 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling On-Device Learning via Experience Replay with Efficient Dataset Condensation
May 25, 2024Upon deployment to edge devices, it is often desirable for a model to further learn from streaming data to improve accuracy. However, extracting representative features from such data is challenging because it is typically unlabeled, non-independent and identically distributed (non-i.i.d), and is seen only once. To mitigate this issue, a common strategy is to maintain a small data buffer on the edge device to hold the most representative data for further learning. As most data is either never stored or quickly discarded, identifying the most representative data to avoid significant information loss becomes critical. In this paper, we propose an on-device framework that addresses this issue by condensing incoming data into more informative samples. Specifically, to effectively handle unlabeled incoming data, we propose a pseudo-labeling technique designed for unlabeled on-device learning environments. Additionally, we develop a dataset condensation technique that only requires little computation resources. To counteract the effects of noisy labels during the condensation process, we further utilize a contrastive learning objective to improve the purity of class data within the buffer. Our empirical results indicate substantial improvements over existing methods, particularly when buffer capacity is severely restricted. For instance, with a buffer capacity of just one sample per class, our method achieves an accuracy that outperforms the best existing baseline by 58.4% on the CIFAR-10 dataset.
Semi-decentralized Federated Ego Graph Learning for Recommendation
Feb 10, 2023



Collaborative filtering (CF) based recommender systems are typically trained based on personal interaction data (e.g., clicks and purchases) that could be naturally represented as ego graphs. However, most existing recommendation methods collect these ego graphs from all users to compose a global graph to obtain high-order collaborative information between users and items, and these centralized CF recommendation methods inevitably lead to a high risk of user privacy leakage. Although recently proposed federated recommendation systems can mitigate the privacy problem, they either restrict the on-device local training to an isolated ego graph or rely on an additional third-party server to access other ego graphs resulting in a cumbersome pipeline, which is hard to work in practice. In addition, existing federated recommendation systems require resource-limited devices to maintain the entire embedding tables resulting in high communication costs. In light of this, we propose a semi-decentralized federated ego graph learning framework for on-device recommendations, named SemiDFEGL, which introduces new device-to-device collaborations to improve scalability and reduce communication costs and innovatively utilizes predicted interacted item nodes to connect isolated ego graphs to augment local subgraphs such that the high-order user-item collaborative information could be used in a privacy-preserving manner. Furthermore, the proposed framework is model-agnostic, meaning that it could be seamlessly integrated with existing graph neural network-based recommendation methods and privacy protection techniques. To validate the effectiveness of the proposed SemiDFEGL, extensive experiments are conducted on three public datasets, and the results demonstrate the superiority of the proposed SemiDFEGL compared to other federated recommendation methods.
Single-shot Embedding Dimension Search in Recommender System
Apr 15, 2022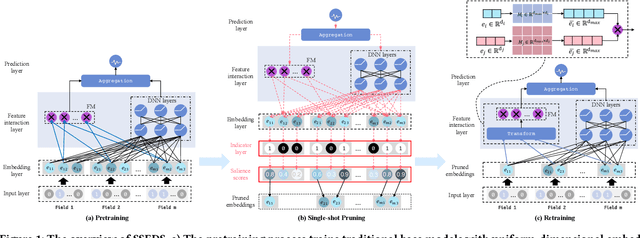
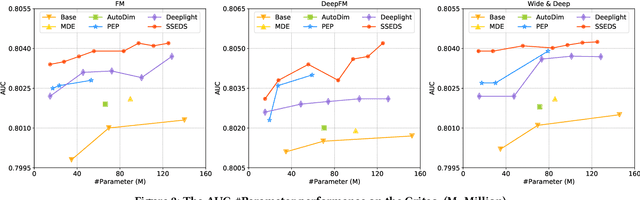
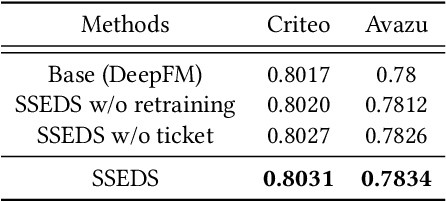
As a crucial component of most modern deep recommender systems, feature embedding maps high-dimensional sparse user/item features into low-dimensional dense embeddings. However, these embeddings are usually assigned a unified dimension, which suffers from the following issues: (1) high memory usage and computation cost. (2) sub-optimal performance due to inferior dimension assignments. In order to alleviate the above issues, some works focus on automated embedding dimension search by formulating it as hyper-parameter optimization or embedding pruning problems. However, they either require well-designed search space for hyperparameters or need time-consuming optimization procedures. In this paper, we propose a Single-Shot Embedding Dimension Search method, called SSEDS, which can efficiently assign dimensions for each feature field via a single-shot embedding pruning operation while maintaining the recommendation accuracy of the model. Specifically, it introduces a criterion for identifying the importance of each embedding dimension for each feature field. As a result, SSEDS could automatically obtain mixed-dimensional embeddings by explicitly reducing redundant embedding dimensions based on the corresponding dimension importance ranking and the predefined parameter budget. Furthermore, the proposed SSEDS is model-agnostic, meaning that it could be integrated into different base recommendation models. The extensive offline experiments are conducted on two widely used public datasets for CTR prediction tasks, and the results demonstrate that SSEDS can still achieve strong recommendation performance even if it has reduced 90\% parameters. Moreover, SSEDS has also been deployed on the WeChat Subscription platform for practical recommendation services. The 7-day online A/B test results show that SSEDS can significantly improve the performance of the online recommendation model.