 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Farming: From Berry Picking to Berry Growing
Jan 18, 2026The classic paradigms of Berry Picking and Information Foraging Theory have framed users as gatherers, opportunistically searching across distributed sources to satisfy evolving information needs. However, the rise of GenAI is driving a fundamental transformation in how people produce, structure, and reuse information - one that these paradigms no longer fully capture. This transformation is analogous to the Neolithic Revolution, when societies shifted from hunting and gathering to cultivation. Generative technologies empower users to "farm" information by planting seeds in the form of prompts, cultivating workflows over time, and harvesting richly structured, relevant yields within their own plots, rather than foraging across others people's patches. In this perspectives paper, we introduce the notion of Information Farming as a conceptual framework and argue that it represents a natural evolution in how people engage with information. Drawing on historical analogy and empirical evidence, we examine the benefits and opportunities of information farming, its implications for design and evaluation, and the accompanying risks posed by this transition. We hypothesize that as GenAI technologies proliferate, cultivating information will increasingly supplant transient, patch-based foraging as a dominant mode of engagement, marking a broader shift in human-information interaction and its study.
* ACM CHIIR 2026
All Claims Are Equal, but Some Claims Are More Equal Than Others: Importance-Sensitive Factuality Evaluation of LLM Generations
Oct 08, 2025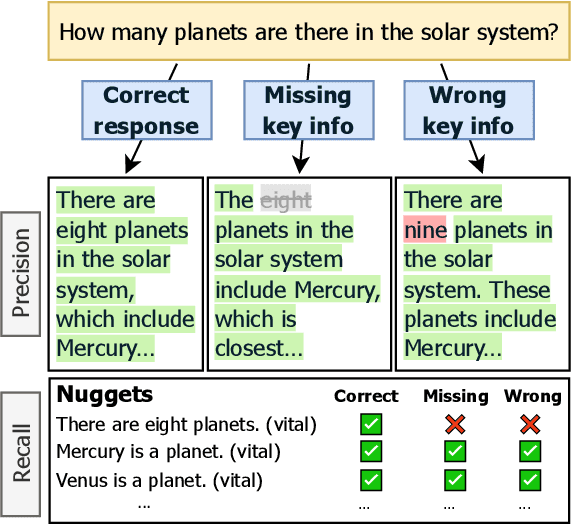
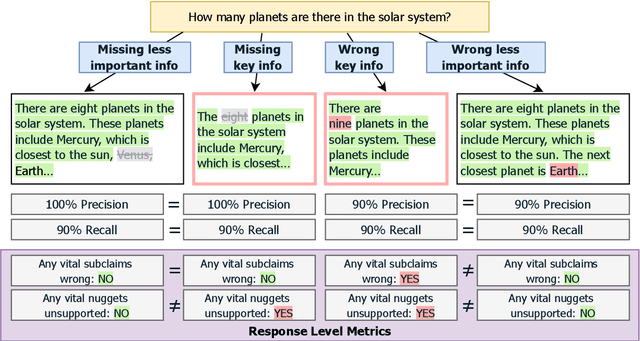

Existing methods for evaluating the factuality of large language model (LLM) responses treat all claims as equally important. This results in misleading evaluations when vital information is missing or incorrect as it receives the same weight as peripheral details, raising the question: how can we reliably detect such differences when there are errors in key information? Current approaches that measure factuality tend to be insensitive to omitted or false key information. To investigate this lack of sensitivity, we construct VITALERRORS, a benchmark of 6,733 queries with minimally altered LLM responses designed to omit or falsify key information. Using this dataset, we demonstrate the insensitivities of existing evaluation metrics to key information errors. To address this gap, we introduce VITAL, a set of metrics that provide greater sensitivity in measuring the factuality of responses by incorporating the relevance and importance of claims with respect to the query. Our analysis demonstrates that VITAL metrics more reliably detect errors in key information than previous methods. Our dataset, metrics, and analysis provide a foundation for more accurate and robust assessment of LLM factuality.
Improving the Reusability of Conversational Search Test Collections
Mar 12, 2025Incomplete relevance judgments limit the reusability of test collections. When new systems are compared to previous systems that contributed to the pool, they often face a disadvantage. This is due to pockets of unjudged documents (called holes) in the test collection that the new systems return. The very nature of Conversational Search (CS) means that these holes are potentially larger and more problematic when evaluating systems. In this paper, we aim to extend CS test collections by employing Large Language Models (LLMs) to fill holes by leveraging existing judgments. We explore this problem using TREC iKAT 23 and TREC CAsT 22 collections, where information needs are highly dynamic and the responses are much more varied, leaving bigger holes to fill. Our experiments reveal that CS collections show a trend towards less reusability in deeper turns. Also, fine-tuning the Llama 3.1 model leads to high agreement with human assessors, while few-shot prompting the ChatGPT results in low agreement with humans. Consequently, filling the holes of a new system using ChatGPT leads to a higher change in the location of the new system. While regenerating the assessment pool with few-shot prompting the ChatGPT model and using it for evaluation achieves a high rank correlation with human-assessed pools. We show that filling the holes using few-shot training the Llama 3.1 model enables a fairer comparison between the new system and the systems contributed to the pool. Our hole-filling model based on few-shot training of the Llama 3.1 model can improve the reusability of test collections.
