 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoneyBee: Efficient Role-based Access Control for Vector Databases via Dynamic Partitioning
May 02, 2025



As vector databases gain traction in enterprise applications, robust access control has become critical to safeguard sensitive data. Access control in these systems is often implemented through hybrid vector queries, which combine nearest neighbor search on vector data with relational predicates based on user permissions. However, existing approaches face significant trade-offs: creating dedicated indexes for each user minimizes query latency but introduces excessive storage redundancy, while building a single index and applying access control after vector search reduces storage overhead but suffers from poor recall and increased query latency. This paper introduces HoneyBee, a dynamic partitioning framework that bridges the gap between these approaches by leveraging the structure of Role-Based Access Control (RBAC) policies. RBAC, widely adopted in enterprise settings, groups users into roles and assigns permissions to those roles, creating a natural "thin waist" in the permission structure that is ideal for partitioning decisions. Specifically, HoneyBee produces overlapping partitions where vectors can be strategically replicated across different partitions to reduce query latency while controlling storage overhead. By introducing analytical models for the performance and recall of the vector search, HoneyBee formulates the partitioning strategy as a constrained optimization problem to dynamically balance storage, query efficiency, and recall. Evaluations on RBAC workloads demonstrate that HoneyBee reduces storage redundancy compared to role partitioning and achieves up to 6x faster query speeds than row-level security (RLS) with only 1.4x storage increase, offering a practical middle ground for secure and efficient vector search.
HeterMoE: Efficient Training of Mixture-of-Experts Models on Heterogeneous GPUs
Apr 04, 2025The Mixture-of-Experts (MoE) architecture has become increasingly popular as a method to scale up large language models (LLMs). To save costs, heterogeneity-aware training solutions have been proposed to utilize GPU clusters made up of both newer and older-generation GPUs. However, existing solutions are agnostic to the performance characteristics of different MoE model components (i.e., attention and expert) and do not fully utilize each GPU's compute capability. In this paper, we introduce HeterMoE, a system to efficiently train MoE models on heterogeneous GPUs. Our key insight is that newer GPUs significantly outperform older generations on attention due to architectural advancements, while older GPUs are still relatively efficient for experts. HeterMoE disaggregates attention and expert computation, where older GPUs are only assigned with expert modules. Through the proposed zebra parallelism, HeterMoE overlaps the computation on different GPUs, in addition to employing an asymmetric expert assignment strategy for fine-grained load balancing to minimize GPU idle time. Our evaluation shows that HeterMoE achieves up to 2.3x speed-up compared to existing MoE training systems, and 1.4x compared to an optimally balanced heterogeneity-aware solution. HeterMoE efficiently utilizes older GPUs by maintaining 95% training throughput on average, even with half of the GPUs in a homogeneous A40 cluster replaced with V100.
Lazarus: Resilient and Elastic Training of Mixture-of-Experts Models with Adaptive Expert Placement
Jul 05, 2024



Sparsely-activated Mixture-of-Experts (MoE) architecture has increasingly been adopted to further scale large language models (LLMs) due to its sub-linear scaling for computation costs. However, frequent failures still pose significant challenges as training scales. The cost of even a single failure is significant, as all GPUs need to wait idle until the failure is resolved, potentially losing considerable training progress as training has to restart from checkpoints. Existing solutions for efficient fault-tolerant training either lack elasticity or rely on building resiliency into pipeline parallelism, which cannot be applied to MoE models due to the expert parallelism strategy adopted by the MoE architecture. We present Lazarus, a system for resilient and elastic training of MoE models. Lazarus adaptively allocates expert replicas to address the inherent imbalance in expert workload and speeds-up training, while a provably optimal expert placement algorithm is developed to maximize the probability of recovery upon failures. Through adaptive expert placement and a flexible token dispatcher, Lazarus can also fully utilize all available nodes after failures, leaving no GPU idle. Our evaluation shows that Lazarus outperforms existing MoE training systems by up to 5.7x under frequent node failures and 3.4x on a real spot instance trace.
VcLLM: Video Codecs are Secretly Tensor Codecs
Jun 29, 2024



As the parameter size of large language models (LLMs) continues to expand, the need for a large memory footprint and high communication bandwidth have become significant bottlenecks for the training and inference of LLMs. To mitigate these bottlenecks, various tensor compression techniques have been proposed to reduce the data size, thereby alleviating memory requirements and communication pressure. Our research found that video codecs, despite being originally designed for compressing videos, show excellent efficiency when compressing various types of tensors. We demonstrate that video codecs can be versatile and general-purpose tensor codecs while achieving the state-of-the-art compression efficiency in various tasks. We further make use of the hardware video encoding and decoding module available on GPUs to create a framework capable of both inference and training with video codecs repurposed as tensor codecs. This greatly reduces the requirement for memory capacity and communication bandwidth, enabling training and inference of large models on consumer-grade GPUs.
Adaptive Skeleton Graph Decoding
Feb 19, 2024



