 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoken Language Identification System for English-Mandarin Code-Switching Child-Directed Speech
Jun 01, 2023
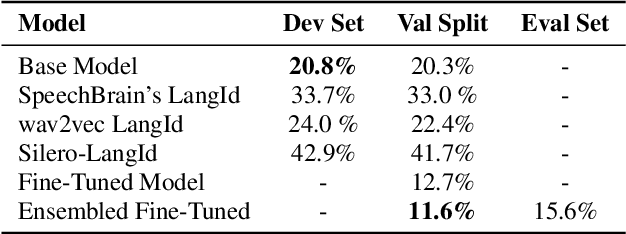
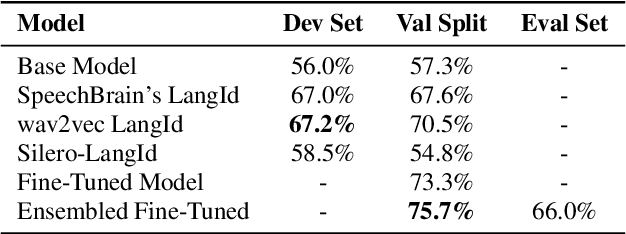

This work focuses on improving the Spoken Language Identification (LangId) system for a challenge that focuses on developing robust language identification systems that are reliable for non-standard, accented (Singaporean accent), spontaneous code-switched, and child-directed speech collected via Zoom. We propose a two-stage Encoder-Decoder-based E2E model. The encoder module consists of 1D depth-wise separable convolutions with Squeeze-and-Excitation (SE) layers with a global context. The decoder module uses an attentive temporal pooling mechanism to get fixed length time-independent feature representation. The total number of parameters in the model is around 22.1 M, which is relatively light compared to using some large-scale pre-trained speech models. We achieved an EER of 15.6% in the closed track and 11.1% in the open track (baseline system 22.1%). We also curated additional LangId data from YouTube videos (having Singaporean speakers), which will be released for public use.
SeerNet at SemEval-2018 Task 1: Domain Adaptation for Affect in Tweets
Apr 17, 2018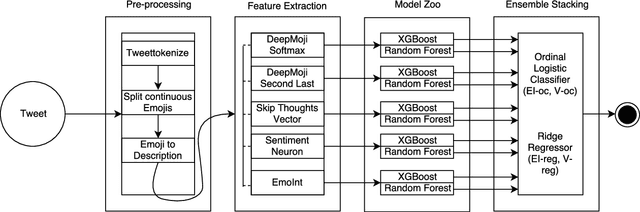
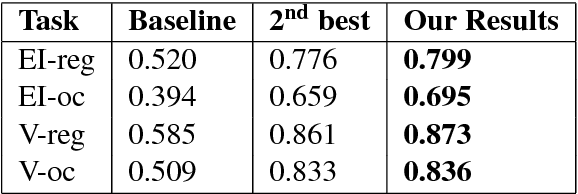


The paper describes the best performing system for the SemEval-2018 Affect in Tweets (English) sub-tasks. The system focuses on the ordinal classification and regression sub-tasks for valence and emotion. For ordinal classification valence is classified into 7 different classes ranging from -3 to 3 whereas emotion is classified into 4 different classes 0 to 3 separately for each emotion namely anger, fear, joy and sadness. The regression sub-tasks