 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving performance and inference on audio classification tasks using capsule networks
Feb 13, 2019



Classification of audio samples is an important part of many auditory systems. Deep learning models based on the Convolutional and the Recurrent layers are state-of-the-art in many such tasks. In this paper, we approach audio classification tasks using capsule networks trained by recently proposed dynamic routing-by-agreement mechanism. We propose an architecture for capsule networks fit for audio classification tasks and study the impact of various parameters on classification accuracy. Further, we suggest modifications for regularization and multi-label classification. We also develop insights into the data using capsule outputs and show the utility of the learned network for transfer learning. We perform experiments on 7 datasets of different domains and sizes and show significant improvements in performance compared to strong baseline models. To the best of our knowledge, this is the first detailed study about the application of capsule networks in the audio domain.
SeerNet at SemEval-2018 Task 1: Domain Adaptation for Affect in Tweets
Apr 17, 2018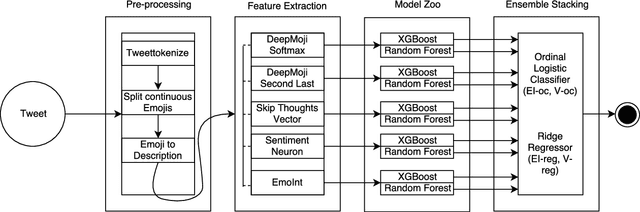
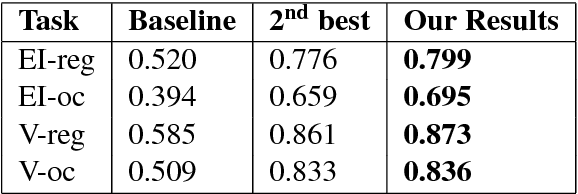


The paper describes the best performing system for the SemEval-2018 Affect in Tweets (English) sub-tasks. The system focuses on the ordinal classification and regression sub-tasks for valence and emotion. For ordinal classification valence is classified into 7 different classes ranging from -3 to 3 whereas emotion is classified into 4 different classes 0 to 3 separately for each emotion namely anger, fear, joy and sadness. The regression sub-tasks estimate the intensity of valence and each emotion. The system performs domain adaptation of 4 different models and creates an ensemble to give the final prediction. The proposed system achieved 1st position out of 75 teams which participated in the fore-mentioned sub-tasks. We outperform the baseline model by margins ranging from 49.2% to 76.4%, thus, pushing the state-of-the-art significantly.