 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARMON-E: Hierarchical Agentic Reasoning for Multimodal Oncology Notes to Extract Structured Data
Dec 22, 2025



Unstructured notes within the electronic health record (EHR) contain rich clinical information vital for cancer treatment decision making and research, yet reliably extracting structured oncology data remains challenging due to extensive variability, specialized terminology, and inconsistent document formats. Manual abstraction, although accurate, is prohibitively costly and unscalable. Existing automated approaches typically address narrow scenarios - either using synthetic datasets, restricting focus to document-level extraction, or isolating specific clinical variables (e.g., staging, biomarkers, histology) - and do not adequately handle patient-level synthesis across the large number of clinical documents containing contradictory information. In this study, we propose an agentic framework that systematically decomposes complex oncology data extraction into modular, adaptive tasks. Specifically, we use large language models (LLMs) as reasoning agents, equipped with context-sensitive retrieval and iterative synthesis capabilities, to exhaustively and comprehensively extract structured clinical variables from real-world oncology notes. Evaluated on a large-scale dataset of over 400,000 unstructured clinical notes and scanned PDF reports spanning 2,250 cancer patients, our method achieves an average F1-score of 0.93, with 100 out of 103 oncology-specific clinical variables exceeding 0.85, and critical variables (e.g., biomarkers and medications) surpassing 0.95. Moreover, integration of the agentic system into a data curation workflow resulted in 0.94 direct manual approval rate, significantly reducing annotation costs. To our knowledge, this constitutes the first exhaustive, end-to-end application of LLM-based agents for structured oncology data extraction at scale
PRISM: Patient Records Interpretation for Semantic Clinical Trial Matching using Large Language Models
Apr 27, 2024



Clinical trial matching is the task of identifying trials for which patients may be potentially eligible. Typically, this task is labor-intensive and requires detailed verification of patient electronic health records (EHRs) against the stringent inclusion and exclusion criteria of clinical trials. This process is manual, time-intensive, and challenging to scale up, resulting in many patients missing out on potential therapeutic options. Recent advancements in Large Language Models (LLMs) have made automating patient-trial matching possible, as shown in multiple concurrent research studies. However, the current approaches are confined to constrained, often synthetic datasets that do not adequately mirror the complexities encountered in real-world medical data. In this study, we present the first, end-to-end large-scale empirical evaluation of clinical trial matching using real-world EHRs. Our study showcases the capability of LLMs to accurately match patients with appropriate clinical trials. We perform experiments with proprietary LLMs, including GPT-4 and GPT-3.5, as well as our custom fine-tuned model called OncoLLM and show that OncoLLM, despite its significantly smaller size, not only outperforms GPT-3.5 but also matches the performance of qualified medical doctors. All experiments were carried out on real-world EHRs that include clinical notes and available clinical trials from a single cancer center in the United States.
