 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoken Language Identification System for English-Mandarin Code-Switching Child-Directed Speech
Paper and Code

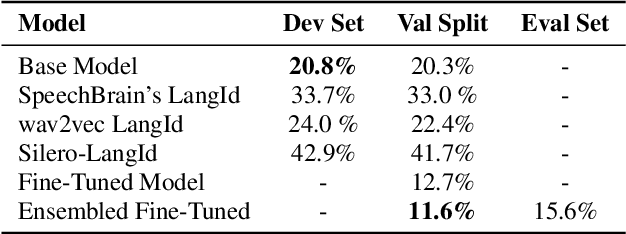
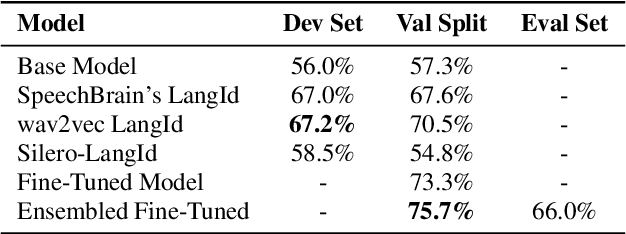

This work focuses on improving the Spoken Language Identification (LangId) system for a challenge that focuses on developing robust language identification systems that are reliable for non-standard, accented (Singaporean accent), spontaneous code-switched, and child-directed speech collected via Zoom. We propose a two-stage Encoder-Decoder-based E2E model. The encoder module consists of 1D depth-wise separable convolutions with Squeeze-and-Excitation (SE) layers with a global context. The decoder module uses an attentive temporal pooling mechanism to get fixed length time-independent feature representation. The total number of parameters in the model is around 22.1 M, which is relatively light compared to using some large-scale pre-trained speech models. We achieved an EER of 15.6% in the closed track and 11.1% in the open track (baseline system 22.1%). We also curated additional LangId data from YouTube videos (having Singaporean speakers), which will be released for public use.