Conversational Gold: Evaluating Personalized Conversational Search System using Gold Nuggets
Mar 12, 2025The rise of personalized conversational search systems has been driven by advancements in Large Language Models (LLMs), enabling these systems to retrieve and generate answers for complex information needs. However, the automatic evaluation of responses generated by Retrieval Augmented Generation (RAG) systems remains an understudied challenge. In this paper, we introduce a new resource for assessing the retrieval effectiveness and relevance of response generated by RAG systems, using a nugget-based evaluation framework. Built upon the foundation of TREC iKAT 2023, our dataset extends to the TREC iKAT 2024 collection, which includes 17 conversations and 20,575 relevance passage assessments, together with 2,279 extracted gold nuggets, and 62 manually written gold answers from NIST assessors. While maintaining the core structure of its predecessor, this new collection enables a deeper exploration of generation tasks in conversational settings. Key improvements in iKAT 2024 include: (1) ``gold nuggets'' -- concise, essential pieces of information extracted from relevant passages of the collection -- which serve as a foundation for automatic response evaluation; (2) manually written answers to provide a gold standard for response evaluation; (3) unanswerable questions to evaluate model hallucination; (4) expanded user personas, providing richer contextual grounding; and (5) a transition from Personal Text Knowledge Base (PTKB) ranking to PTKB classification and selection. Built on this resource, we provide a framework for long-form answer generation evaluation, involving nuggets extraction and nuggets matching, linked to retrieval. This establishes a solid resource for advancing research in personalized conversational search and long-form answer generation. Our resources are publicly available at https://github.com/irlabamsterdam/CONE-RAG.
PRISM: A Methodology for Auditing Biases in Large Language Models
Oct 24, 2024Auditing Large Language Models (LLMs) to discover their biases and preferences is an emerging challenge in creating Responsible Artificial Intelligence (AI). While various methods have been proposed to elicit the preferences of such models, countermeasures have been taken by LLM trainers, such that LLMs hide, obfuscate or point blank refuse to disclosure their positions on certain subjects. This paper presents PRISM, a flexible, inquiry-based methodology for auditing LLMs - that seeks to illicit such positions indirectly through task-based inquiry prompting rather than direct inquiry of said preferences. To demonstrate the utility of the methodology, we applied PRISM on the Political Compass Test, where we assessed the political leanings of twenty-one LLMs from seven providers. We show LLMs, by default, espouse positions that are economically left and socially liberal (consistent with prior work). We also show the space of positions that these models are willing to espouse - where some models are more constrained and less compliant than others - while others are more neutral and objective. In sum, PRISM can more reliably probe and audit LLMs to understand their preferences, biases and constraints.
Evaluation of Attribution Bias in Retrieval-Augmented Large Language Models
Oct 16, 2024
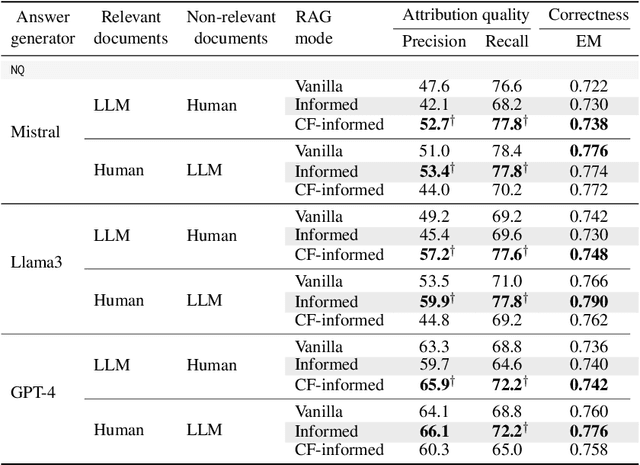
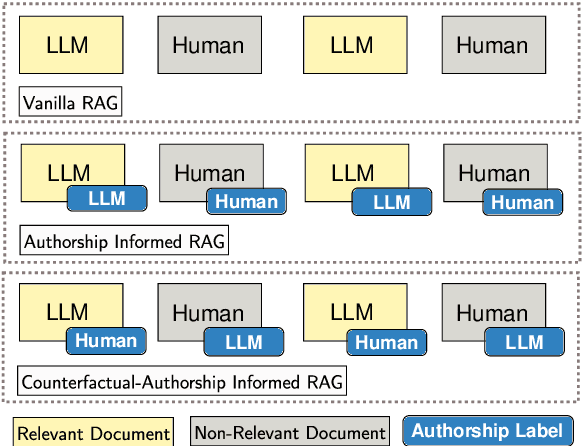

Attributing answers to source documents is an approach used to enhance the verifiability of a model's output in retrieval augmented generation (RAG). Prior work has mainly focused on improving and evaluating the attribution quality of large language models (LLMs) in RAG, but this may come at the expense of inducing biases in the attribution of answers. We define and examine two aspects in the evaluation of LLMs in RAG pipelines, namely attribution sensitivity and bias with respect to authorship information. We explicitly inform an LLM about the authors of source documents, instruct it to attribute its answers, and analyze (i) how sensitive the LLM's output is to the author of source documents, and (ii) whether the LLM exhibits a bias towards human-written or AI-generated source documents. We design an experimental setup in which we use counterfactual evaluation to study three LLMs in terms of their attribution sensitivity and bias in RAG pipelines. Our results show that adding authorship information to source documents can significantly change the attribution quality of LLMs by 3% to 18%. Moreover, we show that LLMs can have an attribution bias towards explicit human authorship, which can serve as a competing hypothesis for findings of prior work that shows that LLM-generated content may be preferred over human-written contents. Our findings indicate that metadata of source documents can influence LLMs' trust, and how they attribute their answers. Furthermore, our research highlights attribution bias and sensitivity as a novel aspect of brittleness in LLMs.