Onco-Retriever: Generative Classifier for Retrieval of EHR Records in Oncology
Apr 10, 2024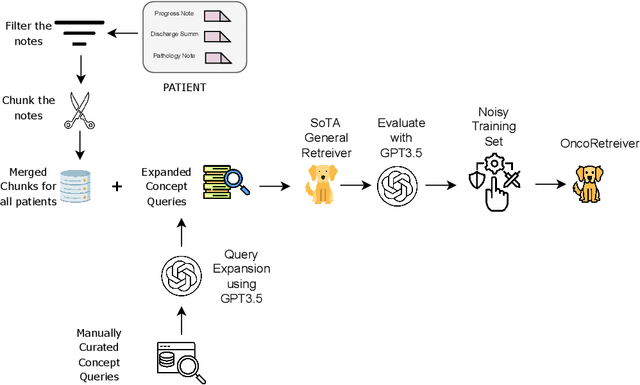
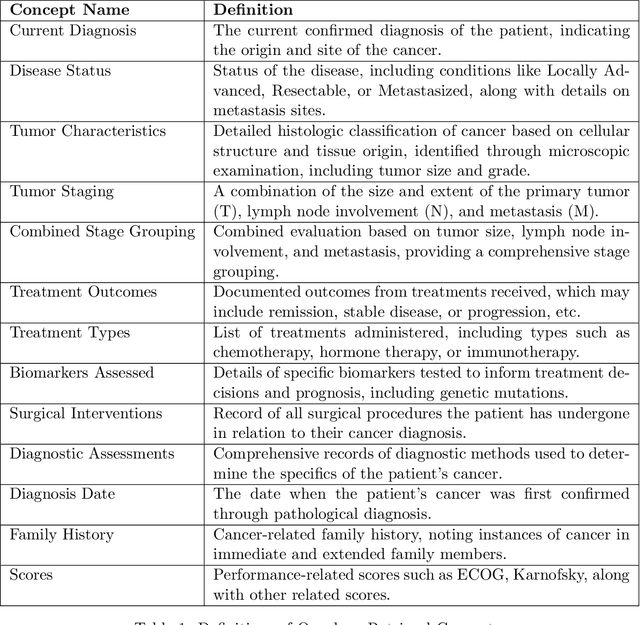
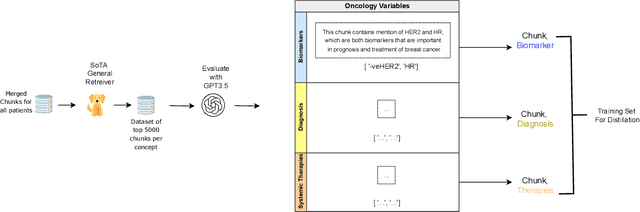
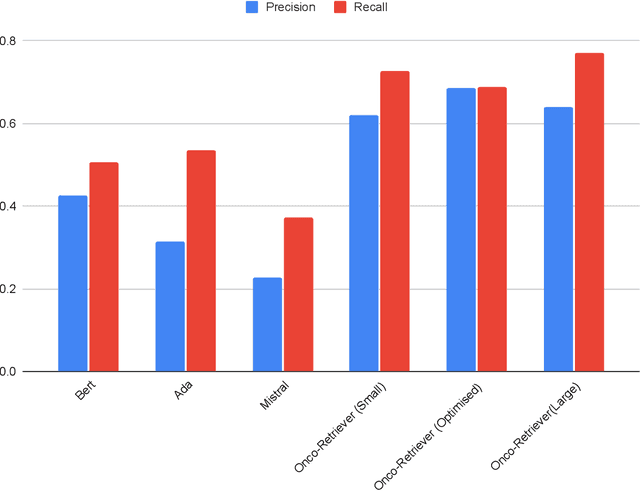
Retrieving information from EHR systems is essential for answering specific questions about patient journeys and improving the delivery of clinical care. Despite this fact, most EHR systems still rely on keyword-based searches. With the advent of generative large language models (LLMs), retrieving information can lead to better search and summarization capabilities. Such retrievers can also feed Retrieval-augmented generation (RAG) pipelines to answer any query. However, the task of retrieving information from EHR real-world clinical data contained within EHR systems in order to solve several downstream use cases is challenging due to the difficulty in creating query-document support pairs. We provide a blueprint for creating such datasets in an affordable manner using large language models. Our method results in a retriever that is 30-50 F-1 points better than propriety counterparts such as Ada and Mistral for oncology data elements. We further compare our model, called Onco-Retriever, against fine-tuned PubMedBERT model as well. We conduct an extensive manual evaluation on real-world EHR data along with latency analysis of the different models and provide a path forward for healthcare organizations to build domain-specific retrievers.
Distilling Large Language Models for Matching Patients to Clinical Trials
Dec 15, 2023The recent success of large language models (LLMs) has paved the way for their adoption in the high-stakes domain of healthcare. Specifically, the application of LLMs in patient-trial matching, which involves assessing patient eligibility against clinical trial's nuanced inclusion and exclusion criteria, has shown promise. Recent research has shown that GPT-3.5, a widely recognized LLM developed by OpenAI, can outperform existing methods with minimal 'variable engineering' by simply comparing clinical trial information against patient summaries. However, there are significant challenges associated with using closed-source proprietary LLMs like GPT-3.5 in practical healthcare applications, such as cost, privacy and reproducibility concerns. To address these issues, this study presents the first systematic examination of the efficacy of both proprietary (GPT-3.5, and GPT-4) and open-source LLMs (LLAMA 7B,13B, and 70B) for the task of patient-trial matching. Employing a multifaceted evaluation framework, we conducted extensive automated and human-centric assessments coupled with a detailed error analysis for each model. To enhance the adaptability of open-source LLMs, we have created a specialized synthetic dataset utilizing GPT-4, enabling effective fine-tuning under constrained data conditions. Our findings reveal that open-source LLMs, when fine-tuned on this limited and synthetic dataset, demonstrate performance parity with their proprietary counterparts. This presents a massive opportunity for their deployment in real-world healthcare applications. To foster further research and applications in this field, we release both the annotated evaluation dataset along with the fine-tuned LLM -- Trial-LLAMA -- for public use.
