 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloAt: Flow Warping of Self-Attention for Clothing Animation Generation
Nov 22, 2024
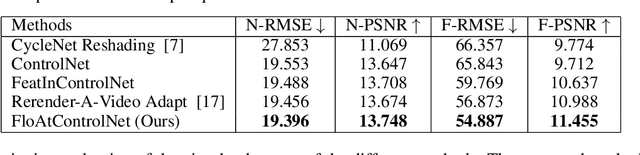
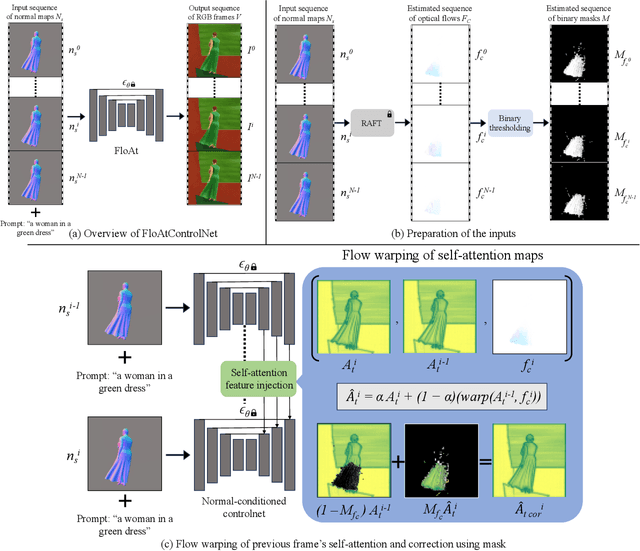
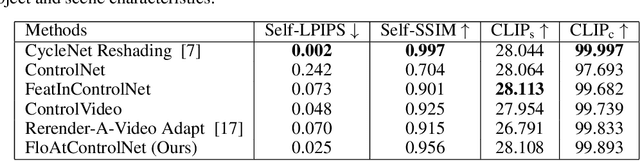
We propose a diffusion model-based approach, FloAtControlNet to generate cinemagraphs composed of animations of human clothing. We focus on human clothing like dresses, skirts and pants. The input to our model is a text prompt depicting the type of clothing and the texture of clothing like leopard, striped, or plain, and a sequence of normal maps that capture the underlying animation that we desire in the output. The backbone of our method is a normal-map conditioned ControlNet which is operated in a training-free regime. The key observation is that the underlying animation is embedded in the flow of the normal maps. We utilize the flow thus obtained to manipulate the self-attention maps of appropriate layers. Specifically, the self-attention maps of a particular layer and frame are recomputed as a linear combination of itself and the self-attention maps of the same layer and the previous frame, warped by the flow on the normal maps of the two frames. We show that manipulating the self-attention maps greatly enhances the quality of the clothing animation, making it look more natural as well as suppressing the background artifacts. Through extensive experiments, we show that the method proposed beats all baselines both qualitatively in terms of visual results and user study. Specifically, our method is able to alleviate the background flickering that exists in other diffusion model-based baselines that we consider. In addition, we show that our method beats all baselines in terms of RMSE and PSNR computed using the input normal map sequences and the normal map sequences obtained from the output RGB frames. Further, we show that well-established evaluation metrics like LPIPS, SSIM, and CLIP scores that are generally for visual quality are not necessarily suitable for capturing the subtle motions in human clothing animations.