 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELFS: Enhancing Label-Free Coreset Selection via Clustering-based Pseudo-Labeling
Paper and Code
Jun 06, 2024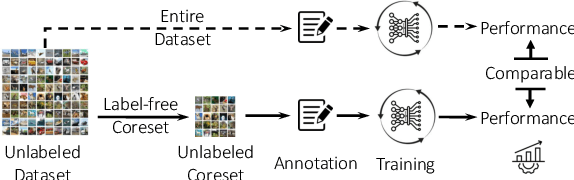
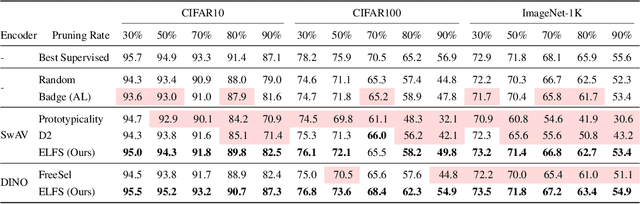

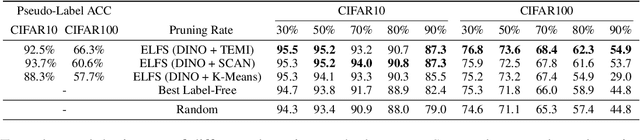
High-quality human-annotated data is crucial for modern deep learning pipelines, yet the human annotation process is both costly and time-consuming. Given a constrained human labeling budget, selecting an informative and representative data subset for labeling can significantly reduce human annotation effort. Well-performing state-of-the-art (SOTA) coreset selection methods require ground-truth labels over the whole dataset, failing to reduce the human labeling burden. Meanwhile, SOTA label-free coreset selection methods deliver inferior performance due to poor geometry-based scores. In this paper, we introduce ELFS, a novel label-free coreset selection method. ELFS employs deep clustering to estimate data difficulty scores without ground-truth labels. Furthermore, ELFS uses a simple but effective double-end pruning method to mitigate bias on calculated scores, which further improves the performance on selected coresets. We evaluate ELFS on five vision benchmarks and show that ELFS consistently outperforms SOTA label-free baselines. For instance, at a 90% pruning rate, ELFS surpasses the best-performing baseline by 5.3% on CIFAR10 and 7.1% on CIFAR100. Moreover, ELFS even achieves comparable performance to supervised coreset selection at low pruning rates (e.g., 30% and 50%) on CIFAR10 and ImageNet-1K.