SemIE: Semantically-aware Image Extrapolation
Aug 31, 2021
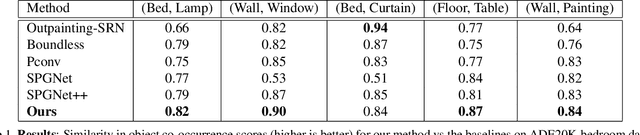
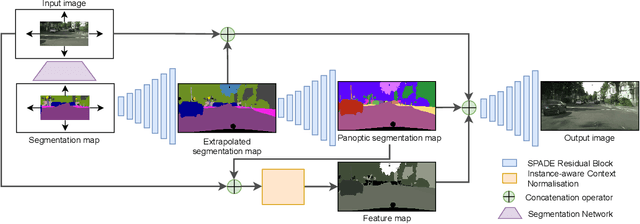
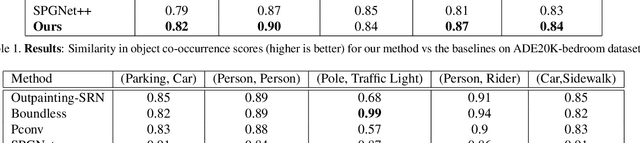
We propose a semantically-aware novel paradigm to perform image extrapolation that enables the addition of new object instances. All previous methods are limited in their capability of extrapolation to merely extending the already existing objects in the image. However, our proposed approach focuses not only on (i) extending the already present objects but also on (ii) adding new objects in the extended region based on the context. To this end, for a given image, we first obtain an object segmentation map using a state-of-the-art semantic segmentation method. The, thus, obtained segmentation map is fed into a network to compute the extrapolated semantic segmentation and the corresponding panoptic segmentation maps. The input image and the obtained segmentation maps are further utilized to generate the final extrapolated image. We conduct experiments on Cityscapes and ADE20K-bedroom datasets and show that our method outperforms all baselines in terms of FID, and similarity in object co-occurrence statistics.
DRAG: Director-Generator Language Modelling Framework for Non-Parallel Author Stylized Rewriting
Jan 28, 2021Author stylized rewriting is the task of rewriting an input text in a particular author's style. Recent works in this area have leveraged Transformer-based language models in a denoising autoencoder setup to generate author stylized text without relying on a parallel corpus of data. However, these approaches are limited by the lack of explicit control of target attributes and being entirely data-driven. In this paper, we propose a Director-Generator framework to rewrite content in the target author's style, specifically focusing on certain target attributes. We show that our proposed framework works well even with a limited-sized target author corpus. Our experiments on corpora consisting of relatively small-sized text authored by three distinct authors show significant improvements upon existing works to rewrite input texts in target author's style. Our quantitative and qualitative analyses further show that our model has better meaning retention and results in more fluent generations.
Incorporating Stylistic Lexical Preferences in Generative Language Models
Oct 22, 2020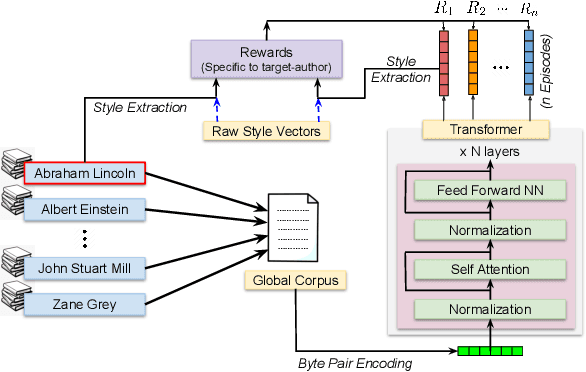

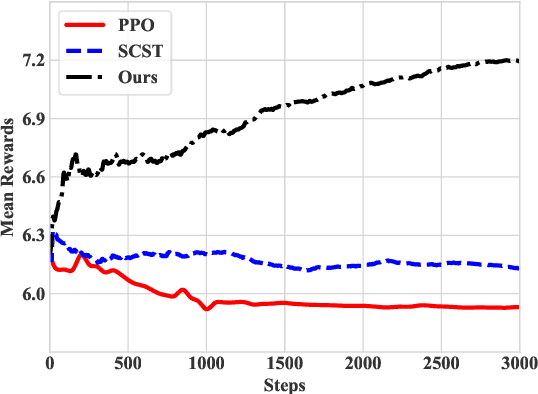
While recent advances in language modeling have resulted in powerful generation models, their generation style remains implicitly dependent on the training data and can not emulate a specific target style. Leveraging the generative capabilities of a transformer-based language models, we present an approach to induce certain target-author attributes by incorporating continuous multi-dimensional lexical preferences of an author into generative language models. We introduce rewarding strategies in a reinforcement learning framework that encourages the use of words across multiple categorical dimensions, to varying extents. Our experiments demonstrate that the proposed approach can generate text that distinctively aligns with a given target author's lexical style. We conduct quantitative and qualitative comparisons with competitive and relevant baselines to illustrate the benefits of the proposed approach.