estimate the intensity of valence and each emotion. The system performs domain adaptation of 4 different models and creates an ensemble to give the final prediction. The proposed system achieved 1st position out of 75 teams which participated in the fore-mentioned sub-tasks. We outperform the baseline model by margins ranging from 49.2% to 76.4%, thus, pushing the state-of-the-art significantly.
Seernet at EmoInt-2017: Tweet Emotion Intensity Estimator
Aug 21, 2017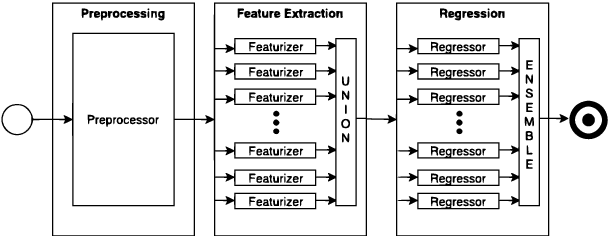
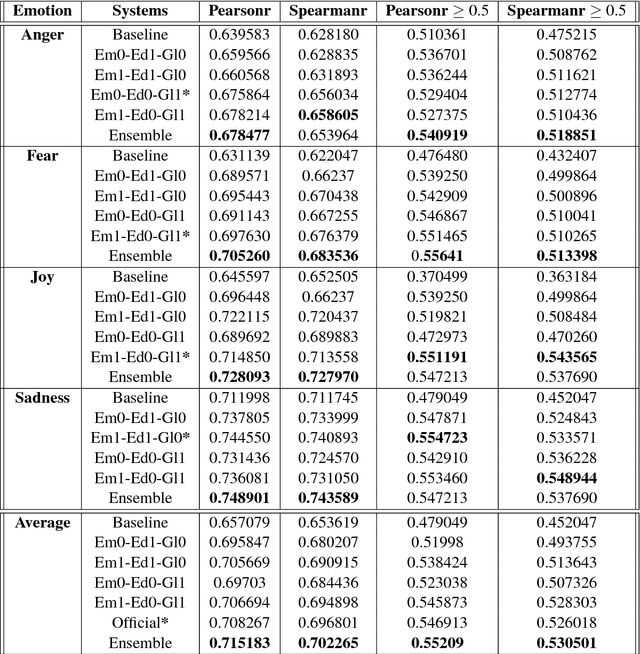
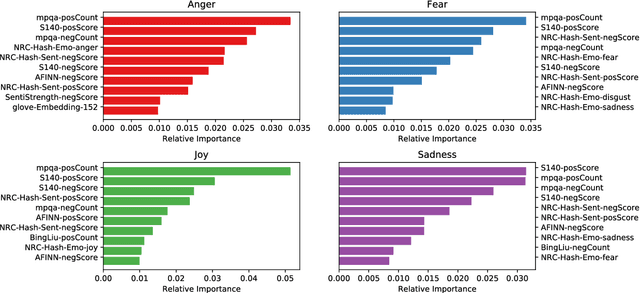
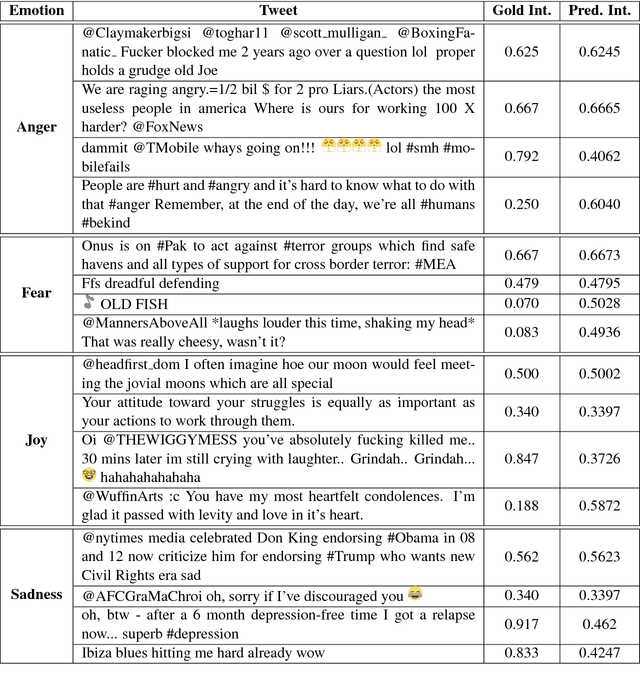
The paper describes experiments on estimating emotion intensity in tweets using a generalized regressor system. The system combines lexical, syntactic and pre-trained word embedding features, trains them on general regressors and finally combines the best performing models to create an ensemble. The proposed system stood 3rd out of 22 systems in the leaderboard of WASSA-2017 Shared Task on Emotion Intensity.
Agree to Disagree: Improving Disagreement Detection with Dual GRUs
Aug 18, 2017
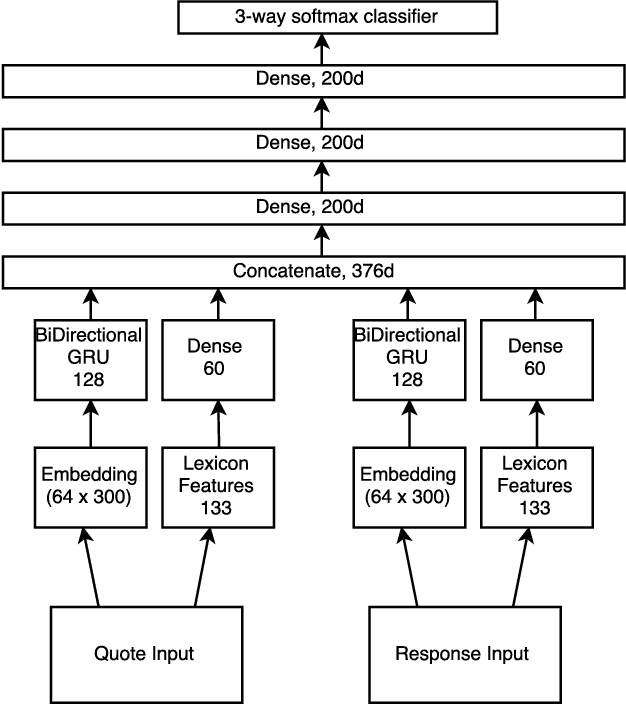
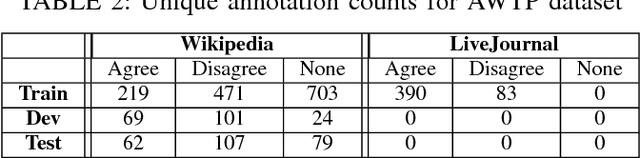
This paper presents models for detecting agreement/disagreement in online discussions. In this work we show that by using a Siamese inspired architecture to encode the discussions, we no longer need to rely on hand-crafted features to exploit the meta thread structure. We evaluate our model on existing online discussion corpora - ABCD, IAC and AWTP. Experimental results on ABCD dataset show that by fusing lexical and word embedding features, our model achieves the state of the art performance of 0.804 average F1 score. We also show that the model trained on ABCD dataset performs competitively on relatively smaller annotated datasets (IAC and AWTP).