems. Currently, DivSPA has been deployed on multiple widely-used real-world recommender systems.
Graph Exploration Matters: Improving both individual-level and system-level diversity in WeChat Feed Recommender
May 29, 2023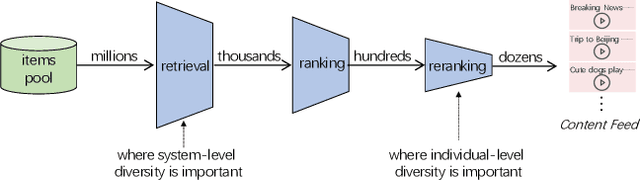

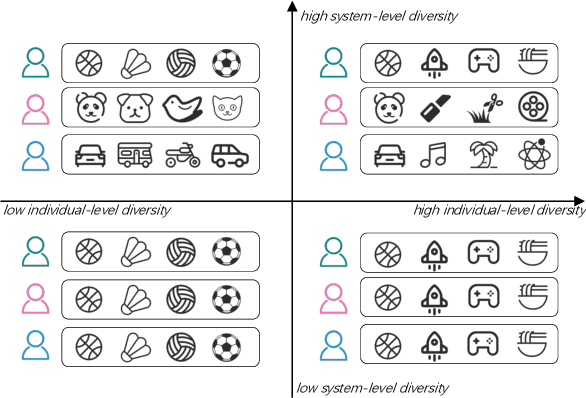
There are roughly three stages in real industrial recommendation systems, candidates generation (retrieval), ranking and reranking. Individual-level diversity and system-level diversity are both important for industrial recommender systems. The former focus on each single user's experience, while the latter focus on the difference among users. Graph-based retrieval strategies are inevitably hijacked by heavy users and popular items, leading to the convergence of candidates for users and the lack of system-level diversity. Meanwhile, in the reranking phase, Determinantal Point Process (DPP) is deployed to increase individual-level diverisity. Heavily relying on the semantic information of items, DPP suffers from clickbait and inaccurate attributes. Besides, most studies only focus on one of the two levels of diversity, and ignore the mutual influence among different stages in real recommender systems. We argue that individual-level diversity and system-level diversity should be viewed as an integrated problem, and we provide an efficient and deployable solution for web-scale recommenders. Generally, we propose to employ the retrieval graph information in diversity-based reranking, by which to weaken the hidden similarity of items exposed to users, and consequently gain more graph explorations to improve the system-level diveristy. Besides, we argue that users' propensity for diversity changes over time in content feed recommendation. Therefore, with the explored graph, we also propose to capture the user's real-time personalized propensity to the diversity. We implement and deploy the combined system in WeChat App's Top Stories used by hundreds of millions of users. Offline simulations and online A/B tests show our solution can effectively improve both user engagement and system revenue.
UFNRec: Utilizing False Negative Samples for Sequential Recommendation
Aug 08, 2022



