 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Conditional Text-to-Image Synthesis Using Diffusion Models
Paper and Code
Nov 16, 2024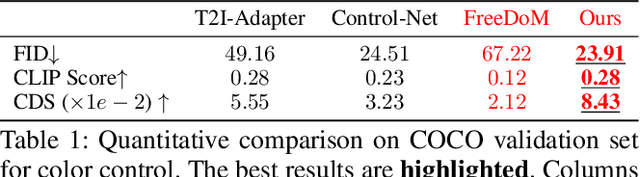
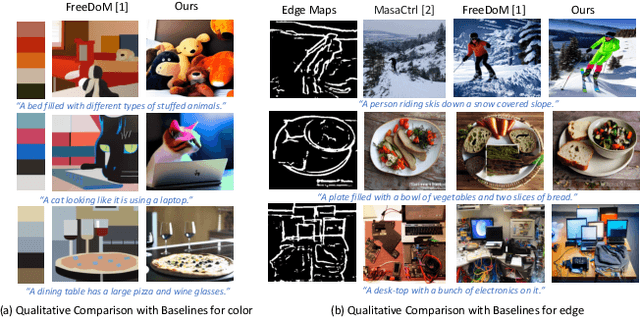
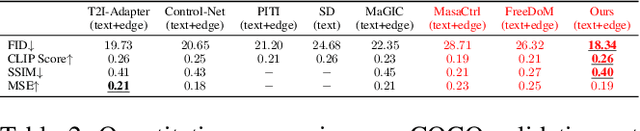
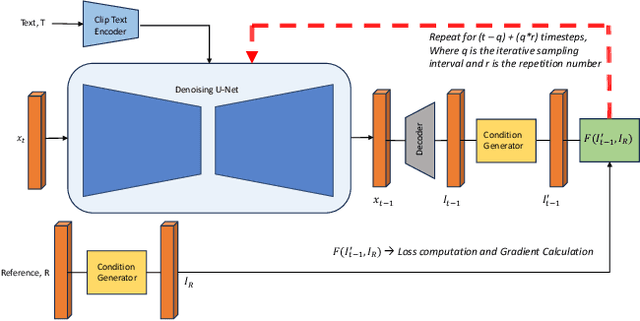
We consider the problem of conditional text-to-image synthesis with diffusion models. Most recent works need to either finetune specific parts of the base diffusion model or introduce new trainable parameters, leading to deployment inflexibility due to the need for training. To address this gap in the current literature, we propose our method called TINTIN: Test-time Conditional Text-to-Image Synthesis using Diffusion Models which is a new training-free test-time only algorithm to condition text-to-image diffusion model outputs on conditioning factors such as color palettes and edge maps. In particular, we propose to interpret noise predictions during denoising as gradients of an energy-based model, leading to a flexible approach to manipulate the noise by matching predictions inferred from them to the ground truth conditioning input. This results in, to the best of our knowledge, the first approach to control model outputs with input color palettes, which we realize using a novel color distribution matching loss. We also show this test-time noise manipulation can be easily extensible to other types of conditioning, e.g., edge maps. We conduct extensive experiments using a variety of text prompts, color palettes, and edge maps and demonstrate significant improvement over the current state-of-the-art, both qualitatively and quantitatively.