 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Pixel Shortcut: on the Learning Preference of Deep Neural Networks
Paper and Code
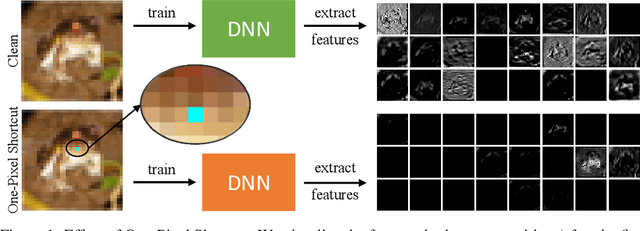
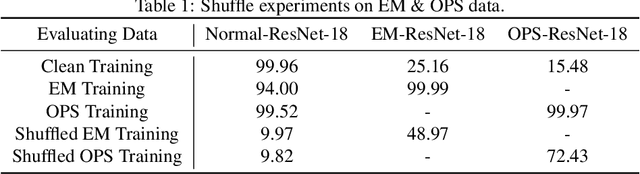
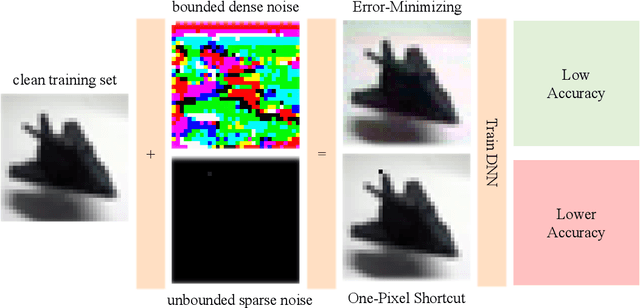
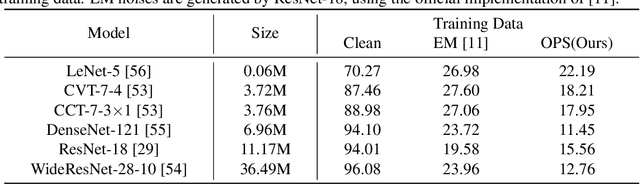
Unlearnable examples (ULEs) aim to protect data from unauthorized usage for training DNNs. Error-minimizing noise, which is injected to clean data, is one of the most successful methods for preventing DNNs from giving correct predictions on incoming new data. Nonetheless, under specific training strategies such as adversarial training, the unlearnability of error-minimizing noise will severely degrade. In addition, the transferability of error-minimizing noise is inherently limited by the mismatch between the generator model and the targeted learner model. In this paper, we investigate the mechanism of unlearnable examples and propose a novel model-free method, named \emph{One-Pixel Shortcut}, which only perturbs a single pixel of each image and makes the dataset unlearnable. Our method needs much less computational cost and obtains stronger transferability and thus can protect data from a wide range of different models. Based on this, we further introduce the first unlearnable dataset called CIFAR-10-S, which is indistinguishable from normal CIFAR-10 by human observers and can serve as a benchmark for different models or training strategies to evaluate their abilities to extract critical features from the disturbance of non-semantic representations. The original error-minimizing ULEs will lose efficiency under adversarial training, where the model can get over 83\% clean test accuracy. Meanwhile, even if adversarial training and strong data augmentation like RandAugment are applied together, the model trained on CIFAR-10-S cannot get over 50\% clean test accuracy.