 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Residual Attention Network for Single Image Super-Resolution
Dec 08, 2020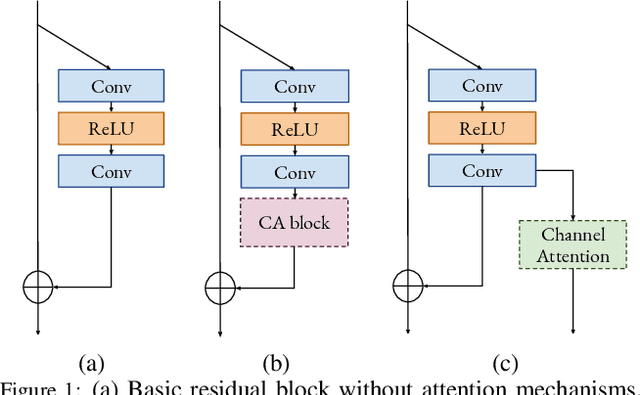
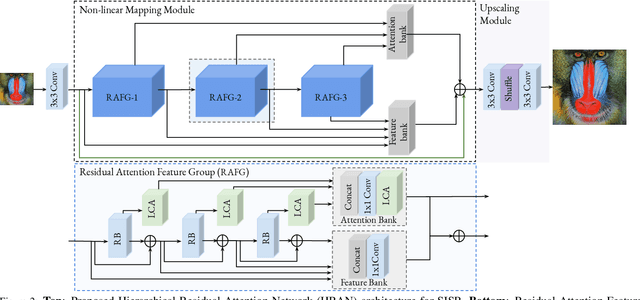
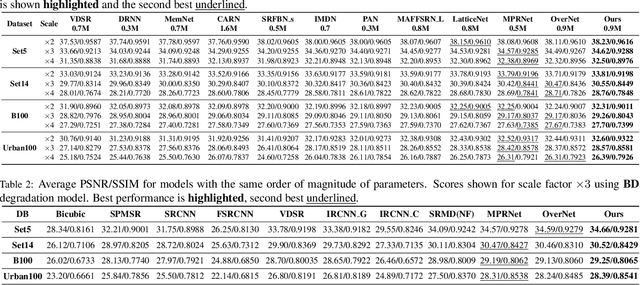
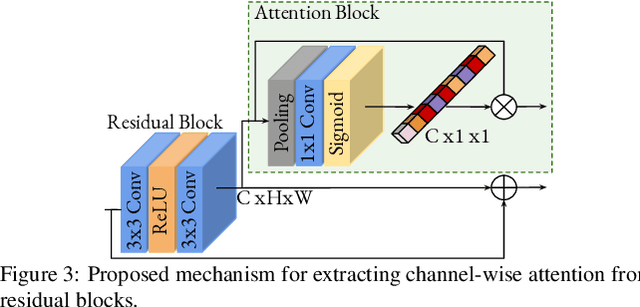
Convolutional neural networks are the most successful models in single image super-resolution. Deeper networks, residual connections, and attention mechanisms have further improved their performance. However, these strategies often improve the reconstruction performance at the expense of considerably increasing the computational cost. This paper introduces a new lightweight super-resolution model based on an efficient method for residual feature and attention aggregation. In order to make an efficient use of the residual features, these are hierarchically aggregated into feature banks for posterior usage at the network output. In parallel, a lightweight hierarchical attention mechanism extracts the most relevant features from the network into attention banks for improving the final output and preventing the information loss through the successive operations inside the network. Therefore, the processing is split into two independent paths of computation that can be simultaneously carried out, resulting in a highly efficient and effective model for reconstructing fine details on high-resolution images from their low-resolution counterparts. Our proposed architecture surpasses state-of-the-art performance in several datasets, while maintaining relatively low computation and memory footprint.
OverNet: Lightweight Multi-Scale Super-Resolution with Overscaling Network
Aug 05, 2020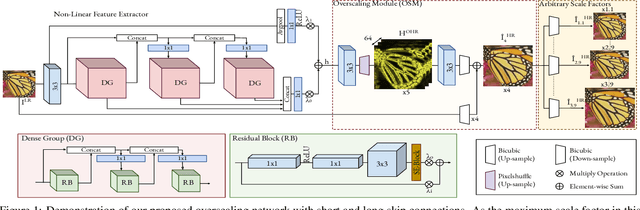



Super-resolution (SR) has achieved great success due to the development of deep convolutional neural networks (CNNs). However, as the depth and width of the networks increase, CNN-based SR methods have been faced with the challenge of computational complexity in practice. Moreover, most of them train a dedicated model for each target resolution, losing generality and increasing memory requirements. To address these limitations we introduce OverNet, a deep but lightweight convolutional network to solve SISR at arbitrary scale factors with a single model. We make the following contributions: first, we introduce a lightweight recursive feature extractor that enforces efficient reuse of information through a novel recursive structure of skip and dense connections. Second, to maximize the performance of the feature extractor we propose a reconstruction module that generates accurate high-resolution images from overscaled feature maps and can be independently used to improve existing architectures. Third, we introduce a multi-scale loss function to achieve generalization across scales. Through extensive experiments, we demonstrate that our network outperforms previous state-of-the-art results in standard benchmarks while using fewer parameters than previous approaches.