 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARMON-E: Hierarchical Agentic Reasoning for Multimodal Oncology Notes to Extract Structured Data
Dec 22, 2025



Unstructured notes within the electronic health record (EHR) contain rich clinical information vital for cancer treatment decision making and research, yet reliably extracting structured oncology data remains challenging due to extensive variability, specialized terminology, and inconsistent document formats. Manual abstraction, although accurate, is prohibitively costly and unscalable. Existing automated approaches typically address narrow scenarios - either using synthetic datasets, restricting focus to document-level extraction, or isolating specific clinical variables (e.g., staging, biomarkers, histology) - and do not adequately handle patient-level synthesis across the large number of clinical documents containing contradictory information. In this study, we propose an agentic framework that systematically decomposes complex oncology data extraction into modular, adaptive tasks. Specifically, we use large language models (LLMs) as reasoning agents, equipped with context-sensitive retrieval and iterative synthesis capabilities, to exhaustively and comprehensively extract structured clinical variables from real-world oncology notes. Evaluated on a large-scale dataset of over 400,000 unstructured clinical notes and scanned PDF reports spanning 2,250 cancer patients, our method achieves an average F1-score of 0.93, with 100 out of 103 oncology-specific clinical variables exceeding 0.85, and critical variables (e.g., biomarkers and medications) surpassing 0.95. Moreover, integration of the agentic system into a data curation workflow resulted in 0.94 direct manual approval rate, significantly reducing annotation costs. To our knowledge, this constitutes the first exhaustive, end-to-end application of LLM-based agents for structured oncology data extraction at scale
Distance Measurement for UAVs in Deep Hazardous Tunnels
Sep 11, 2024

The localization of Unmanned aerial vehicles (UAVs) in deep tunnels is extremely challenging due to their inaccessibility and hazardous environment. Conventional outdoor localization techniques (such as using GPS) and indoor localization techniques (such as those based on WiFi, Infrared (IR), Ultra-Wideband, etc.) do not work in deep tunnels. We are developing a UAV-based system for the inspection of defects in the Deep Tunnel Sewerage System (DTSS) in Singapore. To enable the UAV localization in the DTSS, we have developed a distance measurement module based on the optical flow technique. However, the standard optical flow technique does not work well in tunnels with poor lighting and a lack of features. Thus, we have developed an enhanced optical flow algorithm with prediction, to improve the distance measurement for UAVs in deep hazardous tunnels.
PRISM: Patient Records Interpretation for Semantic Clinical Trial Matching using Large Language Models
Apr 27, 2024



Clinical trial matching is the task of identifying trials for which patients may be potentially eligible. Typically, this task is labor-intensive and requires detailed verification of patient electronic health records (EHRs) against the stringent inclusion and exclusion criteria of clinical trials. This process is manual, time-intensive, and challenging to scale up, resulting in many patients missing out on potential therapeutic options. Recent advancements in Large Language Models (LLMs) have made automating patient-trial matching possible, as shown in multiple concurrent research studies. However, the current approaches are confined to constrained, often synthetic datasets that do not adequately mirror the complexities encountered in real-world medical data. In this study, we present the first, end-to-end large-scale empirical evaluation of clinical trial matching using real-world EHRs. Our study showcases the capability of LLMs to accurately match patients with appropriate clinical trials. We perform experiments with proprietary LLMs, including GPT-4 and GPT-3.5, as well as our custom fine-tuned model called OncoLLM and show that OncoLLM, despite its significantly smaller size, not only outperforms GPT-3.5 but also matches the performance of qualified medical doctors. All experiments were carried out on real-world EHRs that include clinical notes and available clinical trials from a single cancer center in the United States.
