 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLBoost: Harvesting Preemptible Resources for Cost-Efficient Reinforcement Learning on LLMs
Oct 22, 2025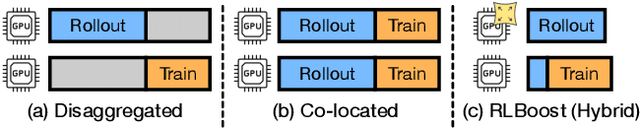
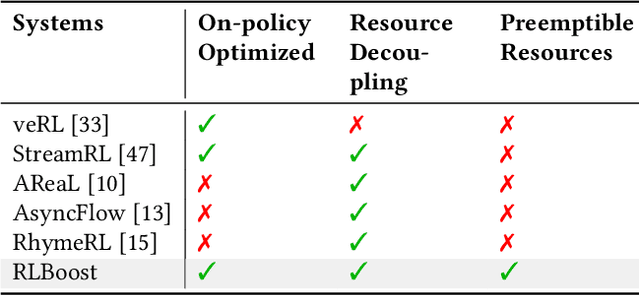
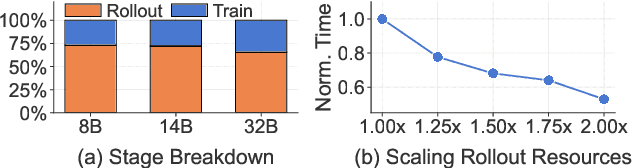
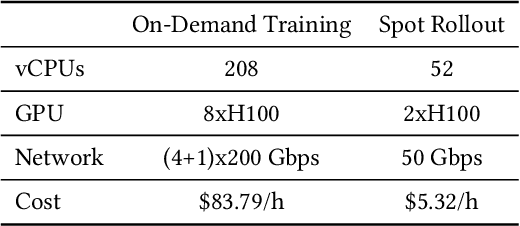
Reinforcement learning (RL) has become essential for unlocking advanced reasoning capabilities in large language models (LLMs). RL workflows involve interleaving rollout and training stages with fundamentally different resource requirements. Rollout typically dominates overall execution time, yet scales efficiently through multiple independent instances. In contrast, training requires tightly-coupled GPUs with full-mesh communication. Existing RL frameworks fall into two categories: co-located and disaggregated architectures. Co-located ones fail to address this resource tension by forcing both stages to share the same GPUs. Disaggregated architectures, without modifications of well-established RL algorithms, suffer from resource under-utilization. Meanwhile, preemptible GPU resources, i.e., spot instances on public clouds and spare capacity in production clusters, present significant cost-saving opportunities for accelerating RL workflows, if efficiently harvested for rollout. In this paper, we present RLBoost, a systematic solution for cost-efficient RL training that harvests preemptible GPU resources. Our key insight is that rollout's stateless and embarrassingly parallel nature aligns perfectly with preemptible and often fragmented resources. To efficiently utilize these resources despite frequent and unpredictable availability changes, RLBoost adopts a hybrid architecture with three key techniques: (1) adaptive rollout offload to dynamically adjust workloads on the reserved (on-demand) cluster, (2) pull-based weight transfer that quickly provisions newly available instances, and (3) token-level response collection and migration for efficient preemption handling and continuous load balancing. Extensive experiments show RLBoost increases training throughput by 1.51x-1.97x while improving cost efficiency by 28%-49% compared to using only on-demand GPU resources.
HeterMoE: Efficient Training of Mixture-of-Experts Models on Heterogeneous GPUs
Apr 04, 2025The Mixture-of-Experts (MoE) architecture has become increasingly popular as a method to scale up large language models (LLMs). To save costs, heterogeneity-aware training solutions have been proposed to utilize GPU clusters made up of both newer and older-generation GPUs. However, existing solutions are agnostic to the performance characteristics of different MoE model components (i.e., attention and expert) and do not fully utilize each GPU's compute capability. In this paper, we introduce HeterMoE, a system to efficiently train MoE models on heterogeneous GPUs. Our key insight is that newer GPUs significantly outperform older generations on attention due to architectural advancements, while older GPUs are still relatively efficient for experts. HeterMoE disaggregates attention and expert computation, where older GPUs are only assigned with expert modules. Through the proposed zebra parallelism, HeterMoE overlaps the computation on different GPUs, in addition to employing an asymmetric expert assignment strategy for fine-grained load balancing to minimize GPU idle time. Our evaluation shows that HeterMoE achieves up to 2.3x speed-up compared to existing MoE training systems, and 1.4x compared to an optimally balanced heterogeneity-aware solution. HeterMoE efficiently utilizes older GPUs by maintaining 95% training throughput on average, even with half of the GPUs in a homogeneous A40 cluster replaced with V100.
Compute Or Load KV Cache? Why Not Both?
Oct 04, 2024



Recent advancements in Large Language Models (LLMs) have significantly increased context window sizes, enabling sophisticated applications but also introducing substantial computational overheads, particularly computing key-value (KV) cache in the prefill stage. Prefix caching has emerged to save GPU power in this scenario, which saves KV cache at disks and reuse them across multiple queries. However, traditional prefix caching mechanisms often suffer from substantial latency because the speed of loading KV cache from disks to GPU memory is bottlenecked by the throughput of I/O devices. To optimize the latency of long-context prefill, we propose Cake, a novel KV cache loader, which employs a bidirectional parallelized KV cache generation strategy. Upon receiving a prefill task, Cake simultaneously and dynamically loads saved KV cache from prefix cache locations and computes KV cache on local GPUs, maximizing the utilization of available computation and I/O bandwidth resources. Additionally, Cake automatically adapts to diverse system statuses without manual parameter. tuning. In experiments on various prompt datasets, GPUs, and I/O devices, Cake offers up to 68.1% Time To First Token (TTFT) reduction compare with compute-only method and 94.6% TTFT reduction compare with I/O-only method.