 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training for Recommendation Unlearning
May 29, 2025Modern recommender systems powered by Graph Neural Networks (GNNs) excel at modeling complex user-item interactions, yet increasingly face scenarios requiring selective forgetting of training data. Beyond user requests to remove specific interactions due to privacy concerns or preference changes, regulatory frameworks mandate recommender systems' ability to eliminate the influence of certain user data from models. This recommendation unlearning challenge presents unique difficulties as removing connections within interaction graphs creates ripple effects throughout the model, potentially impacting recommendations for numerous users. Traditional approaches suffer from significant drawbacks: fragmentation methods damage graph structure and diminish performance, while influence function techniques make assumptions that may not hold in complex GNNs, particularly with self-supervised or random architectures. To address these limitations, we propose a novel model-agnostic pre-training paradigm UnlearnRec that prepares systems for efficient unlearning operations. Our Influence Encoder takes unlearning requests together with existing model parameters and directly produces updated parameters of unlearned model with little fine-tuning, avoiding complete retraining while preserving model performance characteristics. Extensive evaluation on public benchmarks demonstrates that our method delivers exceptional unlearning effectiveness while providing more than 10x speedup compared to retraining approaches. We release our method implementation at: https://github.com/HKUDS/UnlearnRec.
Self-Adjust Softmax
Feb 25, 2025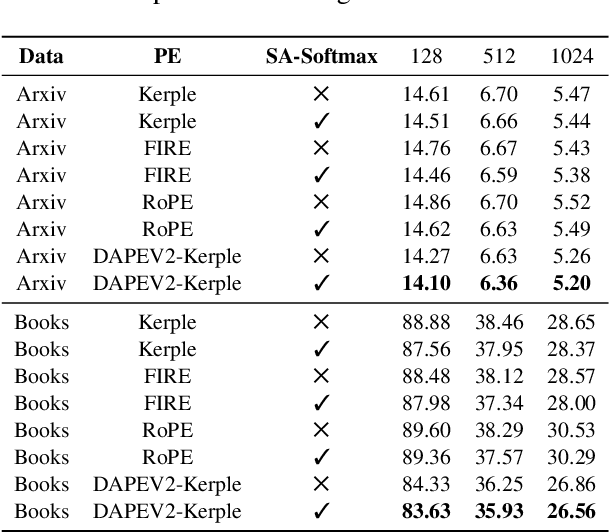
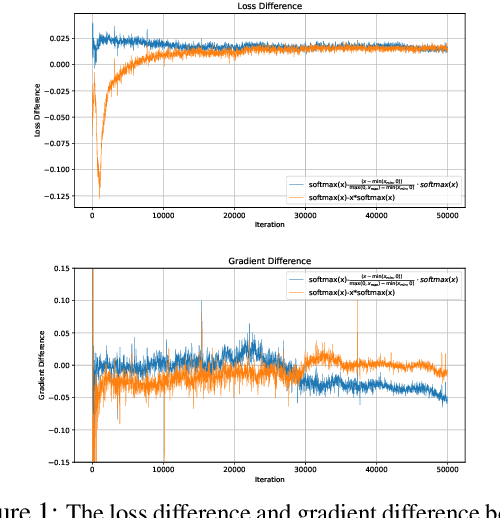
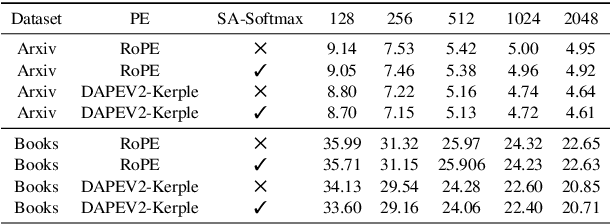
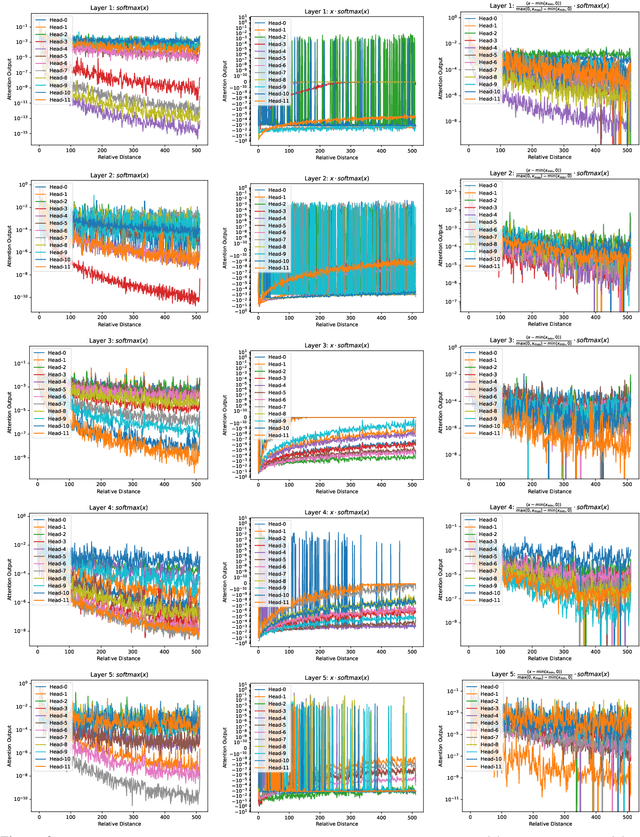
The softmax function is crucial in Transformer attention, which normalizes each row of the attention scores with summation to one, achieving superior performances over other alternative functions. However, the softmax function can face a gradient vanishing issue when some elements of the attention scores approach extreme values, such as probabilities close to one or zero. In this paper, we propose Self-Adjust Softmax (SA-Softmax) to address this issue by modifying $softmax(x)$ to $x \cdot softmax(x)$ and its normalized variant $\frac{(x - min(x_{\min},0))}{max(0,x_{max})-min(x_{min},0)} \cdot softmax(x)$. We theoretically show that SA-Softmax provides enhanced gradient properties compared to the vanilla softmax function. Moreover, SA-Softmax Attention can be seamlessly integrated into existing Transformer models to their attention mechanisms with minor adjustments. We conducted experiments to evaluate the empirical performance of Transformer models using SA-Softmax compared to the vanilla softmax function. These experiments, involving models with up to 2.7 billion parameters, are conducted across diverse datasets, language tasks, and positional encoding methods.