Onco-Retriever: Generative Classifier for Retrieval of EHR Records in Oncology
Apr 10, 2024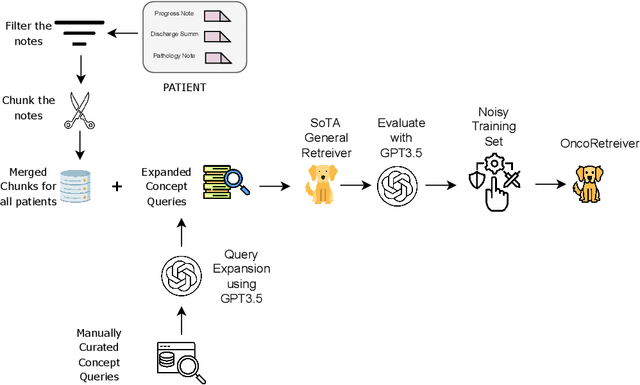
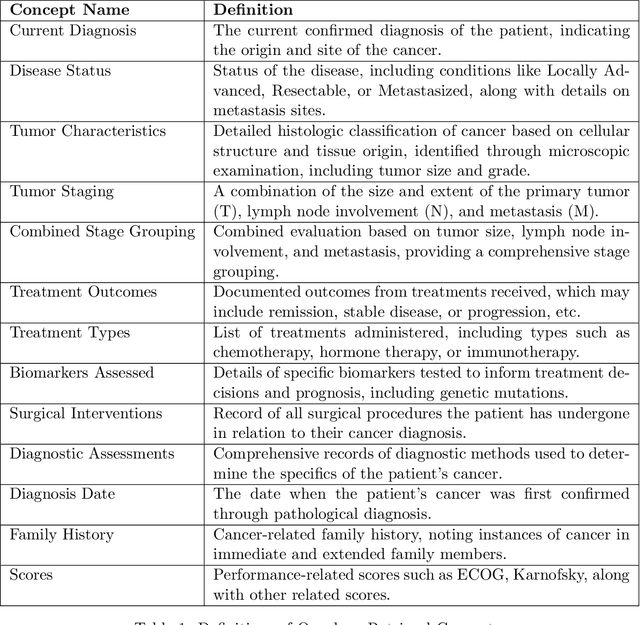
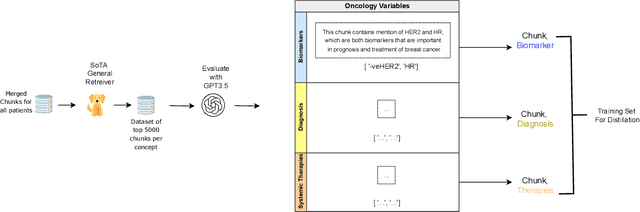
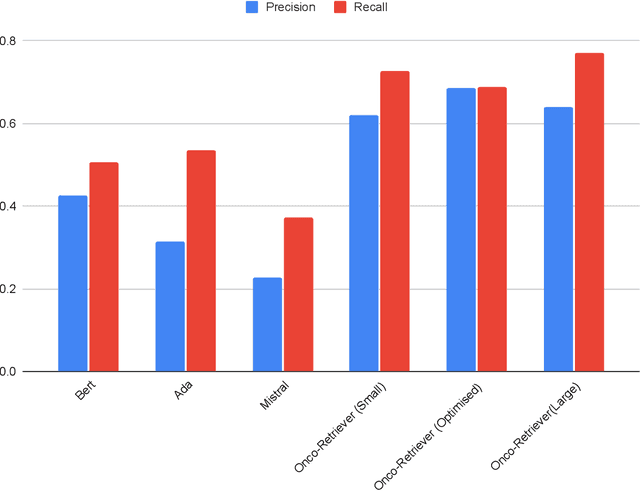
Retrieving information from EHR systems is essential for answering specific questions about patient journeys and improving the delivery of clinical care. Despite this fact, most EHR systems still rely on keyword-based searches. With the advent of generative large language models (LLMs), retrieving information can lead to better search and summarization capabilities. Such retrievers can also feed Retrieval-augmented generation (RAG) pipelines to answer any query. However, the task of retrieving information from EHR real-world clinical data contained within EHR systems in order to solve several downstream use cases is challenging due to the difficulty in creating query-document support pairs. We provide a blueprint for creating such datasets in an affordable manner using large language models. Our method results in a retriever that is 30-50 F-1 points better than propriety counterparts such as Ada and Mistral for oncology data elements. We further compare our model, called Onco-Retriever, against fine-tuned PubMedBERT model as well. We conduct an extensive manual evaluation on real-world EHR data along with latency analysis of the different models and provide a path forward for healthcare organizations to build domain-specific retrievers.
