 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Diagnosing Vulnerability under Adversarial Attacks
Paper and Code

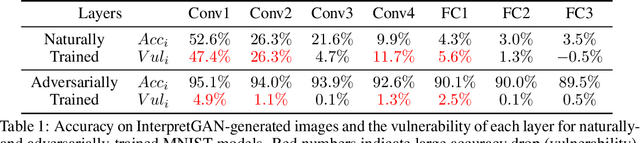

Deep Neural Networks (DNNs) are known to be vulnerable to adversarial attacks. Currently, there is no clear insight into how slight perturbations cause such a large difference in classification results and how we can design a more robust model architecture. In this work, we propose a novel interpretability method, InterpretGAN, to generate explanations for features used for classification in latent variables. Interpreting the classification process of adversarial examples exposes how adversarial perturbations influence features layer by layer as well as which features are modified by perturbations. Moreover, we design the first diagnostic method to quantify the vulnerability contributed by each layer, which can be used to identify vulnerable parts of model architectures. The diagnostic results show that the layers introducing more information loss tend to be more vulnerable than other layers. Based on the findings, our evaluation results on MNIST and CIFAR10 datasets suggest that average pooling layers, with lower information loss, are more robust than max pooling layers for the network architectures studied in this paper.