 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS-VQA: Visual Question Answering with Compressively Sensed Images
Paper and Code
Jun 08, 2018
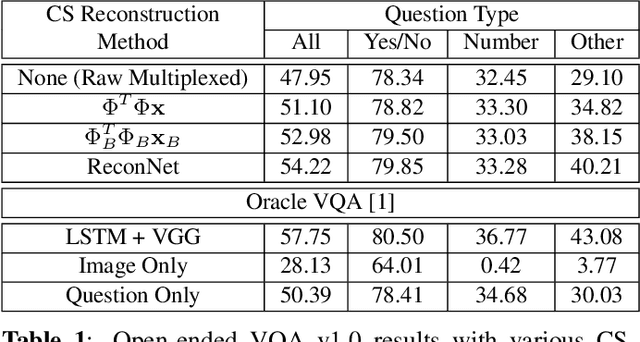
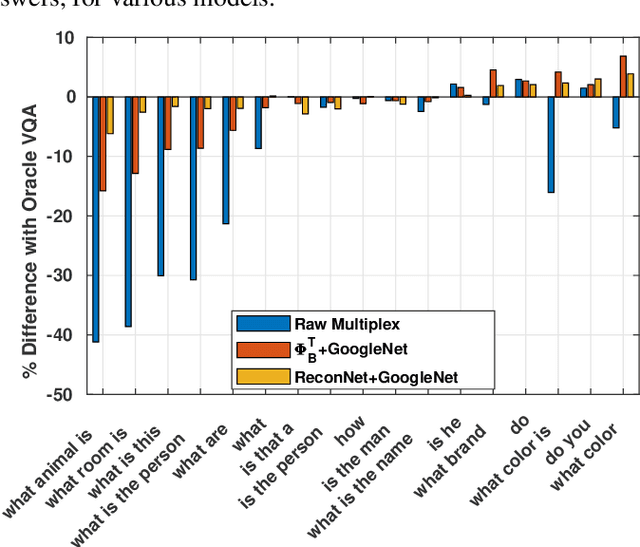

Visual Question Answering (VQA) is a complex semantic task requiring both natural language processing and visual recognition. In this paper, we explore whether VQA is solvable when images are captured in a sub-Nyquist compressive paradigm. We develop a series of deep-network architectures that exploit available compressive data to increasing degrees of accuracy, and show that VQA is indeed solvable in the compressed domain. Our results show that there is nominal degradation in VQA performance when using compressive measurements, but that accuracy can be recovered when VQA pipelines are used in conjunction with state-of-the-art deep neural networks for CS reconstruction. The results presented yield important implications for resource-constrained VQA applications.