Spoken Language Identification System for English-Mandarin Code-Switching Child-Directed Speech
Jun 01, 2023
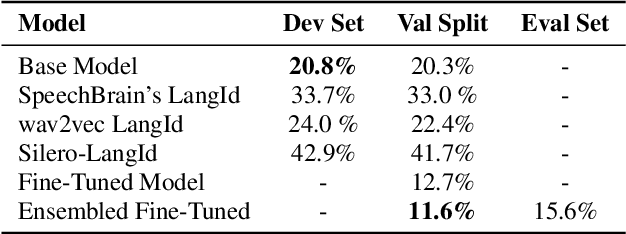
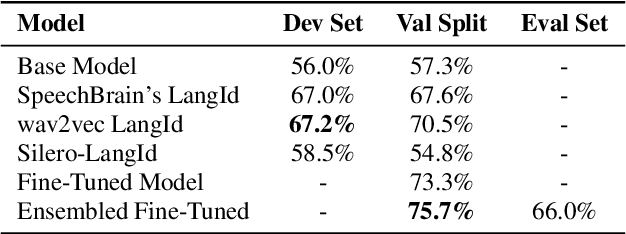

This work focuses on improving the Spoken Language Identification (LangId) system for a challenge that focuses on developing robust language identification systems that are reliable for non-standard, accented (Singaporean accent), spontaneous code-switched, and child-directed speech collected via Zoom. We propose a two-stage Encoder-Decoder-based E2E model. The encoder module consists of 1D depth-wise separable convolutions with Squeeze-and-Excitation (SE) layers with a global context. The decoder module uses an attentive temporal pooling mechanism to get fixed length time-independent feature representation. The total number of parameters in the model is around 22.1 M, which is relatively light compared to using some large-scale pre-trained speech models. We achieved an EER of 15.6% in the closed track and 11.1% in the open track (baseline system 22.1%). We also curated additional LangId data from YouTube videos (having Singaporean speakers), which will be released for public use.
Visual Search Asymmetry: Deep Nets and Humans Share Similar Inherent Biases
Jun 05, 2021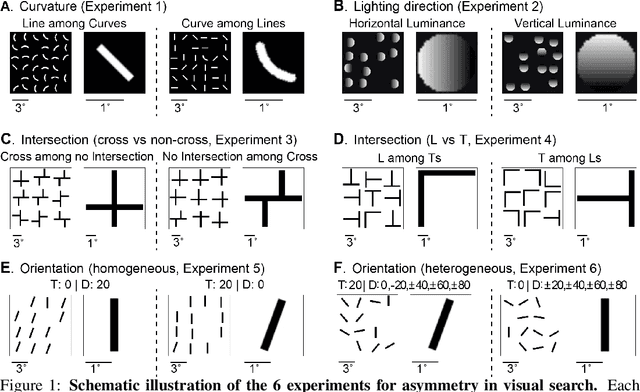
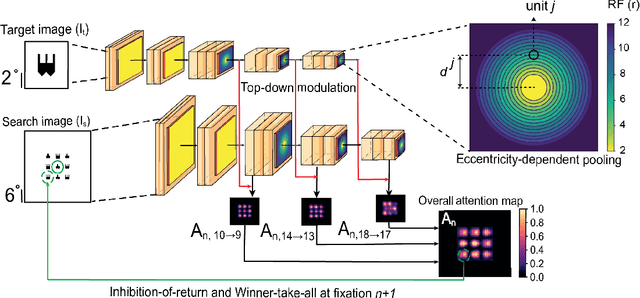
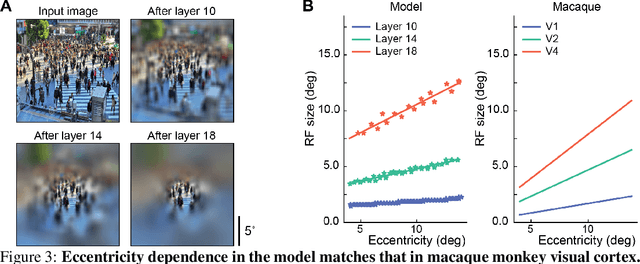
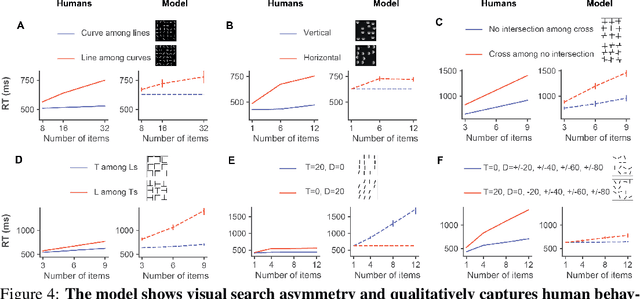
Visual search is a ubiquitous and often challenging daily task, exemplified by looking for the car keys at home or a friend in a crowd. An intriguing property of some classical search tasks is an asymmetry such that finding a target A among distractors B can be easier than finding B among A. To elucidate the mechanisms responsible for asymmetry in visual search, we propose a computational model that takes a target and a search image as inputs and produces a sequence of eye movements until the target is found. The model integrates eccentricity-dependent visual recognition with target-dependent top-down cues. We compared the model against human behavior in six paradigmatic search tasks that show asymmetry in humans. Without prior exposure to the stimuli or task-specific training, the model provides a plausible mechanism for search asymmetry. We hypothesized that