Can We Use Large Language Models to Fill Relevance Judgment Holes?
May 09, 2024



Incomplete relevance judgments limit the re-usability of test collections. When new systems are compared against previous systems used to build the pool of judged documents, they often do so at a disadvantage due to the ``holes'' in test collection (i.e., pockets of un-assessed documents returned by the new system). In this paper, we take initial steps towards extending existing test collections by employing Large Language Models (LLM) to fill the holes by leveraging and grounding the method using existing human judgments. We explore this problem in the context of Conversational Search using TREC iKAT, where information needs are highly dynamic and the responses (and, the results retrieved) are much more varied (leaving bigger holes). While previous work has shown that automatic judgments from LLMs result in highly correlated rankings, we find substantially lower correlates when human plus automatic judgments are used (regardless of LLM, one/two/few shot, or fine-tuned). We further find that, depending on the LLM employed, new runs will be highly favored (or penalized), and this effect is magnified proportionally to the size of the holes. Instead, one should generate the LLM annotations on the whole document pool to achieve more consistent rankings with human-generated labels. Future work is required to prompt engineering and fine-tuning LLMs to reflect and represent the human annotations, in order to ground and align the models, such that they are more fit for purpose.
TREC iKAT 2023: A Test Collection for Evaluating Conversational and Interactive Knowledge Assistants
May 04, 2024Conversational information seeking has evolved rapidly in the last few years with the development of Large Language Models (LLMs), providing the basis for interpreting and responding in a naturalistic manner to user requests. The extended TREC Interactive Knowledge Assistance Track (iKAT) collection aims to enable researchers to test and evaluate their Conversational Search Agents (CSA). The collection contains a set of 36 personalized dialogues over 20 different topics each coupled with a Personal Text Knowledge Base (PTKB) that defines the bespoke user personas. A total of 344 turns with approximately 26,000 passages are provided as assessments on relevance, as well as additional assessments on generated responses over four key dimensions: relevance, completeness, groundedness, and naturalness. The collection challenges CSA to efficiently navigate diverse personal contexts, elicit pertinent persona information, and employ context for relevant conversations. The integration of a PTKB and the emphasis on decisional search tasks contribute to the uniqueness of this test collection, making it an essential benchmark for advancing research in conversational and interactive knowledge assistants.
A Conceptual Framework for Conversational Search and Recommendation: Conceptualizing Agent-Human Interactions During the Conversational Search Process
Apr 12, 2024
The conversational search task aims to enable a user to resolve information needs via natural language dialogue with an agent. In this paper, we aim to develop a conceptual framework of the actions and intents of users and agents explaining how these actions enable the user to explore the search space and resolve their information need. We outline the different actions and intents, before discussing key decision points in the conversation where the agent needs to decide how to steer the conversational search process to a successful and/or satisfactory conclusion. Essentially, this paper provides a conceptualization of the conversational search process between an agent and user, which provides a framework and a starting point for research, development and evaluation of conversational search agents.
Accessibility in Information Retrieval
Apr 12, 2024This paper introduces the concept of accessibility from the field of transportation planning and adopts it within the context of Information Retrieval (IR). An analogy is drawn between the fields, which motivates the development of document accessibility measures for IR systems. Considering the accessibility of documents within a collection given an IR System provides a different perspective on the analysis and evaluation of such systems which could be used to inform the design, tuning and management of current and future IR systems.