Sequential recommendation models are primarily optimized to distinguish positive samples from negative ones during training in which negative sampling serves as an essential component in learning the evolving user preferences through historical records. Except for randomly sampling negative samples from a uniformly distributed subset, many delicate methods have been proposed to mine negative samples with high quality. However, due to the inherent randomness of negative sampling, false negative samples are inevitably collected in model training. Current strategies mainly focus on removing such false negative samples, which leads to overlooking potential user interests, lack of recommendation diversity, less model robustness, and suffering from exposure bias. To this end, we propose a novel method that can Utilize False Negative samples for sequential Recommendation (UFNRec) to improve model performance. We first devise a simple strategy to extract false negative samples and then transfer these samples to positive samples in the following training process. Furthermore, we construct a teacher model to provide soft labels for false negative samples and design a consistency loss to regularize the predictions of these samples from the student model and the teacher model. To the best of our knowledge, this is the first work to utilize false negative samples instead of simply removing them for the sequential recommendation. Experiments on three benchmark public datasets are conducted using three widely applied SOTA models. The experiment results demonstrate that our proposed UFNRec can effectively draw information from false negative samples and further improve the performance of SOTA models. The code is available at https://github.com/UFNRec-code/UFNRec.
Single-shot Embedding Dimension Search in Recommender System
Apr 15, 2022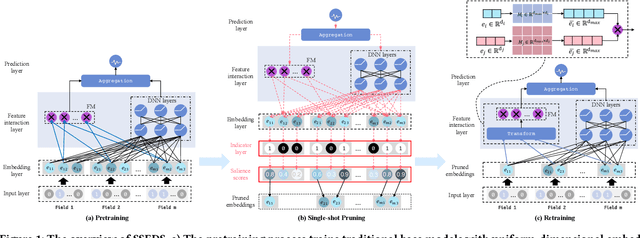
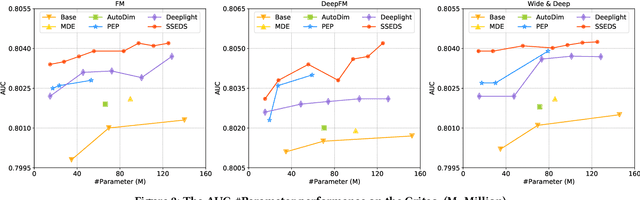
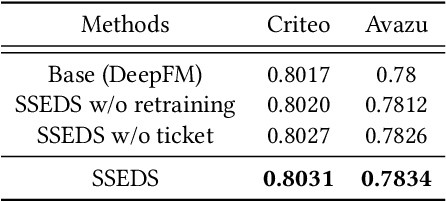
As a crucial component of most modern deep recommender systems, feature embedding maps high-dimensional sparse user/item features into low-dimensional dense embeddings. However, these embeddings are usually assigned a unified dimension, which suffers from the following issues: (1) high memory usage and computation cost. (2) sub-optimal performance due to inferior dimension assignments. In order to alleviate the above issues, some works focus on automated embedding dimension search by formulating it as hyper-parameter optimization or embedding pruning problems. However, they either require well-designed search space for hyperparameters or need time-consuming optimization procedures. In this paper, we propose a Single-Shot Embedding Dimension Search method, called SSEDS, which can efficiently assign dimensions for each feature field via a single-shot embedding pruning operation while maintaining the recommendation accuracy of the model. Specifically, it introduces a criterion for identifying the importance of each embedding dimension for each feature field. As a result, SSEDS could automatically obtain mixed-dimensional embeddings by explicitly reducing redundant embedding dimensions based on the corresponding dimension importance ranking and the predefined parameter budget. Furthermore, the proposed SSEDS is model-agnostic, meaning that it could be integrated into different base recommendation models. The extensive offline experiments are conducted on two widely used public datasets for CTR prediction tasks, and the results demonstrate that SSEDS can still achieve strong recommendation performance even if it has reduced 90\% parameters. Moreover, SSEDS has also been deployed on the WeChat Subscription platform for practical recommendation services. The 7-day online A/B test results show that SSEDS can significantly improve the performance of the online recommendation model.
C$^2$-Rec: An Effective Consistency Constraint for Sequential Recommendation
Dec 13, 2021

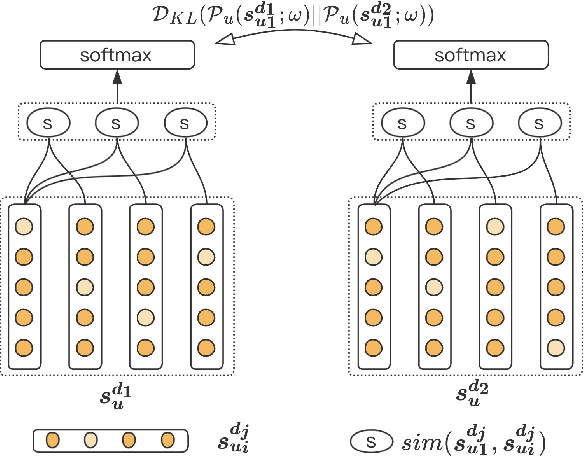

Sequential recommendation methods play an important role in real-world recommender systems. These systems are able to catch user preferences by taking advantage of historical records and then performing recommendations. Contrastive learning(CL) is a cutting-edge technology that can assist us in obtaining informative user representations, but these CL-based models need subtle negative sampling strategies, tedious data augmentation methods, and heavy hyper-parameters tuning work. In this paper, we introduce another way to generate better user representations and recommend more attractive items to users. Particularly, we put forward an effective \textbf{C}onsistency \textbf{C}onstraint for sequential \textbf{Rec}ommendation(C$^2$-Rec) in which only two extra training objectives are used without any structural modifications and data augmentation strategies. Substantial experiments have been conducted on three benchmark datasets and one real industrial dataset, which proves that our proposed method outperforms SOTA models substantially. Furthermore, our method needs much less training time than those CL-based models. Online AB-test on real-world recommendation systems also achieves 10.141\% improvement on the click-through rate and 10.541\% increase on the average click number per capita. The code is available at \url{https://github.com/zhengrongqin/C2-Rec}.