the polarity of search asymmetry arises from experience with the natural environment. We tested this hypothesis by training the model on an augmented version of ImageNet where the biases of natural images were either removed or reversed. The polarity of search asymmetry disappeared or was altered depending on the training protocol. This study highlights how classical perceptual properties can emerge in neural network models, without the need for task-specific training, but rather as a consequence of the statistical properties of the developmental diet fed to the model. All source code and stimuli are publicly available https://github.com/kreimanlab/VisualSearchAsymmetry
Reinforcement Based Learning on Classification Task Could Yield Better Generalization and Adversarial Accuracy
Dec 08, 2020
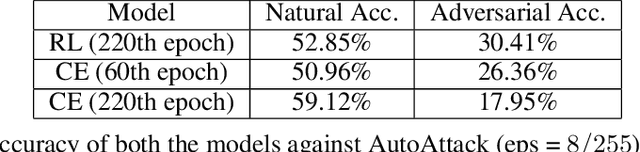
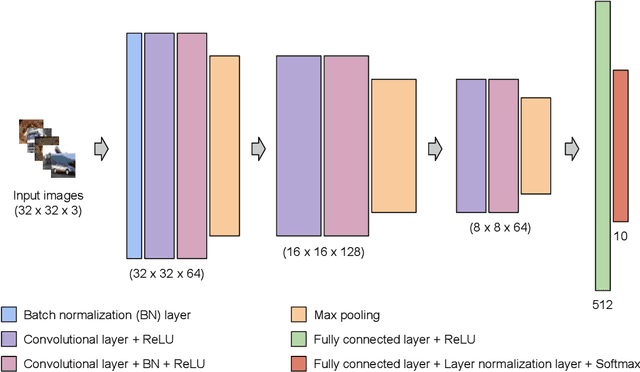
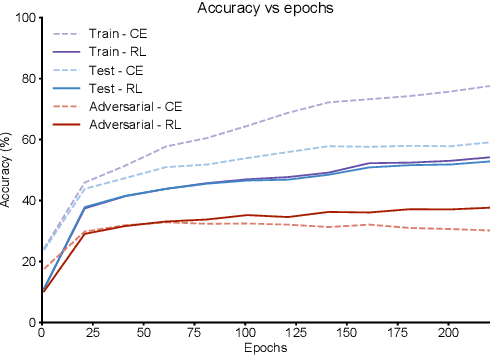
Deep Learning has become interestingly popular in computer vision, mostly attaining near or above human-level performance in various vision tasks. But recent work has also demonstrated that these deep neural networks are very vulnerable to adversarial examples (adversarial examples - inputs to a model which are naturally similar to original data but fools the model in classifying it into a wrong class). Humans are very robust against such perturbations; one possible reason could be that humans do not learn to classify based on an error between "target label" and "predicted label" but possibly due to reinforcements that they receive on their predictions. In this work, we proposed a novel method to train deep learning models on an image classification task. We used a reward-based optimization function, similar to the vanilla policy gradient method used in reinforcement learning, to train our model instead of conventional cross-entropy loss. An empirical evaluation on the cifar10 dataset showed that our method learns a more robust classifier than the same model architecture trained using cross-entropy loss function (on adversarial training). At the same time, our method shows a better generalization with the difference in test accuracy and train accuracy $< 2\%$ for most of the time compared to the cross-entropy one, whose difference most of the time remains $> 2\%$.
