 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiriam: Exploiting Elastic Kernels for Real-time Multi-DNN Inference on Edge GPU
Paper and Code
Jul 10, 2023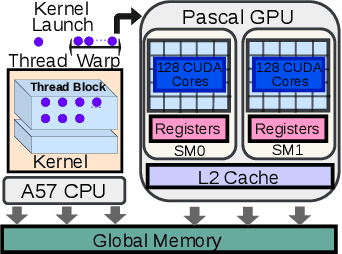

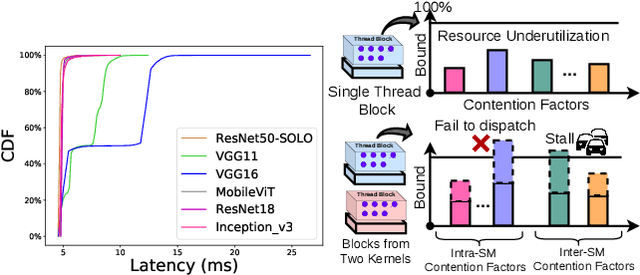

Many applications such as autonomous driving and augmented reality, require the concurrent running of multiple deep neural networks (DNN) that poses different levels of real-time performance requirements. However, coordinating multiple DNN tasks with varying levels of criticality on edge GPUs remains an area of limited study. Unlike server-level GPUs, edge GPUs are resource-limited and lack hardware-level resource management mechanisms for avoiding resource contention. Therefore, we propose Miriam, a contention-aware task coordination framework for multi-DNN inference on edge GPU. Miriam consolidates two main components, an elastic-kernel generator, and a runtime dynamic kernel coordinator, to support mixed critical DNN inference. To evaluate Miriam, we build a new DNN inference benchmark based on CUDA with diverse representative DNN workloads. Experiments on two edge GPU platforms show that Miriam can increase system throughput by 92% while only incurring less than 10\% latency overhead for critical tasks, compared to state of art baselines.