Large language models (LLMs) have seen significant adoption for natural language tasks, owing their success to massive numbers of model parameters (e.g., 70B+); however, LLM inference incurs significant computation and memory costs. Recent approaches propose parallel decoding strategies, such as Skeleton-of-Thought (SoT), to improve performance by breaking prompts down into sub-problems that can be decoded in parallel; however, they often suffer from reduced response quality. Our key insight is that we can request additional information, specifically dependencies and difficulty, when generating the sub-problems to improve both response quality and performance. In this paper, we propose Skeleton Graph Decoding (SGD), which uses dependencies exposed between sub-problems to support information forwarding between dependent sub-problems for improved quality while exposing parallelization opportunities for decoding independent sub-problems. Additionally, we leverage difficulty estimates for each sub-problem to select an appropriately-sized model, improving performance without significantly reducing quality. Compared to standard autoregressive generation and SoT, SGD achieves a 1.69x speedup while improving quality by up to 51%.
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024

In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.
Serving and Optimizing Machine Learning Workflows on Heterogeneous Infrastructures
May 10, 2022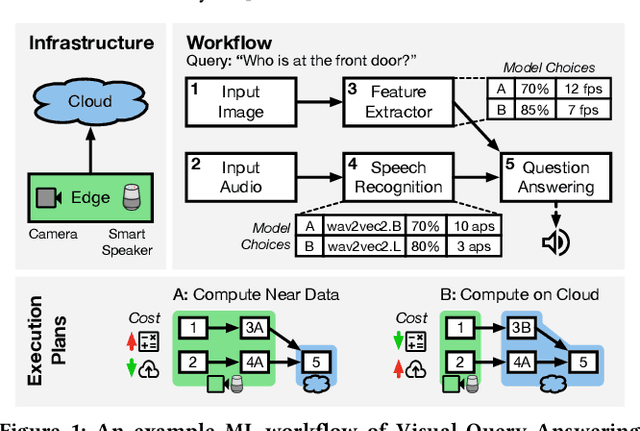
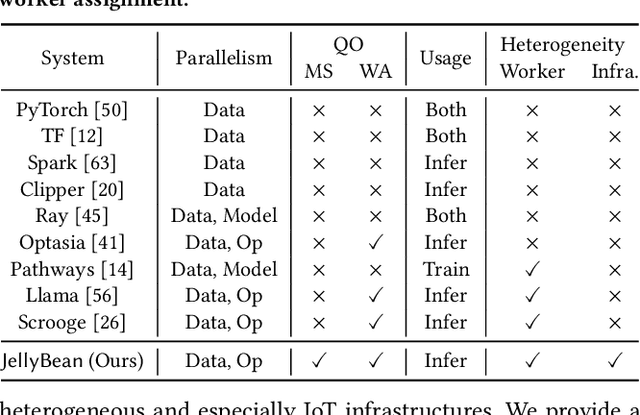
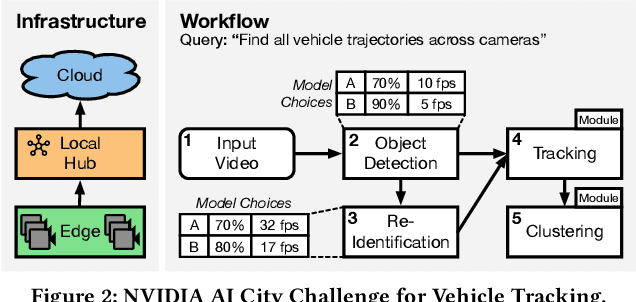

With the advent of ubiquitous deployment of smart devices and the Internet of Things, data sources for machine learning inference have increasingly moved to the edge of the network. Existing machine learning inference platforms typically assume a homogeneous infrastructure and do not take into account the more complex and tiered computing infrastructure that includes edge devices, local hubs, edge datacenters, and cloud datacenters. On the other hand, recent machine learning efforts have provided viable solutions for model compression, pruning and quantization for heterogeneous environments; for a machine learning model, now we may easily find or even generate a series of models with different tradeoffs between accuracy and efficiency. We design and implement JellyBean, a framework for serving and optimizing machine learning inference workflows on heterogeneous infrastructures. Given service-level objectives (e.g., throughput, accuracy), JellyBean automatically selects the most cost-efficient models that met the accuracy target and decides how to deploy them across different tiers of infrastructures. Evaluations show that JellyBean reduces the total serving cost of visual question answering by up to 58%, and vehicle tracking from the NVIDIA AI City Challenge by up to 36% compared with state-of-the-art model selection and worker assignment solutions. JellyBean also outperforms prior ML serving systems (e.g., Spark on the cloud) up to 5x in serving costs.