A More Biologically Plausible Local Learning Rule for ANNs
Nov 24, 2020



The backpropagation algorithm is often debated for its biological plausibility. However, various learning methods for neural architecture have been proposed in search of more biologically plausible learning. Most of them have tried to solve the "weight transport problem" and try to propagate errors backward in the architecture via some alternative methods. In this work, we investigated a slightly different approach that uses only the local information which captures spike timing information with no propagation of errors. The proposed learning rule is derived from the concepts of spike timing dependant plasticity and neuronal association. A preliminary evaluation done on the binary classification of MNIST and IRIS datasets with two hidden layers shows comparable performance with backpropagation. The model learned using this method also shows a possibility of better adversarial robustness against the FGSM attack compared to the model learned through backpropagation of cross-entropy loss. The local nature of learning gives a possibility of large scale distributed and parallel learning in the network. And finally, the proposed method is a more biologically sound method that can probably help in understanding how biological neurons learn different abstractions.
Investigating Emotion-Color Association in Deep Neural Networks
Nov 22, 2020
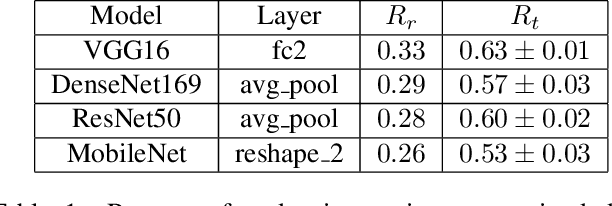
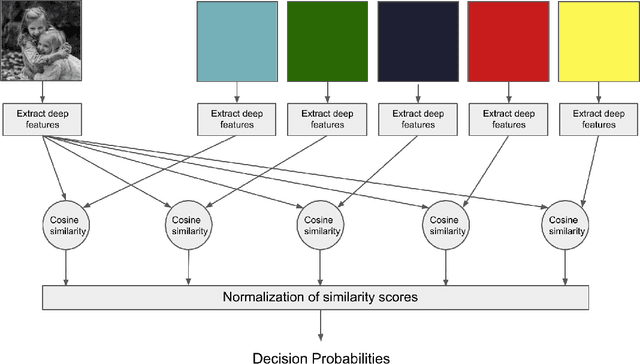
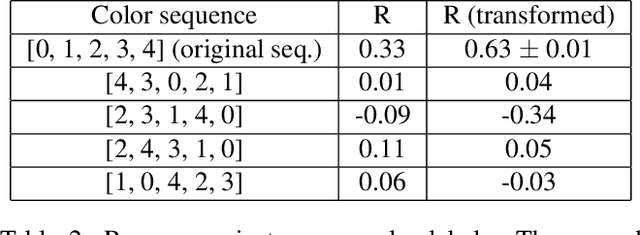
It has been found that representations learned by Deep Neural Networks (DNNs) correlate very well to neural responses measured in primates' brains and psychological representations exhibited by human similarity judgment. On another hand, past studies have shown that particular colors can be associated with specific emotion arousal in humans. Do deep neural networks also learn this behavior? In this study, we investigate if DNNs can learn implicit associations in stimuli, particularly, an emotion-color association between image stimuli. Our study was conducted in two parts. First, we collected human responses on a forced-choice decision task in which subjects were asked to select a color for a specified emotion-inducing image. Next, we modeled this decision task on neural networks using the similarity between deep representation (extracted using DNNs trained on object classification tasks) of the images and images of colors used in the task. We found that our model showed a fuzzy linear relationship between the two decision probabilities. This results in two interesting findings, 1. The representations learned by deep neural networks can indeed show an emotion-color association 2. The emotion-color association is not just random but involves some cognitive phenomena. Finally, we also show that this method can help us in the emotion classification task, specifically when there are very few examples to train the model. This analysis can be relevant to psychologists studying emotion-color associations and artificial intelligence researchers modeling emotional intelligence in machines or studying representations learned by deep neural networks.