LightGNN: Simple Graph Neural Network for Recommendation
Jan 07, 2025



Graph neural networks (GNNs) have demonstrated superior performance in collaborative recommendation through their ability to conduct high-order representation smoothing, effectively capturing structural information within users' interaction patterns. However, existing GNN paradigms face significant challenges in scalability and robustness when handling large-scale, noisy, and real-world datasets. To address these challenges, we present LightGNN, a lightweight and distillation-based GNN pruning framework designed to substantially reduce model complexity while preserving essential collaboration modeling capabilities. Our LightGNN framework introduces a computationally efficient pruning module that adaptively identifies and removes redundant edges and embedding entries for model compression. The framework is guided by a resource-friendly hierarchical knowledge distillation objective, whose intermediate layer augments the observed graph to maintain performance, particularly in high-rate compression scenarios. Extensive experiments on public datasets demonstrate LightGNN's effectiveness, significantly improving both computational efficiency and recommendation accuracy. Notably, LightGNN achieves an 80% reduction in edge count and 90% reduction in embedding entries while maintaining performance comparable to more complex state-of-the-art baselines. The implementation of our LightGNN framework is available at the github repository: https://github.com/HKUDS/LightGNN.
SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator
Dec 16, 2024



Large Language Models (LLMs) have exhibited exceptional performance across a spectrum of natural language processing tasks. However, their substantial sizes pose considerable challenges, particularly in computational demands and inference speed, due to their quadratic complexity. In this work, we have identified a key pattern: certain seemingly meaningless special tokens (i.e., separators) contribute disproportionately to attention scores compared to semantically meaningful tokens. This observation suggests that information of the segments between these separator tokens can be effectively condensed into the separator tokens themselves without significant information loss. Guided by this insight, we introduce SepLLM, a plug-and-play framework that accelerates inference by compressing these segments and eliminating redundant tokens. Additionally, we implement efficient kernels for training acceleration. Experimental results across training-free, training-from-scratch, and post-training settings demonstrate SepLLM's effectiveness. Notably, using the Llama-3-8B backbone, SepLLM achieves over 50% reduction in KV cache on the GSM8K-CoT benchmark while maintaining comparable performance. Furthermore, in streaming settings, SepLLM effectively processes sequences of up to 4 million tokens or more while maintaining consistent language modeling capabilities.