Exploring Neural Models for Parsing Natural Language into First-Order Logic
Feb 16, 2020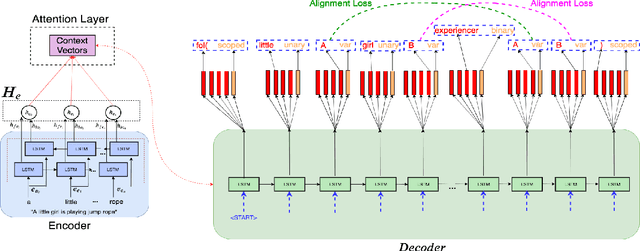
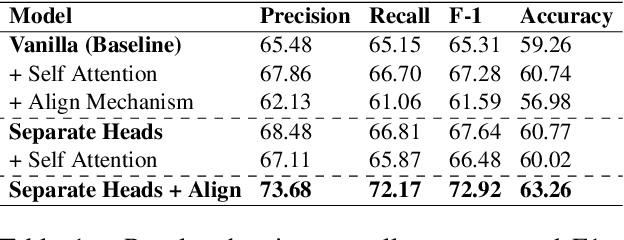
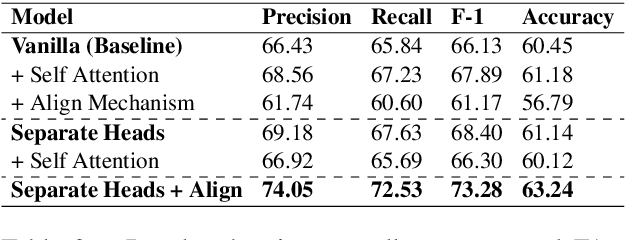
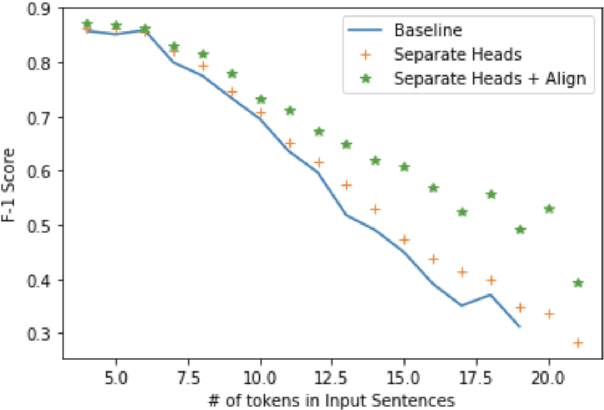
Semantic parsing is the task of obtaining machine-interpretable representations from natural language text. We consider one such formal representation - First-Order Logic (FOL) and explore the capability of neural models in parsing English sentences to FOL. We model FOL parsing as a sequence to sequence mapping task where given a natural language sentence, it is encoded into an intermediate representation using an LSTM followed by a decoder which sequentially generates the predicates in the corresponding FOL formula. We improve the standard encoder-decoder model by introducing a variable alignment mechanism that enables it to align variables across predicates in the predicted FOL. We further show the effectiveness of predicting the category of FOL entity - Unary, Binary, Variables and Scoped Entities, at each decoder step as an auxiliary task on improving the consistency of generated FOL. We perform rigorous evaluations and extensive ablations. We also aim to release our code as well as large scale FOL dataset along with models to aid further research in logic-based parsing and inference in NLP.
Generating summaries tailored to target characteristics
Dec 18, 2019
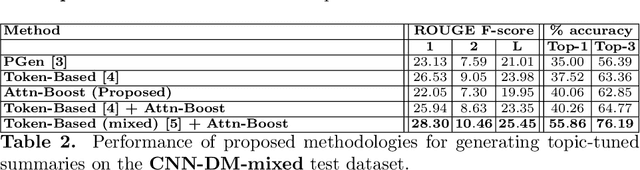
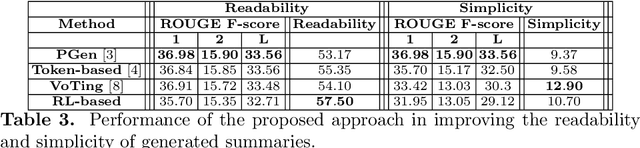
Recently, research efforts have gained pace to cater to varied user preferences while generating text summaries. While there have been attempts to incorporate a few handpicked characteristics such as length or entities, a holistic view around these preferences is missing and crucial insights on why certain characteristics should be incorporated in a specific manner are absent. With this objective, we provide a categorization around these characteristics relevant to the task of text summarization: one, focusing on what content needs to be generated and second, focusing on the stylistic aspects of the output summaries. We use our insights to provide guidelines on appropriate methods to incorporate various classes characteristics in sequence-to-sequence summarization framework. Our experiments with incorporating topics, readability and simplicity indicate the viability of the proposed prescriptions