 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Gold: Evaluating Personalized Conversational Search System using Gold Nuggets
Mar 12, 2025The rise of personalized conversational search systems has been driven by advancements in Large Language Models (LLMs), enabling these systems to retrieve and generate answers for complex information needs. However, the automatic evaluation of responses generated by Retrieval Augmented Generation (RAG) systems remains an understudied challenge. In this paper, we introduce a new resource for assessing the retrieval effectiveness and relevance of response generated by RAG systems, using a nugget-based evaluation framework. Built upon the foundation of TREC iKAT 2023, our dataset extends to the TREC iKAT 2024 collection, which includes 17 conversations and 20,575 relevance passage assessments, together with 2,279 extracted gold nuggets, and 62 manually written gold answers from NIST assessors. While maintaining the core structure of its predecessor, this new collection enables a deeper exploration of generation tasks in conversational settings. Key improvements in iKAT 2024 include: (1) ``gold nuggets'' -- concise, essential pieces of information extracted from relevant passages of the collection -- which serve as a foundation for automatic response evaluation; (2) manually written answers to provide a gold standard for response evaluation; (3) unanswerable questions to evaluate model hallucination; (4) expanded user personas, providing richer contextual grounding; and (5) a transition from Personal Text Knowledge Base (PTKB) ranking to PTKB classification and selection. Built on this resource, we provide a framework for long-form answer generation evaluation, involving nuggets extraction and nuggets matching, linked to retrieval. This establishes a solid resource for advancing research in personalized conversational search and long-form answer generation. Our resources are publicly available at https://github.com/irlabamsterdam/CONE-RAG.
TREC iKAT 2023: A Test Collection for Evaluating Conversational and Interactive Knowledge Assistants
May 04, 2024Conversational information seeking has evolved rapidly in the last few years with the development of Large Language Models (LLMs), providing the basis for interpreting and responding in a naturalistic manner to user requests. The extended TREC Interactive Knowledge Assistance Track (iKAT) collection aims to enable researchers to test and evaluate their Conversational Search Agents (CSA). The collection contains a set of 36 personalized dialogues over 20 different topics each coupled with a Personal Text Knowledge Base (PTKB) that defines the bespoke user personas. A total of 344 turns with approximately 26,000 passages are provided as assessments on relevance, as well as additional assessments on generated responses over four key dimensions: relevance, completeness, groundedness, and naturalness. The collection challenges CSA to efficiently navigate diverse personal contexts, elicit pertinent persona information, and employ context for relevant conversations. The integration of a PTKB and the emphasis on decisional search tasks contribute to the uniqueness of this test collection, making it an essential benchmark for advancing research in conversational and interactive knowledge assistants.
A Conceptual Framework for Conversational Search and Recommendation: Conceptualizing Agent-Human Interactions During the Conversational Search Process
Apr 12, 2024
The conversational search task aims to enable a user to resolve information needs via natural language dialogue with an agent. In this paper, we aim to develop a conceptual framework of the actions and intents of users and agents explaining how these actions enable the user to explore the search space and resolve their information need. We outline the different actions and intents, before discussing key decision points in the conversation where the agent needs to decide how to steer the conversational search process to a successful and/or satisfactory conclusion. Essentially, this paper provides a conceptualization of the conversational search process between an agent and user, which provides a framework and a starting point for research, development and evaluation of conversational search agents.
TREC iKAT 2023: The Interactive Knowledge Assistance Track Overview
Jan 02, 2024



Conversational Information Seeking stands as a pivotal research area with significant contributions from previous works. The TREC Interactive Knowledge Assistance Track (iKAT) builds on the foundational work of the TREC Conversational Assistance Track (CAsT). However, iKAT distinctively emphasizes the creation and research of conversational search agents that adapt responses based on user's prior interactions and present context. The challenge lies in enabling Conversational Search Agents (CSA) to incorporate this personalized context to efficiency and effectively guide users through the relevant information to them. iKAT also emphasizes decisional search tasks, where users sift through data and information to weigh up options in order to reach a conclusion or perform an action. These tasks, prevalent in everyday information-seeking decisions -- be it related to travel, health, or shopping -- often revolve around a subset of high-level information operators where queries or questions about the information space include: finding options, comparing options, identifying the pros and cons of options, etc. Given the different personas and their information need (expressed through the sequence of questions), diverse conversation trajectories will arise -- because the answers to these similar queries will be very different. In this paper, we report on the first year of TREC iKAT, describing the task, topics, data collection, and evaluation framework. We further review the submissions and summarize the findings.
How Deep is your Learning: the DL-HARD Annotated Deep Learning Dataset
May 17, 2021
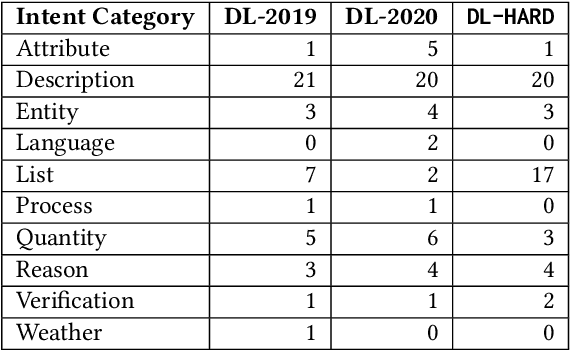
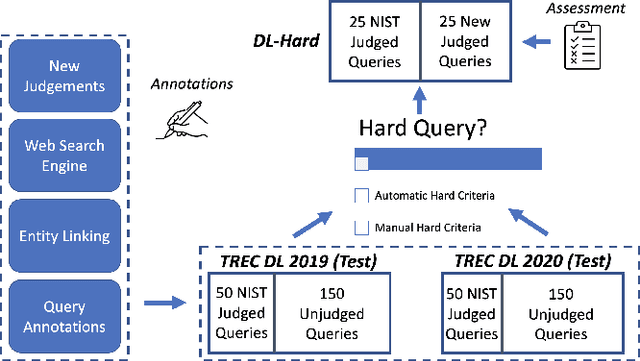
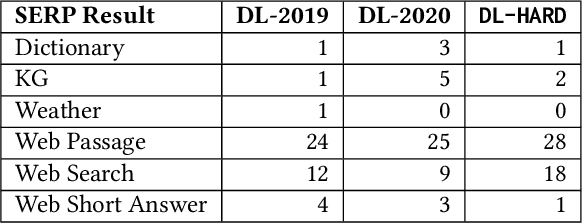
Deep Learning Hard (DL-HARD) is a new annotated dataset designed to more effectively evaluate neural ranking models on complex topics. It builds on TREC Deep Learning (DL) topics by extensively annotating them with question intent categories, answer types, wikified entities, topic categories, and result type metadata from a commercial web search engine. Based on this data, we introduce a framework for identifying challenging queries. DL-HARD contains fifty topics from the official DL 2019/2020 evaluation benchmark, half of which are newly and independently assessed. We perform experiments using the official submitted runs to DL on DL-HARD and find substantial differences in metrics and the ranking of participating systems. Overall, DL-HARD is a new resource that promotes research on neural ranking methods by focusing on challenging and complex topics.